2026 年 5 月 28 日,Anthropic 推出 Claude Opus 4.8,帶來三個比模型名稱更重要、面向開發者的變化:Claude Code 加入動態工作流程,使用者可以選擇 effort level,而 Opus 快速模式變快 2.5 倍,價格為每百萬輸入 token 10 美元、每百萬輸出 token 50 美元;Anthropic 表示,這比先前 Opus 模型的快速模式便宜三倍(Anthropic)。
這才是真正的重點。標題不是「Claude 又在某張圖表上擊敗 GPT」。標題是 Anthropic 正試著把 coding agents 從單一聊天框裡搬出來。
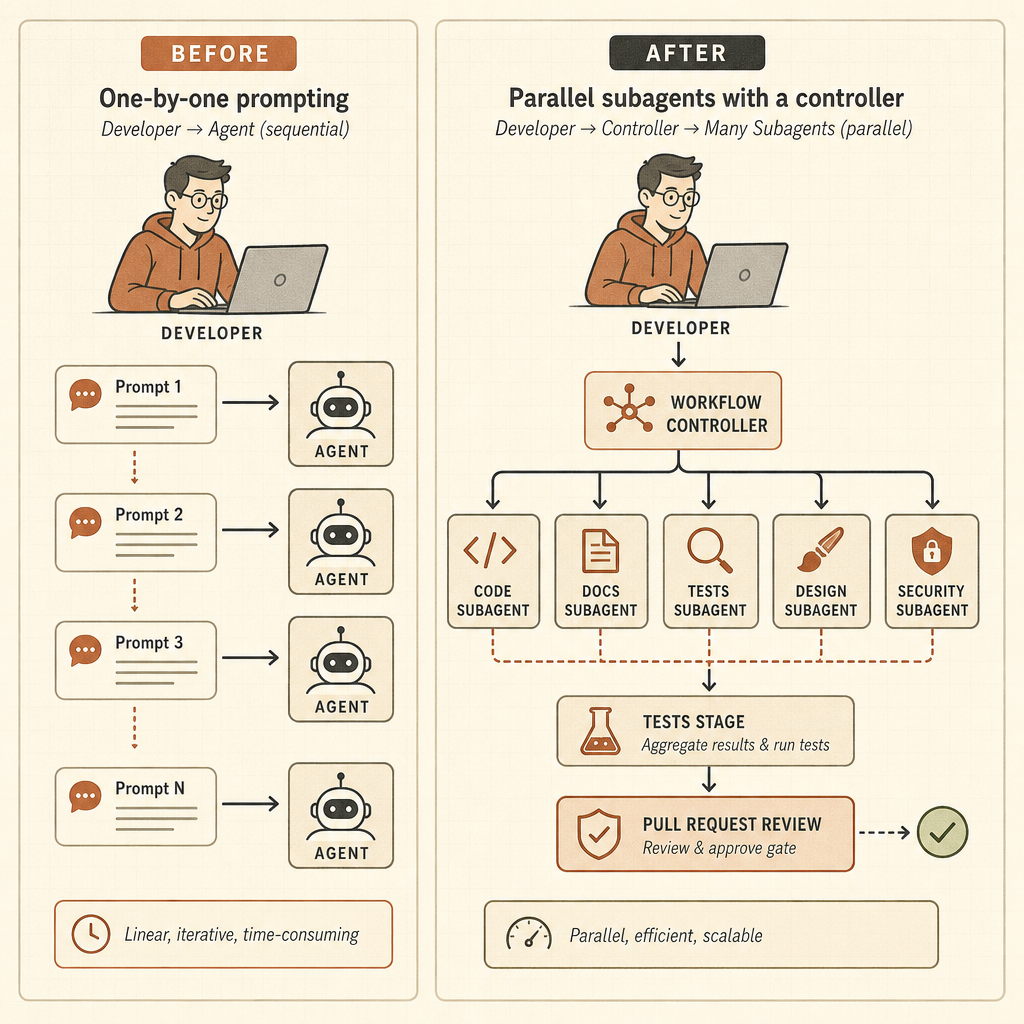
舊迴圈很簡單:下 prompt、等待、檢查 diff、再下 prompt。Opus 4.8 指向的是另一種迴圈:交付一個目標,讓系統把工作拆給 subagents,把狀態留在主對話之外,驗證結果,最後帶著協調好的答案回來。這會把開發者的工作,從 prompt writer 變成 agent operator。
Benchmark 的提升是真的,但它不是護城河
Opus 4.8 比 Opus 4.7 更強。Anthropic 表示,它在 coding、agentic 技能、推理與專業工作上都有進步,一般 API 價格維持不變:每百萬輸入 token 5 美元、每百萬輸出 token 25 美元(Anthropic)。公司也說,這個模型讓自己程式碼裡的缺陷未經提示就放過的機率,大約比 Opus 4.7 低四倍。
system card 的數字把定位講得很清楚。根據已發布的 Anthropic Opus 4.8 system card 數據摘要,在 SWE-bench Pro 上,Opus 4.8 回報為 69.2%,高於 Opus 4.7 的 64.3%、GPT-5.5 的 58.6%,以及 Gemini 3.1 Pro 的 54.2%(Vellum、Anthropic system card PDF)。但在 Terminal-Bench 2.1 上,故事就沒那麼乾淨:同樣使用 Terminus-2 harness,GPT-5.5 以 78.2% 領先,而 Opus 4.8 是 74.6%。Anthropic 也指出,GPT-5.5 回報的 Codex CLI harness 分數是 83.4%;這是個有用的提醒:agent benchmarks 測的是模型加上 harness,而不是罐子裡的純智力(Anthropic)。
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | Anthropic 表中未提供 | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE with tools | 57.9% | 54.7% | 52.2% | 51.4% |
要像工程師一樣讀那張表,不要像粉絲。Opus 4.8 是一次有分量的發布。但它也不是乾淨俐落的 KO。OpenAI 圍繞 GPT-5.5 仍然有可信的 terminal-agent 敘事;OpenAI 在 4 月發布模型時,就是以 agentic AI 與真實世界工作來包裝它(OpenAI)。Google 在 2026 年 2 月 19 日發布的 Gemini 3.1 Pro,也被定位為更強推理能力,並廣泛進入 Google 各種介面(Google)。
那為什麼 Opus 4.8 在策略上感覺不一樣?因為 Anthropic 賣的不是只有模型,而是操作模式。
動態工作流程把 Claude Code 變成 Runtime
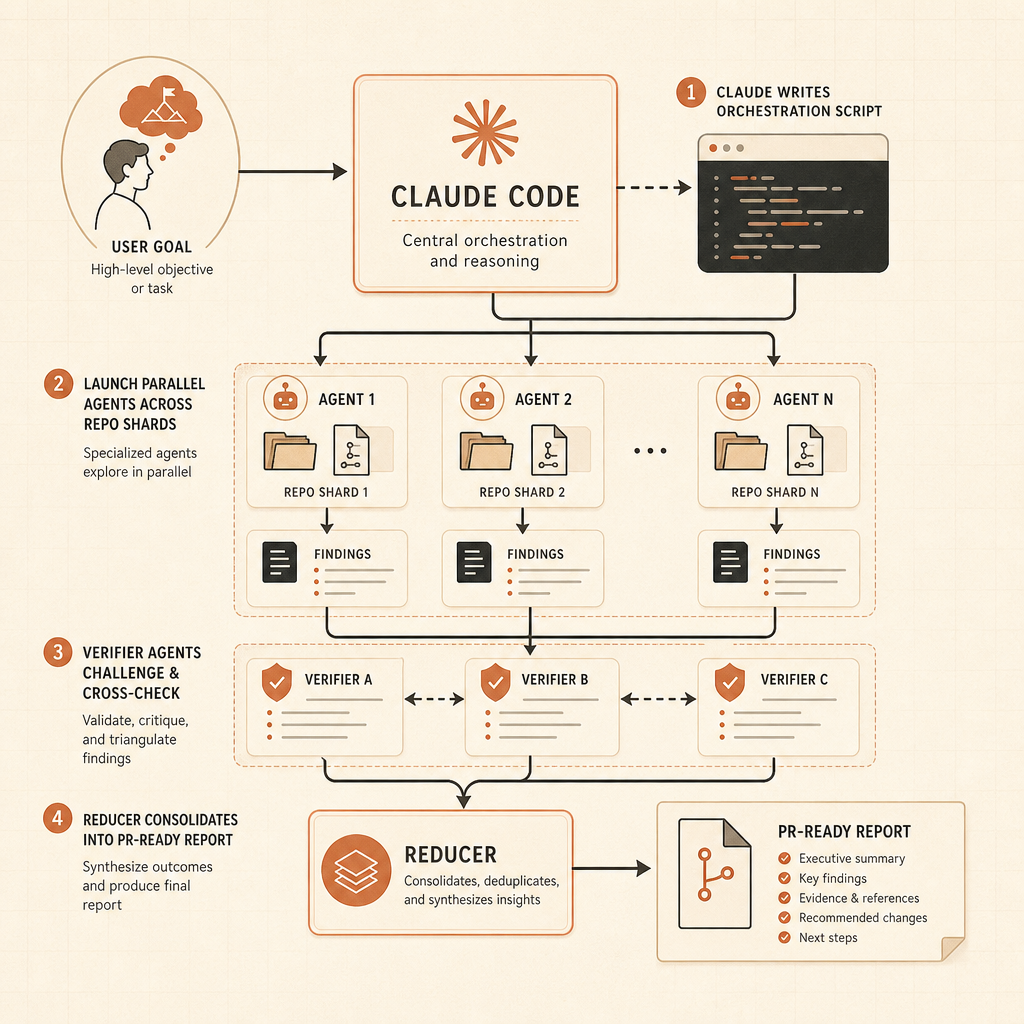
動態工作流程是這次發布最鋒利的部分。Anthropic 的 Claude Code 文章說,Claude 可以撰寫 orchestration scripts,在同一個 session 裡跑「數十到數百個」並行 subagents,檢查它們的工作,並回傳協調過的結果(Claude)。那些例子不是玩具 prompt:整個 codebase 的 bug hunt、由 profiler 引導的最佳化稽核、安全稽核、大型 migration、現代化工程,以及 adversarial review。
Bun 的例子,是開發者會記住的那種說法。Anthropic 表示,Jarred Sumner 使用動態工作流程,把 Bun 從 Zig port 到 Rust,既有 test suite 有 99.8% 通過,產出約 750,000 行 Rust,從第一次 commit 到 merge 花了十一天(Claude)。這不代表每個團隊都能把 legacy monolith 丟給 Claude 然後去吃午餐。它代表的是,Anthropic 明確在為超出單一 context window、單一 agent trace 的工作做設計。
現在合理的 prompt 看起來不像「修這個 bug」,比較像是給內部自動化系統的一份工作規格:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.這是另一種技能。開發者必須定義範圍、預算、權限、驗證關卡與 rollback 行為。好用的心智模型不再是 pair programming,而是在管理一支小型、快速、能力不均、永不睡覺,而且有時會誤解 ticket 的工程團隊。
Effort Levels 讓 Compute 變成產品旋鈕
effort selector 很容易被低估。Anthropic 表示 Opus 4.8 預設為 high effort;使用者可以在 Claude Code 中選擇「extra」或 xhigh,也可以選 max,而較高 effort 會花更多 token 換取更好結果(Anthropic)。Claude API 文件把 xhigh 描述為適合進階 coding 與複雜 agentic work,包含重複 tool calls 與細緻搜尋;同時也釐清 Claude Code 的 ultracode 不是一個獨立的 API effort level。它把 xhigh 與啟動 multi-agent workflows 的權限配在一起(Anthropic Docs)。
這是 Anthropic 承認一件開發者早就用昂貴方式學到的事:「best model」是錯誤抽象。正確問題是:這個任務應該買多少搜尋、工具使用、驗證與並行能力?
修 typo 不該跑一百個 agents。跨 service 的 auth migration 也許需要。flaky test 調查可能很適合並行假設。UI 文案修改則不需要。
快速模式符合同一個論點。標準 Opus 4.8 價格維持每百萬 token 5/25 美元,而快速模式是 10/50 美元,速度快 2.5 倍(Anthropic)。這不是「便宜 Claude」。這是 latency premium。Anthropic 把先前快速模式的溢價砍到足夠低,讓團隊可以開始把速度視為營運決策,而不是奢侈設定。
與 OpenAI 和 Gemini 的比較,重點在介面
OpenAI、Google 與 Anthropic 都在追逐 frontier model 分數。沒有人能退出這場競賽。買家還是會問誰在 SWE-bench、GPQA、HLE、OSWorld 與內部 evals 領先。採購簡報還是需要一張圖表。
但開發者工具之爭,正在從「哪個模型回答最好?」轉向「哪個環境能讓模型安全地持續工作?」
OpenAI 的 Codex-style 定位,在 terminal execution、repository interaction 與 harnessed coding work 上很強。GPT-5.5 的 Terminal-Bench 優勢是在警告 Anthropic:對低階 terminal reliability 來說,周邊 CLI 與 execution harness 可以勝過原始 benchmark 差距。Google 的優勢是 distribution。Gemini 模型會進入 Gemini app、AI Studio、Vertex AI、Workspace 形狀的介面,以及 Android-adjacent workflows。這讓 Gemini 即使在 coding chart 輸給競品時,也很難被忽視。
Anthropic 的答案更窄,也更有主張:Claude Code 應該成為長時間工程工作被規劃、展開、檢查、恢復與 review 的地方。Opus 頁面把該模型描述為為嚴肅 coding 與 AI agents 而打造,具備 1M context window,並可在 Claude Platform、AWS、Google Cloud 與 Microsoft Foundry 使用(Anthropic)。動態工作流程把這件事從模型行銷推進到產品架構。

開發者工作流程會有四個實際變化
第一,規劃變得更重要。動態工作流程會放大最初的指令。模糊的 prompt 會浪費更多 token、碰更多檔案,製造更大的爛攤子。最好的使用者會寫出邊界明確的 tickets:哪些目錄在範圍內、要跑哪些 tests、哪些 APIs 不能改,以及 done 的定義。
第二,驗證變成一等公民的 artifact。Anthropic 說 workflows 可以使用獨立嘗試與 adversarial agents,在使用者看到結果之前先嘗試打破它(Claude)。這是正確模式。Agent output 應該帶著證據抵達:test logs、grep results、benchmark deltas,以及尚未解決的風險。
第三,成本從看不見的背景噪音變成架構問題。動態工作流程可能消耗遠高於典型 Claude Code session 的用量,而 Anthropic 明確建議先從範圍受限的任務開始(Claude)。團隊會需要內規:什麼時候用 high effort、什麼時候用 xhigh、什麼時候允許 workflows,以及什麼時候必須先做人工 design review。
第四,資深工程師的角色往上移。少花時間手動檢查每一個 reference。多花時間設計 harness:repo maps、test commands、permission modes、branch strategy、CI gates 與 review prompts。最好的 AI coding setups 會看起來像小型內部平台,而不是聰明 prompt 集合。
Anthropic 的押注:Agent Manager 會贏
Opus 4.8 是一次好的模型發布。更有意思的發布,是它周圍的 control plane。
Anthropic 押注的是:頂尖實驗室之間的 frontier intelligence 會接近到足以讓開發者忠誠度來自 orchestration:系統分解工作的能力、並行執行 agents 的能力、管理 context 的能力、要求確認的能力、驗證主張的能力,以及暴露足夠狀態讓人類信任它的能力。Benchmarks 仍然重要。它們決定誰能進入評估名單。Workflows 決定誰能留在日常迴圈裡。
這個押注是對的。開發者生產力的下一次跳躍,不會來自要求單一 agent 在單一回合裡再聰明一點。它會來自給能力足夠的模型一個符合真實工程工作方式的 runtime:並行調查、分階段實作、獨立 review、tests 與 rollback。
Opus 4.8 是 Anthropic 把潛台詞說出口。模型競賽還在繼續,但產品競賽已經移到 agent orchestration。
想親自試用 Claude Fable 5 的讀者,可以透過 Claude Fable 5 on OneHop 使用,這是一個 drop-in endpoint,價格約比定價低 30%。新帳號可以先拿 $10 免費額度,不用綁卡。

