في 28 مايو 2026، أطلقت Anthropic نموذج Claude Opus 4.8 مع ثلاثة تغييرات موجّهة للمطورين أهم من اسم النموذج نفسه: حصل Claude Code على سير عمل ديناميكي، وصار بإمكان المستخدمين اختيار مستويات الجهد، وأصبح وضع Opus السريع أسرع بـ 2.5× مع تسعير قدره 10 دولارات لكل مليون رمز إدخال و50 دولارًا لكل مليون رمز إخراج، وهو ما تقول Anthropic إنه أرخص بثلاث مرات من الوضع السريع في نماذج Opus السابقة (Anthropic).
هذه هي القصة الحقيقية. العنوان ليس: “Claude هزم GPT في رسم بياني جديد.” العنوان هو أن Anthropic تحاول إخراج وكلاء البرمجة من صندوق المحادثة الواحدة.
كانت الحلقة القديمة بسيطة: اكتب الطلب، انتظر، افحص الفرق، ثم اكتب طلبًا آخر. Opus 4.8 يشير إلى حلقة مختلفة: حدّد هدفًا، دع النظام يقسّم العمل على وكلاء فرعيين، أبقِ الحالة خارج المحادثة الرئيسية، تحقّق من النتائج، ثم عد بإجابة منسّقة. هذا يغيّر وظيفة المطور من كاتب مطالبات إلى مشغّل وكلاء.
قفزة المعايير حقيقية، لكنها ليست الخندق الدفاعي
Opus 4.8 أقوى من Opus 4.7. تقول Anthropic إنه يتحسن في البرمجة، والمهارات الوكيلة، والاستدلال، والعمل المهني، مع بقاء تسعير API العادي كما هو عند 5 دولارات لكل مليون رمز إدخال و25 دولارًا لكل مليون رمز إخراج (Anthropic). وتقول الشركة أيضًا إن احتمال أن يمرّر النموذج عيوبًا في كوده دون تعليق أقل بنحو أربع مرات مقارنة بـ Opus 4.7.
أرقام بطاقة النظام توضّح التموضع. في SWE-bench Pro، يُسجَّل Opus 4.8 عند 69.2%، متقدمًا على Opus 4.7 عند 64.3%، وGPT-5.5 عند 58.6%، وGemini 3.1 Pro عند 54.2%، وفق ملخصات منشورة لبيانات بطاقة نظام Opus 4.8 من Anthropic (Vellum, Anthropic system card PDF). في Terminal-Bench 2.1، القصة أقل نظافة: يتصدر GPT-5.5 على حزمة Terminus-2 نفسها عند 78.2%، بينما يصل Opus 4.8 إلى 74.6%. وتشير Anthropic أيضًا إلى أن نتيجة GPT-5.5 المعلنة على حزمة Codex CLI هي 83.4%، وهذا تذكير مفيد بأن معايير الوكلاء تقيس النموذج زائد الحزمة التشغيلية، لا ذكاءً خالصًا داخل قارورة (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | n/a in Anthropic table | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE with tools | 57.9% | 54.7% | 52.2% | 51.4% |
اقرأ هذا الجدول كمهندس، لا كمشجع. Opus 4.8 إصدار مهم. لكنه ليس ضربة قاضية نظيفة. لا تزال OpenAI تملك قصة مقنعة لوكلاء الطرفية حول GPT-5.5، وقد قدّمت OpenAI النموذج عند إطلاقه في أبريل بوصفه متمحورًا حول الذكاء الاصطناعي الوكيلي والعمل الواقعي (OpenAI). أما Gemini 3.1 Pro من Google، الذي صدر في 19 فبراير 2026، فقد وُضع أيضًا حول استدلال أقوى وتوفر واسع عبر أسطح Google (Google).
إذًا لماذا يبدو Opus 4.8 مختلفًا استراتيجيًا؟ لأن Anthropic تبيع نموذج التشغيل، لا النموذج فقط.
سير العمل الديناميكي يحوّل Claude Code إلى بيئة تشغيل
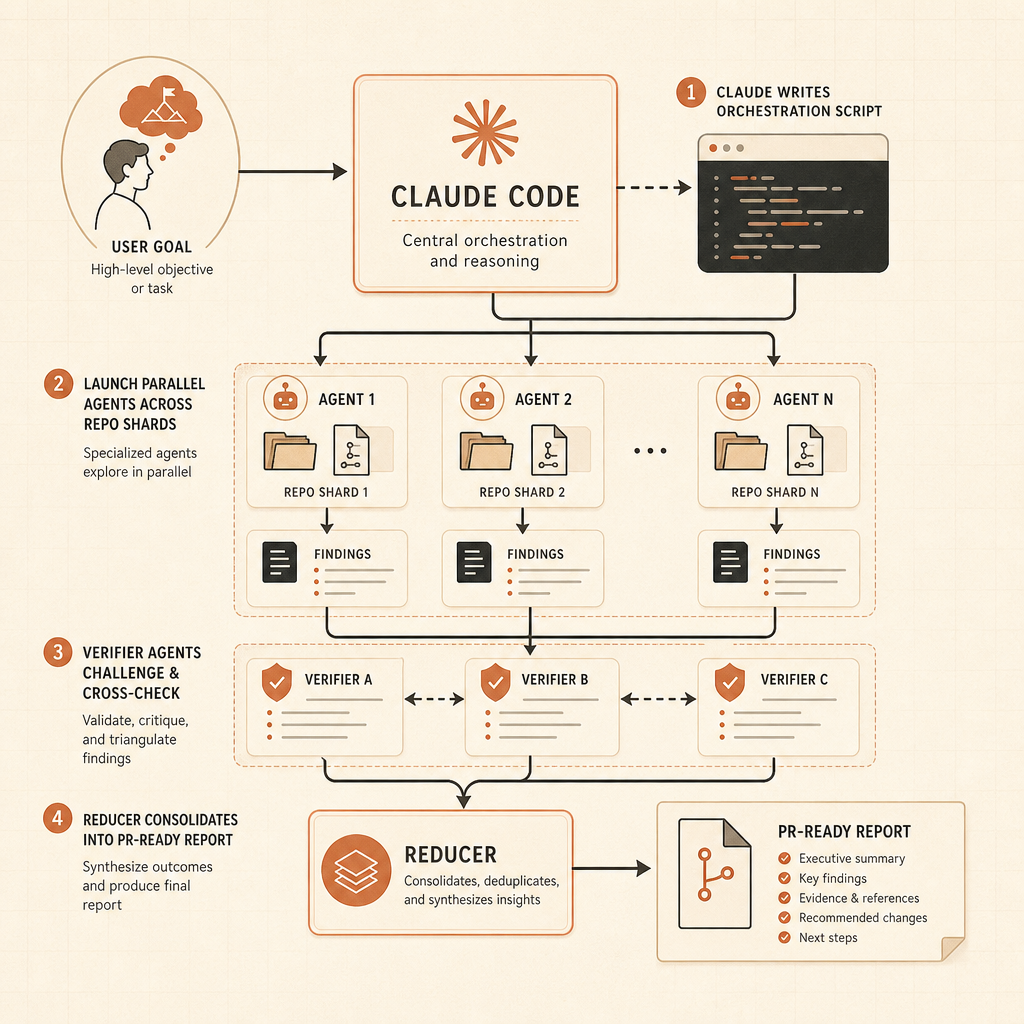
سير العمل الديناميكي هو الحافة الحادة في هذا الإطلاق. تقول تدوينة Claude Code من Anthropic إن Claude يستطيع كتابة سكربتات تنسيق تشغّل “عشرات إلى مئات” الوكلاء الفرعيين بالتوازي في جلسة واحدة، وتفحص عملهم، ثم تعيد نتيجة منسّقة (Claude). الأمثلة ليست مطالبات لعب: البحث عن أخطاء على مستوى قاعدة كود كاملة، تدقيقات تحسين موجهة بالبروفايلر، تدقيقات أمنية، هجرات كبيرة، أعمال تحديث، ومراجعة عدائية.
مثال Bun هو النوع الذي سيتذكره المطورون. تقول Anthropic إن Jarred Sumner استخدم سير العمل الديناميكي لنقل Bun من Zig إلى Rust مع نجاح 99.8% من حزمة الاختبارات الحالية، ونحو 750,000 سطر Rust، وأحد عشر يومًا من أول commit حتى الدمج (Claude). هذا لا يعني أن كل فريق يستطيع رمي مونوليث قديم على Claude والذهاب للغداء. لكنه يعني أن Anthropic تصمم صراحةً لعمل يتجاوز نافذة سياق واحدة وأثر وكيل واحد.
المطالبة المعقولة الآن تبدو أقل مثل “أصلح هذا الخطأ” وأكثر مثل مواصفة وظيفة لنظام أتمتة داخلي:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.هذه مهارة مختلفة. على المطور أن يحدد النطاق، والميزانيات، والصلاحيات، وبوابات التحقق، وسلوك التراجع. النموذج الذهني المفيد لم يعد البرمجة الزوجية. إنه إدارة فريق هندسي صغير وسريع وغير متكافئ لا ينام أبدًا ويسيء فهم التذكرة أحيانًا.
مستويات الجهد تجعل الحوسبة مقبضًا في المنتج
من السهل التقليل من شأن محدد الجهد. تقول Anthropic إن Opus 4.8 يعمل افتراضيًا بجهد عالٍ؛ ويمكن للمستخدمين اختيار “extra” أو xhigh في Claude Code، إضافة إلى max، حيث ينفق الجهد الأعلى رموزًا أكثر مقابل نتائج أفضل (Anthropic). وتصف وثائق Claude API مستوى xhigh بأنه مناسب للبرمجة المتقدمة والعمل الوكيلي المعقد مع استدعاءات أدوات متكررة وبحث مفصل، مع توضيح أن ultracode في Claude Code ليس مستوى جهد API منفصلًا. كما تقرن xhigh بإذن إطلاق سير عمل متعدد الوكلاء (Anthropic Docs).
هذه طريقة Anthropic في الاعتراف بشيء تعلّمه المطورون بالطريقة المكلفة: “أفضل نموذج” تجريد خاطئ. السؤال الصحيح هو: كم من البحث، واستخدام الأدوات، والتحقق، والتوازي ينبغي أن تشتريه هذه المهمة؟
إصلاح خطأ مطبعي لا ينبغي أن يشغّل مئة وكيل. هجرة مصادقة عابرة للخدمات قد تحتاجهم. تحقيق في اختبار متذبذب قد يكون مثاليًا لفرضيات متوازية. تغيير نص في واجهة المستخدم ليس كذلك.
الوضع السريع ينسجم مع الأطروحة نفسها. سعر Opus 4.8 القياسي لم يتغير عند 5/25 دولارًا لكل مليون رمز، بينما الوضع السريع بسعر 10/50 دولارًا ويعمل بسرعة 2.5× (Anthropic). هذا ليس “Claude رخيصًا.” إنها علاوة زمن استجابة. خفّضت Anthropic علاوة الوضع السريع السابقة بما يكفي ليبدأ الفرق في التعامل مع السرعة كقرار تشغيلي بدلًا من إعداد رفاهي.
المقارنة مع OpenAI وGemini تدور حول أسطح العمل
OpenAI وGoogle وAnthropic جميعها تطارد أرقام نماذج الطليعة. لا أحد يستطيع الانسحاب من هذا السباق. لا يزال المشترون يسألون: من يتصدر SWE-bench وGPQA وHLE وOSWorld والتقييمات الداخلية؟ ولا تزال عروض المشتريات تحتاج إلى رسم بياني.
لكن سباق أدوات المطورين ينتقل من “أي نموذج يجيب أفضل؟” إلى “أي بيئة تسمح للنموذج بمواصلة العمل بأمان؟”
تموضع OpenAI بأسلوب Codex قوي في تنفيذ الطرفية، والتفاعل مع المستودعات، وأعمال البرمجة ضمن حزم تشغيل. تفوق GPT-5.5 في Terminal-Bench تحذير لـ Anthropic: في موثوقية الطرفية منخفضة المستوى، يمكن لـ CLI والحزمة التنفيذية المحيطة أن تتغلب على فروق المعايير الخام. أما ميزة Google فهي التوزيع. نماذج Gemini تصل عبر تطبيق Gemini، وAI Studio، وVertex AI، وأسطح شبيهة بـ Workspace، وتدفقات قريبة من Android. هذا يجعل Gemini صعب التجاهل حتى حين يفوز نموذج منافس في مخطط برمجة.
إجابة Anthropic أضيق وأكثر رأيًا: يجب أن يصبح Claude Code المكان الذي يُخطط فيه العمل الهندسي طويل الأمد، ويُوزع، ويُفحص، ويُستأنف، ويُراجع. تصف صفحة Opus النموذج بأنه مبني للبرمجة الجادة ووكلاء الذكاء الاصطناعي، مع نافذة سياق 1M وتوفر عبر Claude Platform وAWS وGoogle Cloud وMicrosoft Foundry (Anthropic). يدفع سير العمل الديناميكي هذا من تسويق النموذج إلى معمارية المنتج.

يتغير سير عمل المطور بأربع طرق عملية
أولًا، يصبح التخطيط أهم. سير العمل الديناميكي يضخّم التعليمة الأولى. المطالبة الغامضة قد تهدر رموزًا أكثر، وتمس ملفات أكثر، وتنتج فوضى أكبر. أفضل المستخدمين سيكتبون تذاكر بحدود صريحة: المجلدات داخل النطاق، الاختبارات المطلوب تشغيلها، واجهات API التي يجب ألا تتغير، وتعريفات الإنجاز.
ثانيًا، يصبح التحقق أثرًا من الدرجة الأولى. تقول Anthropic إن سير العمل يستطيع استخدام محاولات مستقلة ووكلاء عدائيين لكسر النتيجة قبل أن يراها المستخدم (Claude). هذا هو النمط الصحيح. ينبغي أن يصل ناتج الوكيل ومعه دليل: سجلات اختبارات، نتائج grep، فروق معايير، ومخاطر غير محسومة.
ثالثًا، تنتقل التكلفة من ضجيج خلفي غير مرئي إلى معمارية. يمكن لسير العمل الديناميكي أن يستهلك استخدامًا أكبر بكثير من جلسة Claude Code نموذجية، وتوصي Anthropic صراحةً بالبدء بمهام محددة النطاق (Claude). ستحتاج الفرق إلى قواعد داخلية: متى تستخدم الجهد العالي، ومتى تستخدم xhigh، ومتى تسمح بسير العمل، ومتى تفرض مراجعة تصميم بشرية أولًا.
رابعًا، يرتفع دور المهندس الكبير إلى مستوى أعلى. وقت أقل في فحص كل مرجع يدويًا. وقت أكثر في تصميم الحزمة التشغيلية: خرائط المستودع، أوامر الاختبار، أوضاع الصلاحيات، استراتيجية الفروع، بوابات CI، ومطالبات المراجعة. أفضل إعدادات برمجة الذكاء الاصطناعي ستبدو كمنصات داخلية صغيرة، لا كمجموعات مطالبات ذكية.
رهان Anthropic: مدير الوكلاء هو من يفوز
Opus 4.8 إصدار نموذج جيد. الإصدار الأكثر إثارة للاهتمام هو طبقة التحكم المحيطة به.
تراهن Anthropic على أن ذكاء الطليعة سيكون متقاربًا بما يكفي بين المختبرات الكبرى، وأن ولاء المطورين سيأتي من التنسيق: مدى جودة النظام في تفكيك العمل، وتشغيل الوكلاء بالتوازي، وإدارة السياق، وطلب التأكيد، والتحقق من الادعاءات، وكشف ما يكفي من الحالة كي يثق البشر به. لا تزال المعايير مهمة. هي تقرر من يدخل التقييم. أما سير العمل فيقرر من يبقى في الحلقة اليومية.
هذا هو الرهان الصحيح. القفزة التالية في إنتاجية المطورين لن تأتي من مطالبة وكيل واحد بأن يكون أذكى قليلًا في دور واحد. ستأتي من إعطاء النماذج القادرة بيئة تشغيل تشبه طريقة حدوث العمل الهندسي الحقيقي: تحقيق متوازٍ، وتنفيذ مرحلي، ومراجعة مستقلة، واختبارات، وتراجع.
Opus 4.8 هو Anthropic وهي تقول الجزء المسكوت عنه بصوت عالٍ. سباق النماذج مستمر، لكن سباق المنتج انتقل إلى تنسيق الوكلاء.
يمكن للقراء الذين يريدون تجربة Claude Fable 5 بأنفسهم استخدامه عبر Claude Fable 5 on OneHop، كنقطة نهاية بديلة مباشرة بسعر أقل بنحو 30% من السعر المعلن. يمكن للحسابات الجديدة البدء برصيد مجاني قدره 10 دولارات، دون الحاجة إلى بطاقة.
قراءة إضافية: بدء الاستخدام مع Claude Fable 5.

