Am 28. Mai 2026 veröffentlichte Anthropic Claude Opus 4.8 mit drei Änderungen für Entwickler, die wichtiger sind als der Modellname: Claude Code bekam dynamische Workflows, Nutzer erhielten auswählbare Effort-Stufen, und der Opus Fast Mode wurde 2,5× schneller, bei einem Preis von 10 US-Dollar pro Million Input-Tokens und 50 US-Dollar pro Million Output-Tokens. Laut Anthropic ist das dreimal günstiger als der Fast Mode früherer Opus-Modelle (Anthropic).
Das ist die eigentliche Geschichte. Die Schlagzeile lautet nicht: „Claude schlägt GPT in noch einem Diagramm.“ Die Schlagzeile lautet: Anthropic versucht, Coding-Agenten aus der Einzelchat-Kiste herauszuholen.
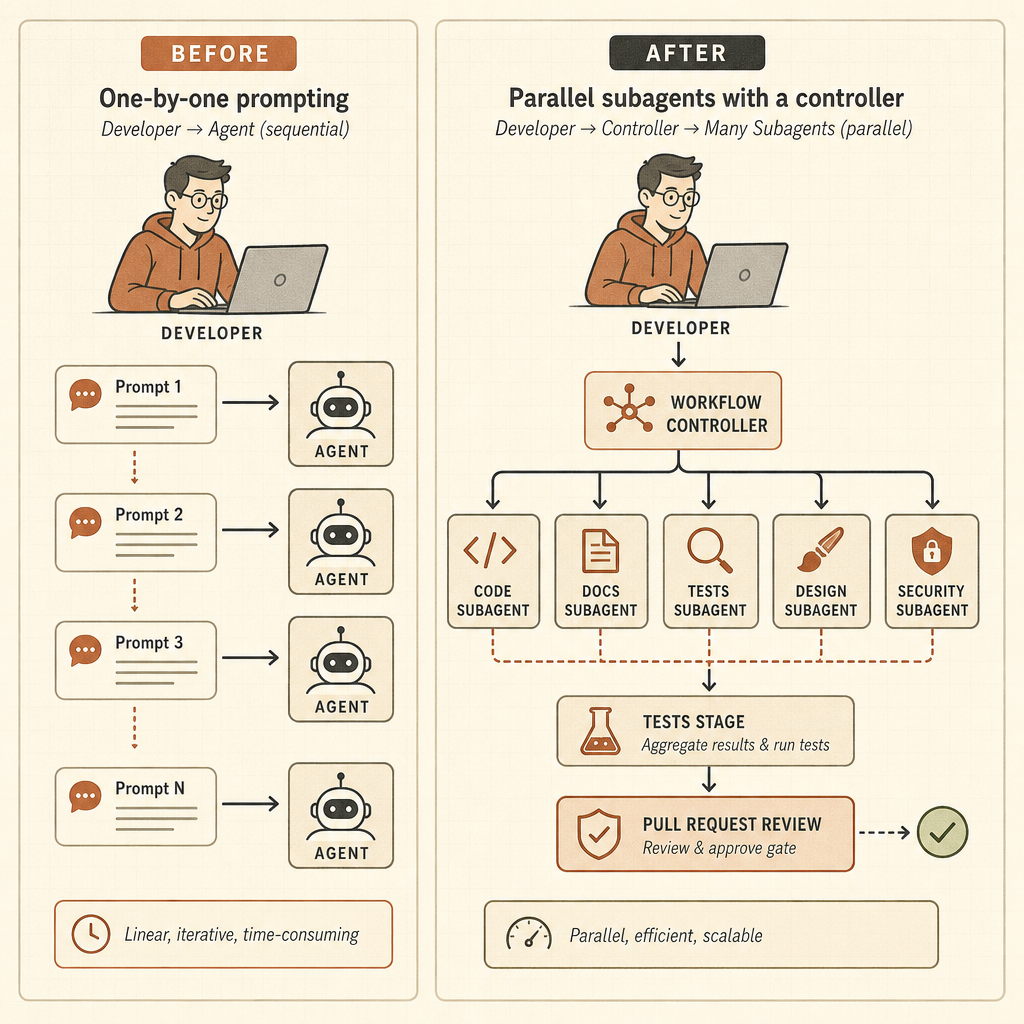
Die alte Schleife war simpel: prompten, warten, Diff prüfen, erneut prompten. Opus 4.8 zeigt auf eine andere Schleife: Ziel vergeben, das System Arbeit auf Subagenten aufteilen lassen, Zustand außerhalb der Hauptkonversation halten, Ergebnisse verifizieren und dann mit einer koordinierten Antwort zurückkommen. Damit verschiebt sich der Job des Entwicklers vom Prompt-Schreiber zum Agent-Operator.
Der Benchmark-Sprung ist real, aber er ist nicht der Schutzgraben
Opus 4.8 ist stärker als Opus 4.7. Anthropic sagt, es verbessere sich bei Coding, agentischen Fähigkeiten, Reasoning und professioneller Arbeit, während die regulären API-Preise unverändert bei 5 US-Dollar pro Million Input-Tokens und 25 US-Dollar pro Million Output-Tokens bleiben (Anthropic). Das Unternehmen sagt außerdem, das Modell lasse etwa viermal seltener als Opus 4.7 Fehler im eigenen Code kommentarlos durchgehen.
Die Zahlen aus der System Card machen die Positionierung klar. Auf SWE-bench Pro wird Opus 4.8 mit 69,2% angegeben, vor Opus 4.7 mit 64,3%, GPT-5.5 mit 58,6% und Gemini 3.1 Pro mit 54,2%, laut veröffentlichten Zusammenfassungen der Daten aus Anthropic’s Opus-4.8-System-Card (Vellum, Anthropic system card PDF). Auf Terminal-Bench 2.1 ist die Geschichte weniger sauber: GPT-5.5 führt auf demselben Terminus-2-Harness mit 78,2%, während Opus 4.8 bei 74,6% landet. Anthropic weist außerdem darauf hin, dass GPT-5.5s gemeldeter Codex-CLI-Harness-Score bei 83,4% liegt — eine nützliche Erinnerung daran, dass Agent-Benchmarks das Modell plus Harness messen, nicht reine Intelligenz im Glas (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | n. a. in Anthropic-Tabelle | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE mit Tools | 57.9% | 54.7% | 52.2% | 51.4% |
Lies diese Tabelle wie ein Ingenieur, nicht wie ein Fan. Opus 4.8 ist ein relevantes Release. Es ist aber kein klarer Knockout. OpenAI hat rund um GPT-5.5 weiterhin eine glaubwürdige Terminal-Agent-Story, die OpenAI beim Launch des Modells im April um agentische AI und reale Arbeit herum positionierte (OpenAI). Googles Gemini 3.1 Pro, veröffentlicht am 19. Februar 2026, wurde ebenfalls über stärkeres Reasoning und breite Verfügbarkeit über Google-Oberflächen hinweg positioniert (Google).
Warum fühlt sich Opus 4.8 strategisch also anders an? Weil Anthropic das Betriebsmodell verkauft, nicht nur das Modell.
Dynamische Workflows machen Claude Code zur Runtime
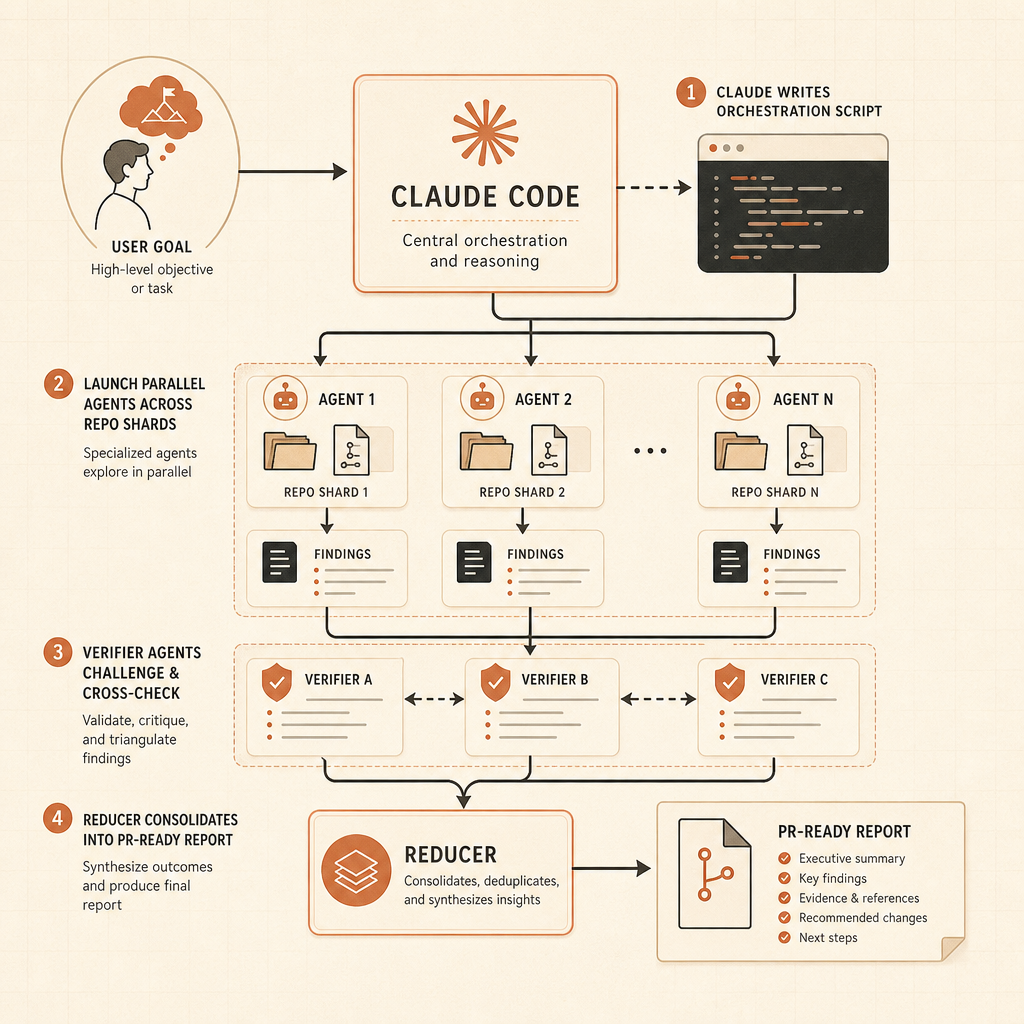
Dynamische Workflows sind die scharfe Kante dieses Launches. Anthropic’s Claude-Code-Beitrag sagt, Claude könne Orchestrierungsskripte schreiben, die in einer Sitzung „Dutzende bis Hunderte“ parallele Subagenten ausführen, deren Arbeit prüfen und ein koordiniertes Ergebnis zurückgeben (Claude). Die Beispiele sind keine Spielzeug-Prompts: Bug-Jagden über ganze Codebasen, profilergeführte Optimierungs-Audits, Security-Audits, große Migrationen, Modernisierungsarbeiten und adversarische Reviews.
Das Bun-Beispiel ist die Art Behauptung, die Entwickler im Kopf behalten werden. Anthropic sagt, Jarred Sumner habe dynamische Workflows genutzt, um Bun von Zig nach Rust zu portieren, wobei 99,8% der bestehenden Testsuite bestanden, rund 750.000 Zeilen Rust entstanden und zwischen erstem Commit und Merge elf Tage lagen (Claude). Das heißt nicht, dass jedes Team Claude einen Legacy-Monolithen hinwerfen und Mittag essen gehen kann. Es heißt aber, dass Anthropic ausdrücklich für Arbeit designt, die über ein Kontextfenster und eine Agent-Spur hinauswächst.
Ein vernünftiger Prompt sieht jetzt weniger aus wie „fix diesen Bug“ und mehr wie eine Jobbeschreibung für ein internes Automatisierungssystem:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.Das ist eine andere Fähigkeit. Der Entwickler muss Scope, Budgets, Berechtigungen, Verifikations-Gates und Rollback-Verhalten definieren. Das nützliche mentale Modell ist nicht mehr Pair Programming. Es ist das Management eines kleinen, schnellen, unausgeglichenen Engineering-Teams, das nie schläft und manchmal das Ticket falsch versteht.
Effort-Stufen machen Compute zum Produktregler
Der Effort-Selector wird leicht unterschätzt. Anthropic sagt, Opus 4.8 sei standardmäßig auf High Effort eingestellt; Nutzer können in Claude Code „extra“ oder xhigh wählen, außerdem max, wobei höherer Effort mehr Tokens für bessere Ergebnisse ausgibt (Anthropic). Die Claude-API-Dokumentation beschreibt xhigh als passend für fortgeschrittenes Coding und komplexe agentische Arbeit mit wiederholten Tool-Aufrufen und detaillierter Suche, stellt aber klar, dass Claude Codes ultracode keine separate API-Effort-Stufe ist. xhigh wird dort mit der Erlaubnis gekoppelt, Multi-Agent-Workflows zu starten (Anthropic Docs).
Damit gibt Anthropic etwas zu, was Entwickler längst auf die teure Art gelernt haben: „bestes Modell“ ist die falsche Abstraktion. Die richtige Frage lautet: Wie viel Suche, Tool-Nutzung, Verifikation und Parallelität soll diese Aufgabe einkaufen?
Ein Tippfehler-Fix sollte keine hundert Agenten starten. Eine Auth-Migration über mehrere Services hinweg vielleicht schon. Eine Untersuchung flaky Tests kann perfekt für parallele Hypothesen sein. Eine UI-Textänderung ist es nicht.
Fast Mode passt zur selben These. Der Standardpreis von Opus 4.8 bleibt unverändert bei 5/25 US-Dollar pro Million Tokens, während Fast Mode 10/50 US-Dollar kostet und mit 2,5× Geschwindigkeit läuft (Anthropic). Das ist nicht „billiger Claude“. Es ist ein Latenzaufschlag. Anthropic hat den früheren Fast-Mode-Aufpreis weit genug gesenkt, dass Teams Geschwindigkeit als operative Entscheidung behandeln können statt als Luxus-Schalter.
Der Vergleich mit OpenAI und Gemini dreht sich um Oberflächen
OpenAI, Google und Anthropic jagen alle Frontier-Modell-Scores. Niemand kann aus diesem Rennen aussteigen. Käufer fragen weiterhin, wer bei SWE-bench, GPQA, HLE, OSWorld und internen Evals führt. Procurement-Decks brauchen weiterhin ein Diagramm.
Aber das Rennen um Entwickler-Tools verschiebt sich von „welches Modell antwortet am besten?“ zu „welche Umgebung lässt das Modell sicher weiterarbeiten?“
OpenAIs Codex-artige Positionierung ist stark bei Terminal-Ausführung, Repository-Interaktion und geharnesster Coding-Arbeit. GPT-5.5s Vorsprung bei Terminal-Bench ist eine Warnung an Anthropic: Bei Low-Level-Terminal-Zuverlässigkeit können die umgebende CLI und das Execution-Harness rohe Benchmark-Deltas schlagen. Googles Vorteil ist Distribution. Gemini-Modelle landen in der Gemini-App, in AI Studio, Vertex AI, Workspace-förmigen Oberflächen und Android-nahen Workflows. Das macht Gemini schwer zu ignorieren, selbst wenn ein Konkurrenzmodell ein Coding-Diagramm gewinnt.
Anthropic’s Antwort ist enger und eigensinniger: Claude Code soll der Ort werden, an dem langlebige Engineering-Arbeit geplant, aufgefächert, geprüft, fortgesetzt und reviewed wird. Die Opus-Seite beschreibt das Modell als gebaut für ernsthaftes Coding und AI-Agenten, mit einem 1M-Kontextfenster und Verfügbarkeit über Claude Platform, AWS, Google Cloud und Microsoft Foundry (Anthropic). Dynamische Workflows schieben das von Modellmarketing in Produktarchitektur.

Der Entwickler-Workflow verändert sich auf vier praktische Arten
Erstens wird Planung wichtiger. Ein dynamischer Workflow verstärkt die anfängliche Anweisung. Ein vager Prompt kann mehr Tokens verbrennen, mehr Dateien anfassen und ein größeres Chaos erzeugen. Die besten Nutzer werden Tickets mit klaren Grenzen schreiben: Verzeichnisse im Scope, auszuführende Tests, APIs, die sich nicht ändern dürfen, und Definitionen von „fertig“.
Zweitens wird Verifikation zu einem Artefakt erster Klasse. Anthropic sagt, Workflows könnten unabhängige Versuche und adversarische Agenten nutzen, um ein Ergebnis zu brechen, bevor der Nutzer es sieht (Claude). Das ist das richtige Muster. Agent-Output sollte mit Belegen kommen: Test-Logs, Grep-Ergebnisse, Benchmark-Deltas und ungelöste Risiken.
Drittens wandern Kosten von unsichtbarem Hintergrundrauschen in die Architektur. Dynamische Workflows können deutlich mehr Nutzung verbrauchen als eine typische Claude-Code-Sitzung, und Anthropic empfiehlt ausdrücklich, mit eng umrissenen Aufgaben zu beginnen (Claude). Teams brauchen Hausregeln: wann High Effort genutzt wird, wann xhigh, wann Workflows erlaubt sind und wann zuerst ein menschliches Design-Review Pflicht ist.
Viertens verschiebt sich die Rolle des Senior Engineers nach oben. Weniger Zeit damit, jede Referenz manuell zu prüfen. Mehr Zeit damit, das Harness zu entwerfen: Repo-Karten, Testbefehle, Berechtigungsmodi, Branch-Strategie, CI-Gates und Review-Prompts. Die besten AI-Coding-Setups werden wie kleine interne Plattformen aussehen, nicht wie clevere Prompt-Sammlungen.
Anthropic’s Wette: Der Agent-Manager gewinnt
Opus 4.8 ist ein gutes Modell-Release. Das interessantere Release ist die Kontrollschicht drumherum.
Anthropic wettet darauf, dass Frontier-Intelligenz unter den Top-Labs nah genug beieinanderliegen wird, dass Entwicklerloyalität aus Orchestrierung entsteht: wie gut das System Arbeit zerlegt, Agenten parallel laufen lässt, Kontext verwaltet, nach Bestätigung fragt, Behauptungen verifiziert und genug Zustand offenlegt, damit Menschen ihm vertrauen. Benchmarks zählen weiterhin. Sie entscheiden, wer in die Evaluation kommt. Workflows entscheiden, wer im täglichen Loop bleibt.
Das ist die richtige Wette. Der nächste Sprung in Entwicklerproduktivität wird nicht daher kommen, dass ein einzelner Agent in einem einzelnen Turn ein bisschen schlauer wird. Er wird daher kommen, dass fähige Modelle eine Runtime bekommen, die dazu passt, wie echte Engineering-Arbeit abläuft: parallele Untersuchung, gestufte Implementierung, unabhängiges Review, Tests und Rollback.
Opus 4.8 ist Anthropic, das den leisen Teil laut ausspricht. Das Modellrennen geht weiter, aber das Produktrennen ist zur Agent-Orchestrierung weitergezogen.
Leser, die Claude Fable 5 selbst ausprobieren wollen, können es über Claude Fable 5 on OneHop nutzen, einen Drop-in-Endpunkt mit einem Preis von etwa 30% unter Liste. Neue Accounts können mit 10 US-Dollar gratis starten, ohne Kreditkarte.
Weiterlesen: Erste Schritte mit Claude Fable 5.

