28 Mayıs 2026’da Anthropic, Claude Opus 4.8’i model adından daha önemli üç geliştirici odaklı değişiklikle çıkardı: Claude Code dinamik iş akışları kazandı, kullanıcılar seçilebilir efor seviyelerine kavuştu ve Opus hızlı modu 2,5 kat hızlanırken fiyatı milyon girdi token’ı başına 10 dolar, milyon çıktı token’ı başına 50 dolar oldu; Anthropic bunun önceki Opus modellerindeki hızlı moddan üç kat daha ucuz olduğunu söylüyor (Anthropic).
Asıl hikâye bu. Manşet “Claude başka bir grafikte GPT’yi geçti” değil. Manşet şu: Anthropic kodlama ajanlarını tek sohbet kutusundan çıkarmaya çalışıyor.
Eski döngü basitti: prompt yaz, bekle, diff’i incele, tekrar prompt yaz. Opus 4.8 başka bir döngüyü işaret ediyor: bir hedef ver, sistem işi alt ajanlara bölsün, durumu ana konuşmanın dışında tutsun, sonuçları doğrulasın, sonra koordineli bir yanıtla geri gelsin. Bu, geliştiricinin işini prompt yazarlığından ajan operatörlüğüne çeviriyor.
Benchmark Sıçraması Gerçek, Ama Hendek O Değil
Opus 4.8, Opus 4.7’den daha güçlü. Anthropic; kodlama, ajansal beceriler, akıl yürütme ve profesyonel işlerde geliştiğini, normal API fiyatlandırmasının ise milyon girdi token’ı başına 5 dolar ve milyon çıktı token’ı başına 25 dolar olarak değişmediğini söylüyor (Anthropic). Şirket ayrıca modelin, kendi kodundaki kusurları yorum yapmadan geçirme olasılığının Opus 4.7’ye göre yaklaşık dört kat daha düşük olduğunu söylüyor.
Sistem kartı rakamları konumlandırmayı netleştiriyor. Anthropic’in Opus 4.8 sistem kartı verilerinin yayımlanmış özetlerine göre SWE-bench Pro’da Opus 4.8 %69,2 ile raporlanıyor; Opus 4.7 %64,3, GPT-5.5 %58,6 ve Gemini 3.1 Pro %54,2’de kalıyor (Vellum, Anthropic system card PDF). Terminal-Bench 2.1’de hikâye daha dağınık: aynı Terminus-2 düzeneğinde GPT-5.5 %78,2 ile önde, Opus 4.8 ise %74,6’da. Anthropic ayrıca GPT-5.5’in raporlanan Codex CLI düzeneği skorunun %83,4 olduğunu belirtiyor; bu da ajan benchmark’larının kavanozdaki saf zekâyı değil, modeli artı düzeneği ölçtüğünü hatırlatan faydalı bir not (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | Anthropic tablosunda yok | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| Araçlarla HLE | 57.9% | 54.7% | 52.2% | 51.4% |
O tabloyu hayran gibi değil, mühendis gibi okuyun. Opus 4.8 anlamlı bir sürüm. Ama temiz bir nakavt da değil. OpenAI’nin GPT-5.5 etrafında hâlâ inandırıcı bir terminal-ajan hikâyesi var; OpenAI modeli Nisan’da çıkarırken bunu ajansal AI ve gerçek dünya işleri etrafında çerçevelemişti (OpenAI). Google’ın 19 Şubat 2026’da çıkan Gemini 3.1 Pro’su da daha güçlü akıl yürütme ve Google yüzeylerinde geniş erişilebilirlik etrafında konumlandırılmıştı (Google).
Peki Opus 4.8 neden stratejik olarak farklı hissettiriyor? Çünkü Anthropic sadece modeli değil, çalışma modelini satıyor.
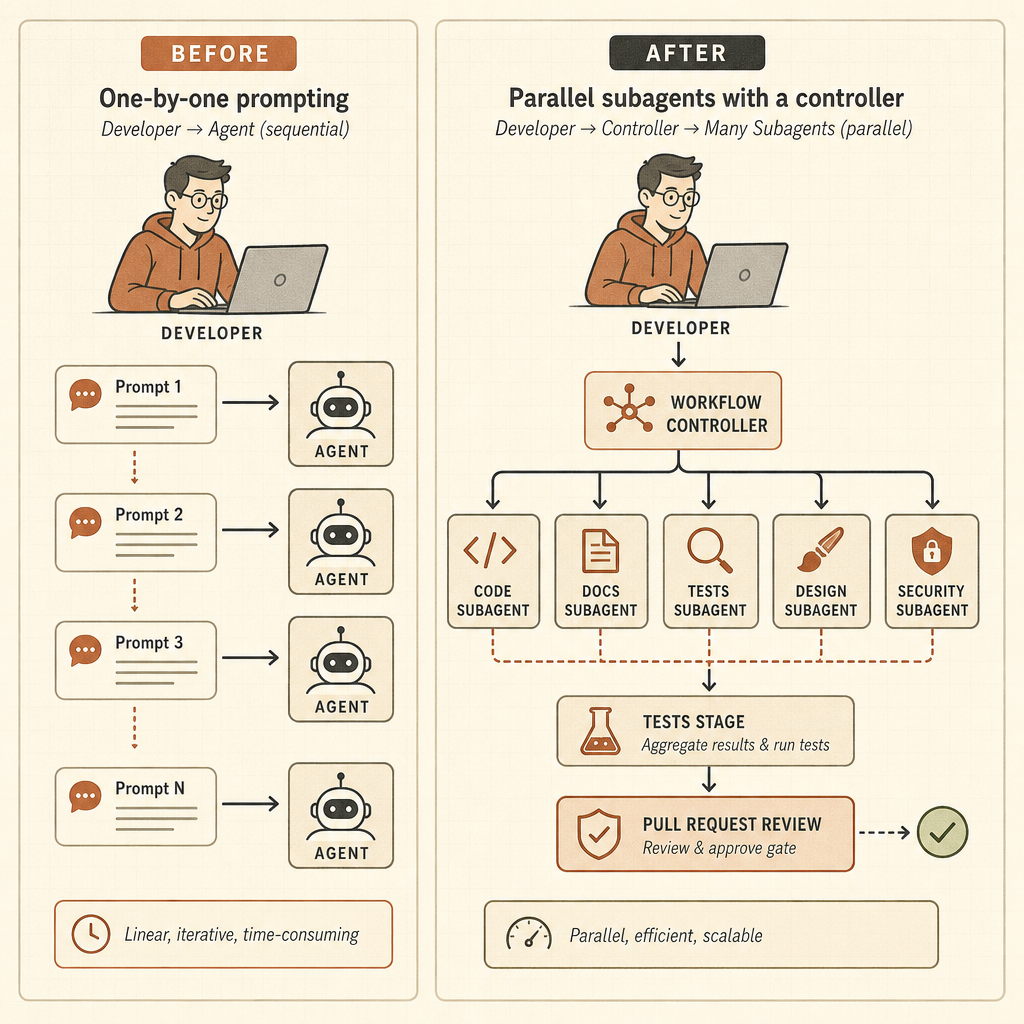
Dinamik İş Akışları Claude Code’u Bir Runtime’a Çeviriyor
Dinamik iş akışları bu lansmanın keskin ucu. Anthropic’in Claude Code yazısı, Claude’un tek bir oturumda “onlarca ila yüzlerce” paralel alt ajan çalıştıran orkestrasyon script’leri yazabildiğini, bunların işini kontrol edip koordineli bir sonuç döndürebildiğini söylüyor (Claude). Örnekler oyuncak prompt’lar değil: tüm kod tabanında hata avları, profiler yönlendirmeli optimizasyon denetimleri, güvenlik denetimleri, büyük migrasyonlar, modernizasyon işleri ve karşıt inceleme.
Bun örneği geliştiricilerin hatırlayacağı türden bir iddia. Anthropic, Jarred Sumner’ın dinamik iş akışlarını kullanarak Bun’ı Zig’den Rust’a taşıdığını; mevcut test paketinin %99,8’inin geçtiğini, yaklaşık 750.000 satır Rust çıktığını ve ilk commit’ten merge’e on bir gün sürdüğünü söylüyor (Claude). Bu, her ekibin eski bir monoliti Claude’a atıp öğle yemeğine çıkabileceği anlamına gelmiyor. Ama Anthropic’in, tek bir context window’a ve tek bir ajan izine sığmayan işler için açıkça tasarım yaptığını gösteriyor.
Makul bir prompt artık “bu hatayı düzelt”ten çok, iç otomasyon sistemi için yazılmış bir iş tanımına benziyor:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.Bu başka bir beceri. Geliştiricinin kapsamı, bütçeleri, izinleri, doğrulama kapılarını ve geri alma davranışını tanımlaması gerekiyor. Artık işe yarayan zihinsel model pair programming değil. Hiç uyumayan, hızlı, dengesiz ve bazen bileti yanlış anlayan küçük bir mühendislik ekibini yönetmek.
Efor Seviyeleri Compute’u Bir Ürün Ayarına Çeviriyor
Efor seçiciyi hafife almak kolay. Anthropic, Opus 4.8’in varsayılan olarak yüksek eforda çalıştığını; kullanıcıların Claude Code’da “extra” veya xhigh, ayrıca max seçebildiğini, daha yüksek eforun daha iyi sonuçlar için daha fazla token harcadığını söylüyor (Anthropic). Claude API dokümanları, xhigh seviyesini tekrarlı araç çağrıları ve ayrıntılı arama içeren ileri seviye kodlama ve karmaşık ajansal işler için uygun olarak tanımlıyor; Claude Code’un ultracode değerinin ayrı bir API efor seviyesi olmadığını da netleştiriyor. xhigh seviyesini çok ajanlı iş akışları başlatma izniyle eşleştiriyor (Anthropic Docs).
Bu, Anthropic’in geliştiricilerin pahalı yoldan zaten öğrendiği bir şeyi kabul etmesi: “en iyi model” yanlış soyutlama. Doğru soru şu: bu görev ne kadar arama, araç kullanımı, doğrulama ve paralellik satın almalı?
Bir yazım hatası düzeltmesi yüz ajan çalıştırmamalı. Servisler arası bir auth migrasyonu buna ihtiyaç duyabilir. Flaky test incelemesi paralel hipotezler için mükemmel olabilir. UI metin değişikliği değildir.
Hızlı mod da aynı teze uyuyor. Standart Opus 4.8 fiyatı milyon token başına 5/25 dolar olarak değişmezken, hızlı mod 10/50 dolar ve 2,5 kat hızda çalışıyor (Anthropic). Bu “ucuz Claude” değil. Bu bir gecikme primi. Anthropic önceki hızlı mod primini yeterince düşürdü; ekipler artık hızı lüks bir ayar yerine operasyonel bir karar olarak ele almaya başlayabilir.
OpenAI ve Gemini ile Karşılaştırma Yüzeylerle İlgili
OpenAI, Google ve Anthropic’in hepsi frontier model skorlarının peşinde. Kimse bu yarıştan çıkamıyor. Alıcılar hâlâ SWE-bench, GPQA, HLE, OSWorld ve iç eval’larda kimin önde olduğunu soruyor. Satın alma sunumlarının hâlâ bir grafiğe ihtiyacı var.
Ama geliştirici araçları yarışı “hangi model en iyi cevaplıyor?”dan “hangi ortam modelin güvenli şekilde çalışmaya devam etmesine izin veriyor?”a kayıyor.
OpenAI’nin Codex tarzı konumlandırması terminal çalıştırma, repository etkileşimi ve düzeneğe bağlı kodlama işleri etrafında güçlü. GPT-5.5’in Terminal-Bench avantajı Anthropic için bir uyarı: düşük seviye terminal güvenilirliğinde, çevredeki CLI ve çalıştırma düzeneği ham benchmark farklarını yenebilir. Google’ın avantajı dağıtım. Gemini modelleri Gemini uygulamasına, AI Studio’ya, Vertex AI’a, Workspace biçimli yüzeylere ve Android’e komşu iş akışlarına giriyor. Bu, rakip model bir kodlama grafiğini kazansa bile Gemini’yi görmezden gelmeyi zorlaştırıyor.
Anthropic’in cevabı daha dar ve daha görüşlü: Claude Code, uzun süre çalışan mühendislik işlerinin planlandığı, kollara ayrıldığı, kontrol edildiği, sürdürüldüğü ve incelendiği yer olmalı. Opus sayfası modeli ciddi kodlama ve AI ajanları için inşa edilmiş olarak tanımlıyor; 1M context window’a sahip olduğunu ve Claude Platform, AWS, Google Cloud ve Microsoft Foundry genelinde erişilebilir olduğunu söylüyor (Anthropic). Dinamik iş akışları bunu model pazarlamasından ürün mimarisine taşıyor.

Geliştirici İş Akışı Dört Pratik Şekilde Değişiyor
Birincisi, planlama daha önemli hâle geliyor. Dinamik iş akışı ilk talimatı büyütür. Belirsiz bir prompt daha fazla token yakabilir, daha fazla dosyaya dokunabilir ve daha büyük bir karmaşa üretebilir. En iyi kullanıcılar açık sınırları olan biletler yazacak: kapsam içindeki dizinler, çalıştırılacak testler, değişmemesi gereken API’ler ve tamam tanımları.
İkincisi, doğrulama birinci sınıf bir çıktı hâline geliyor. Anthropic, iş akışlarının kullanıcı sonucu görmeden önce bağımsız denemeler ve karşıt ajanlar kullanarak sonucu kırmaya çalışabileceğini söylüyor (Claude). Doğru desen bu. Ajan çıktısı kanıtla gelmeli: test log’ları, grep sonuçları, benchmark farkları ve çözülmemiş riskler.
Üçüncüsü, maliyet görünmez arka plan gürültüsünden mimariye taşınıyor. Dinamik iş akışları tipik bir Claude Code oturumundan ciddi ölçüde daha fazla kullanım tüketebilir ve Anthropic açıkça kapsamı belirlenmiş görevlerle başlamayı öneriyor (Claude). Ekiplerin ev kurallarına ihtiyacı olacak: ne zaman yüksek efor kullanılacak, ne zaman xhigh, ne zaman iş akışlarına izin verilecek ve ne zaman önce insan tasarım incelemesi zorunlu tutulacak.
Dördüncüsü, kıdemli mühendisin rolü yukarı kayıyor. Her referansı elle kontrol etmeye daha az zaman. Düzeneği tasarlamaya daha fazla zaman: repo haritaları, test komutları, izin modları, branch stratejisi, CI kapıları ve inceleme prompt’ları. En iyi AI kodlama kurulumları akıllı prompt koleksiyonlarına değil, küçük iç platformlara benzeyecek.
Anthropic’in Bahsi: Ajan Yöneticisi Kazanır
Opus 4.8 iyi bir model sürümü. Daha ilginç sürüm, etrafındaki kontrol düzlemi.
Anthropic’in bahsi şu: frontier zekâ en üst laboratuvarlar arasında yeterince yakın olacak ve geliştirici sadakati orkestrasyondan gelecek; sistem işi ne kadar iyi parçalıyor, ajanları paralel çalıştırıyor, bağlamı yönetiyor, onay istiyor, iddiaları doğruluyor ve insanların güvenebileceği kadar durum gösteriyor? Benchmark’lar hâlâ önemli. Değerlendirmeye kimin gireceğine onlar karar veriyor. Günlük döngüde kimin kalacağına ise iş akışları karar veriyor.
Bu doğru bahis. Geliştirici verimliliğindeki bir sonraki sıçrama, tek bir ajandan tek bir turda biraz daha akıllı olmasını istemekten gelmeyecek. Yetenekli modellere gerçek mühendislik işinin nasıl aktığını karşılayan bir runtime vermekten gelecek: paralel araştırma, aşamalı uygulama, bağımsız inceleme, testler ve geri alma.
Opus 4.8, Anthropic’in herkesin bildiği şeyi yüksek sesle söylemesi. Model yarışı sürüyor, ama ürün yarışı ajan orkestrasyonuna taşındı.
Claude Fable 5’i kendisi denemek isteyen okurlar, liste fiyatının yaklaşık %30 altında fiyatlanan drop-in endpoint olan Claude Fable 5 on OneHop üzerinden kullanabilir. Yeni hesaplar, kart gerektirmeden $10 free ile başlayabilir.
Ek okuma: Claude Fable 5 ile başlarken.

