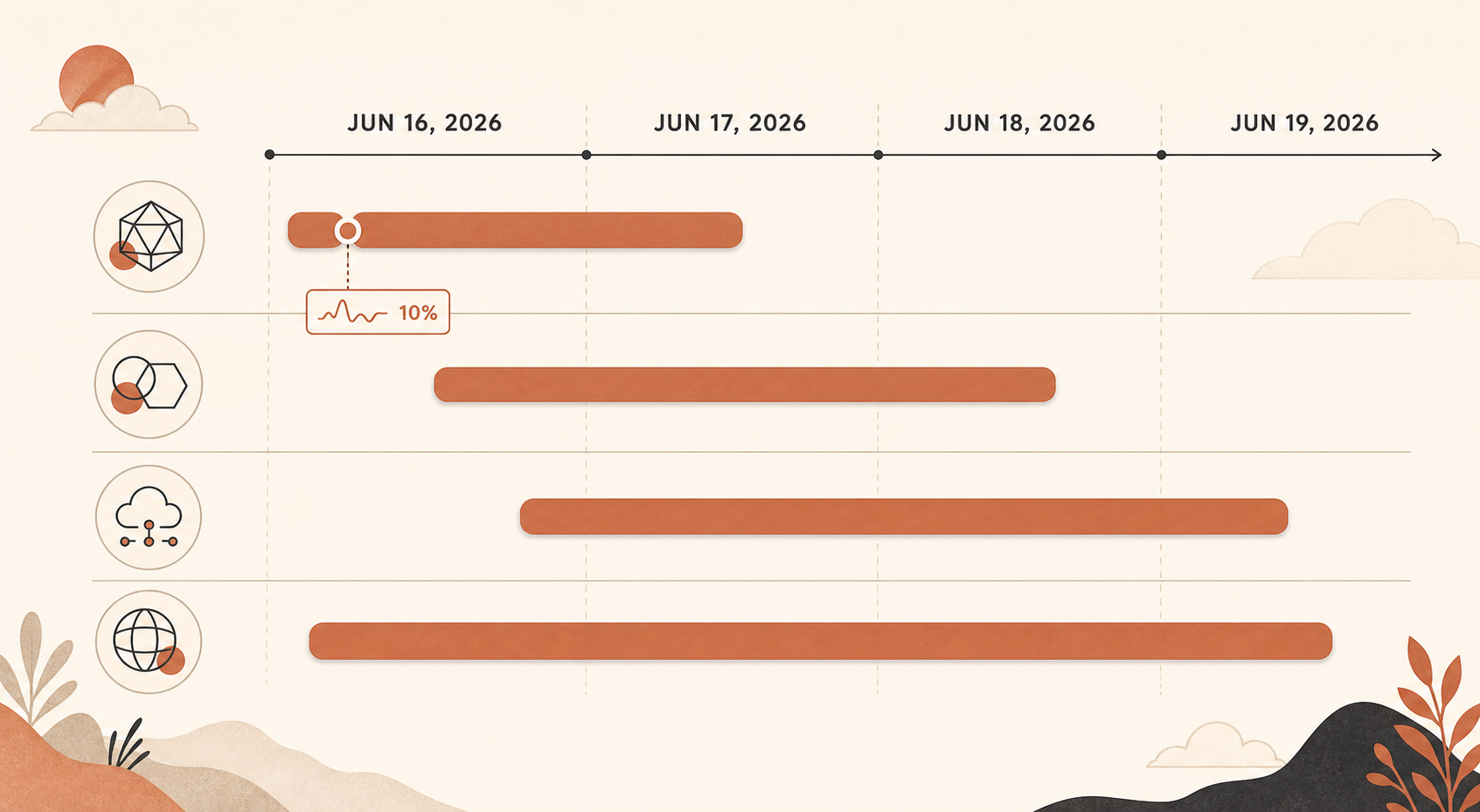
16 июня собственная статус‑страница Anthropic зафиксировала цифру, на которую продакшен‑инженерам стоит смотреть в первую очередь: все модели Sonnet и Opus примерно на 37 минут вышли на уровень ошибок около 10%, а затем Claude Opus 4.8 еще 80 минут держался в среднем на 10% ошибок (Claude Status). Если ваше приложение вызывает Claude внутри пользовательского сценария, это не раздражающее «попробуйте позже». Это повод пересмотреть архитектуру.
На этом инциденты не закончились. Claude Status показывает повторяющиеся сбои Opus 4.8 и более широкие инциденты сервиса Claude с 16 по 19 июня: три инцидента только с Opus 16 июня, еще четыре инцидента Opus/Sonnet или только Opus 17 июня, сбой сервисов Claude 18 июня и два инцидента API или Opus 4.8 19 июня (Claude Status). По состоянию на 20 июня страница сообщает, что сегодня инцидентов не было, но свежий паттерн и так достаточно понятен.
Anthropic выпустила Claude Opus 4.8 28 мая как апгрейд Opus 4.7 по той же цене, позиционируя его как более сильного напарника с лучшими результатами в бенчмарках и повышенной честностью (Anthropic). Все это может быть правдой. Но операционную реальность это не меняет: если Opus 4.8 стоит у вас на критическом пути, вашему приложению теперь нужен настоящий режим отказа.
Что произошло, в UTC
Важный инцидент начался 16 июня в 17:29 UTC, когда Claude Status открыл расследование повышенного числа ошибок во многих моделях. Позже Anthropic описала его в две фазы: с 17:23 до 18:00 UTC были затронуты все модели Sonnet и Opus, уровень ошибок доходил примерно до 10%; с 18:00 до 19:20 UTC уже один Opus 4.8 в среднем держался на 10% ошибок (Claude Status).
Потом пошли более мелкие, но все равно болезненные всплески Opus 4.8. 16 июня Claude Status отдельно зафиксировал ошибки Opus 4.8 примерно в 19:41–19:53 UTC и еще один инцидент Opus 4.8 с 20:45 до 20:58 UTC (Claude Status). 17 июня было несколько инцидентов Opus 4.8, включая один, где запросы получали повышенное число ошибок с 04:59 до 05:41 UTC, и еще один инцидент Sonnet 4.6 плюс Opus 4.8, где Sonnet восстановился первым, а Opus 4.8 все еще требовал работы (Claude Status).
18 июня проблема была шире: Claude Status сообщает, что сбой сервиса затронул сервисы Claude с 06:55 до 07:40 UTC (Claude Status). Затем 19 июня случился инцидент Opus 4.8 с 06:07 до 07:17 UTC и отдельный инцидент «повышенного уровня ошибок на Claude API» с 08:17 до 08:45 UTC (Claude Status).
Этот таймлайн важен, потому что это был не один аккуратный outage. Это был кластер. Один retry может спрятать 30‑секундный сбой. Но он не спасет продукт от повторяющейся нестабильности на уровне модели в течение нескольких дней.
Почему разработчики злятся
Тред на Hacker News про повышенные ошибки Claude выглядит ровно так, как ожидаешь от людей, которые перетащили AI из игрушечных промптов в ежедневный продакшен: раздражение, шутки и серьезный спор о риске зависимости (Hacker News).
Один лагерь видит в этом обычные болезни роста frontier‑моделей. GPU‑мощности — сложная штука, спрос скачет, обслуживать такие модели дорого. Другой лагерь менее снисходителен: если команды строят платные продукты и внутренние процессы вокруг Claude Code, Claude API и моделей класса Opus, то «повышенное число ошибок» — не безобидный эвфемизм. Это downtime, просто сформулированный приятнее.
Самые острые комментарии не просто про «Claude упал». Они про инверсию зависимости. Разработчики уже не просто используют API, чтобы обогатить фичу. Они строят процессы, где модель пишет код, ревьюит код, триажит тикеты, извлекает данные и отвечает клиентам. Один комментатор HN описал клиентские системы автоматизации, где uptime ограничен uptime’ом LLM‑провайдера, а затем перечислил практические решения: multi-provider fallback, async queues и graceful degradation (Hacker News).
Вот это и есть полезная часть общественного спора. Вопрос уже не в том, хорош ли Opus 4.8. Вопрос в том, считает ли ваша система его базой данных, кешем, flaky SaaS‑зависимостью или человеческим специалистом, который иногда недоступен.
Правильный ответ: flaky специалистом.
У бюджетов ретраев должен быть жесткий потолок
Документация Anthropic по ошибкам различает обычные некорректные запросы, лимиты аккаунта, внутренние ошибки API, таймауты и перегрузку. Ключевые коды здесь — 500 api_error, 504 timeout_error, 529 overloaded_error, а иногда и 429 rate_limit_error, если ваш собственный рост трафика уперся в лимиты. Anthropic говорит, что 529 означает временную перегрузку API и может возникать, когда APIs испытывают высокий трафик по всем пользователям (Claude Docs).
Не надо слепо ретраить все это одинаково. 400 из-за неподдерживаемого параметра — это ваш баг. Более того, Opus 4.8 наследует ограничения Opus 4.7: установка нестандартных temperature, top_p или top_k возвращает 400 в Messages API (Claude Docs). Ретраить такое — просто сжигать latency.
Для перегрузок и внутренних сбоев ретраи полезны только внутри бюджета. Пользовательский запрос с SLA в 6 секунд не должен 45 секунд вежливо долбиться в Opus 4.8. Дайте каждому запросу retry budget, а потом деградируйте.
Нормальный дефолт:
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}Конкретные цифры должны соответствовать вашему продукту. Coding agent может ждать дольше, чем ассистент в checkout. Фоновый пайплайн документов может ждать минуты. Voice agent — нет.
Главная мысль: ретраи — это не reliability. Ретраи — это мост либо к восстановлению, либо к fallback.
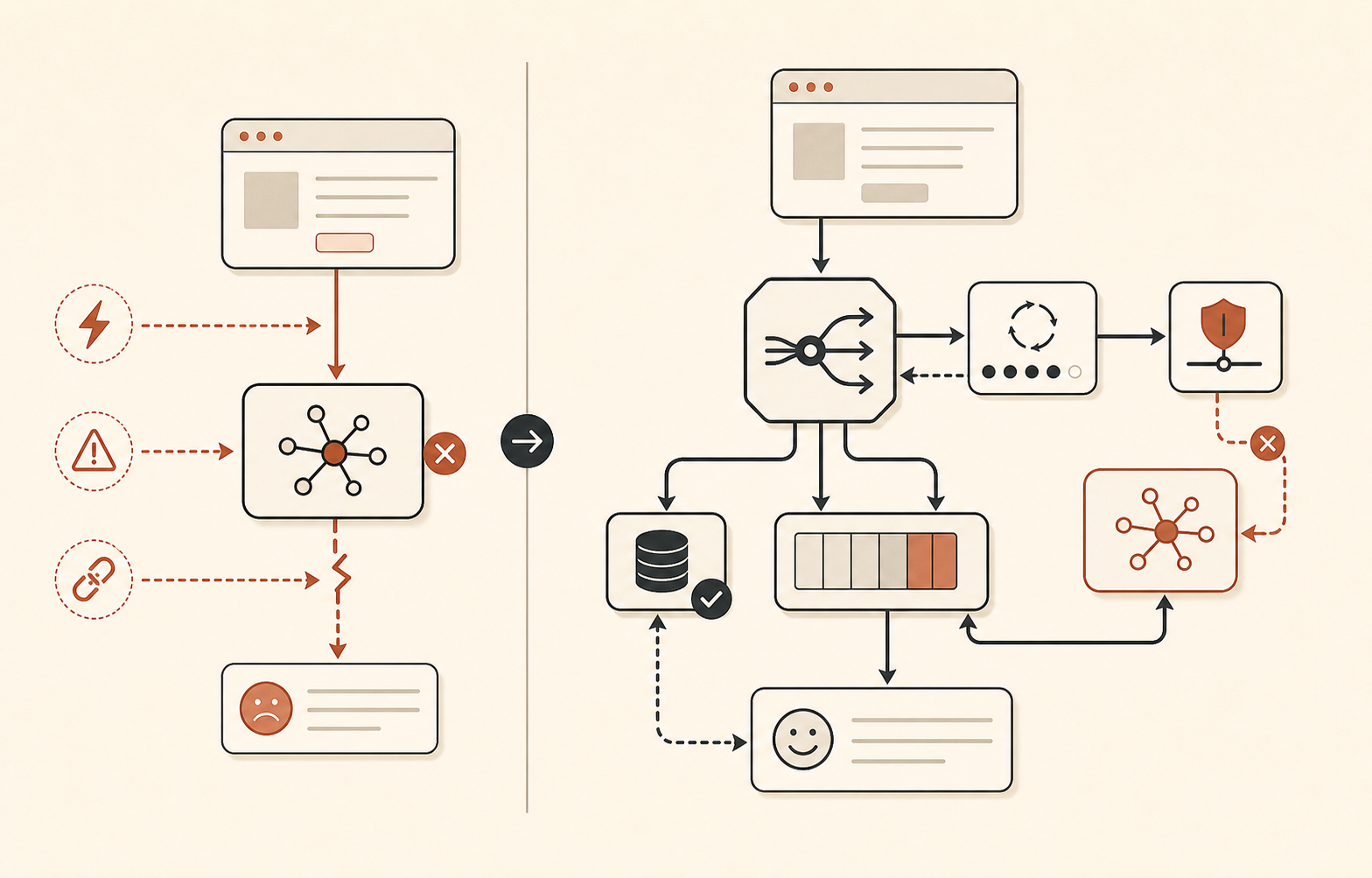
Fallback‑маршрутизация должна быть скучной
Инцидент 16 июня хорошо напоминает, что «переключимся на Sonnet» не всегда достаточно. В первой фазе были затронуты все модели Sonnet и Opus. Во второй фазе Opus 4.8 оставался нездоровым, пока Sonnet восстановился. 17 июня Claude Status также зафиксировал инцидент Sonnet 4.6 и Opus 4.8, где success rates Sonnet восстановились, а у Opus 4.8 все еще были повышенные ошибки (Claude Status).
Поэтому model fallback должен строиться по уровням, а не по ощущениям.
| Уровень | Когда использовать | Пример действия |
|---|---|---|
| Основной Opus-класс | Задачам с высоким reasoning нужно лучшее качество | Пробовать Opus 4.8 в строгом бюджете |
| Fallback Sonnet-класса | Opus‑специфичные ошибки или latency | Направить тот же prompt в Sonnet, если качество приемлемо |
| Non-Claude fallback | Инцидент Claude API или multi-model | Направить к другому провайдеру, меньшей модели или локальной/open модели |
| Продуктовый fallback | AI‑путь недоступен | Поставить работу в очередь, вернуть кешированный результат, передать человеку или показать деградированный UI |
Цена тоже должна участвовать в этом решении маршрутизации. Прайс‑лист Anthropic от 27 мая указывает Claude Opus 4.8 по $5 за миллион input tokens и $25 за миллион output tokens в глобальном standard pricing, Sonnet 4.6 — $3 и $15, а Haiku 4.5 — $1 и $5 в листингах Google Vertex AI (Anthropic price sheet). Значит, fallback — это не только инструмент uptime. Это инструмент контроля затрат.
Не деградируйте все задачи одинаково. Черновик юридического анализа, возможно, должен подождать, пока Opus вернется. Support chatbot может перейти на более дешевую модель и задать один уточняющий вопрос. Code assistant может сохранить workspace и сказать пользователю, что переключает модели, прежде чем вносить правки. Тихий fallback опасен, когда поведение модели заметно меняется.
Мониторьте статус‑страницу как входной сигнал
Claude Status предлагает на статус‑странице подписки по email, Slack, Microsoft Teams, webhook, Atom и RSS (Claude Status). Используйте их. Но не останавливайтесь на Slack‑канале, где алерты идут умирать.
Подавайте изменения статуса в свой LLM gateway. Если открывается инцидент Opus 4.8, снижайте threshold circuit breaker для Opus. Если открывается инцидент по всему Claude API, после первого быстрого failure прекращайте отправлять interactive traffic и переносите подходящие jobs в очередь. Если инцидент resolved, возвращайте traffic постепенно, а не устраивайте stampede на провайдера.
Circuit breaker должен отслеживать и вашу собственную telemetry:
- Error rate по provider, model, region и endpoint.
- P50, P95 и timeout rate для streaming и non-streaming calls.
- Retry attempts на successful response.
- Fallback rate и fallback quality score.
- User-visible failure rate, а не только API failure rate.
Последняя метрика — та, которую понимают executives. Если Opus 4.8 возвращает 10% ошибок, но ваш продукт дает полезные деградированные ответы для 99,5% пользовательских действий, у вас есть инцидент, но нет пожара у клиентов. Если ваш продукт висит, потому что каждый запрос блокируется на Opus, вы сами развели этот пожар.

Что стоит изменить на этой неделе
Во‑первых, уберите Opus 4.8 из всех single point of failure. Он все еще может быть вашей лучшей моделью. Он не должен быть единственным путем.
Во‑вторых, классифицируйте prompts по допустимости деградации. «Must use Opus» должно быть редким и явным. «Can use Sonnet» — распространенным. «Can queue» должно быть дефолтом для обработки документов, генерации отчетов, batch code review и неинтерактивного анализа.
В‑третьих, сделайте ретраи видимыми. Логируйте request_id, модель, status code, retry count, final outcome и fallback target. В документации Anthropic сказано, что API errors включают request IDs и что их стоит прикладывать к support requests (Claude Docs). Если во время инцидента вы не можете ответить на вопрос «какая модель упала и куда мы направили запрос дальше?», ваша observability не готова.
В‑четвертых, тестируйте fallback‑путь намеренно. Добавьте feature flag, который принудительно ломает Opus в staging. Проведите одночасовой game day, где каждый вызов Opus возвращает 529. Посмотрите, что ломается: assumptions в prompts, output parsers, eval thresholds, UI copy, customer promises. Почините это до следующего настоящего инцидента.
И наконец, будьте честны с пользователями. «AI сломался» — плохой UX. «Мы запускаем это в стандартном режиме, потому что advanced model временно деградировала» — намного лучше. Для некоторых продуктов такая фраза укрепит доверие.
Инциденты 16–19 июня не доказывают, что Claude Opus 4.8 — плохая модель. Они доказывают, что frontier‑модели теперь являются продакшен‑зависимостями с нестабильными характеристиками доступности. Относитесь к ним как к платежным процессорам, поисковым индексам и cloud regions: полезным, дорогим и абсолютно способным испортить вам день, если подключить их без fallback.
Читатели, которые хотят сами попробовать Claude Fable 5, могут использовать его через OneHop как drop-in endpoint, примерно на 30% ниже list price. Новые аккаунты получают $10 бесплатно без карты: Claude Fable 5 on OneHop или начать с $10 бесплатно.
Дополнительно: Начало работы с Claude Fable 5.

