28 мая 2026 года Anthropic выпустила Claude Opus 4.8 с тремя изменениями для разработчиков, которые важнее самого названия модели: в Claude Code появились динамические рабочие процессы, пользователи получили выбираемые уровни усилия, а быстрый режим Opus стал в 2,5 раза быстрее при цене $10 за миллион входных токенов и $50 за миллион выходных токенов — по словам Anthropic, это в три раза дешевле, чем быстрый режим в предыдущих моделях Opus (Anthropic).
Вот в чем настоящая история. Заголовок не в том, что «Claude снова обошел GPT на очередном графике». Заголовок в том, что Anthropic пытается вытащить coding agents из коробки одиночного чата.
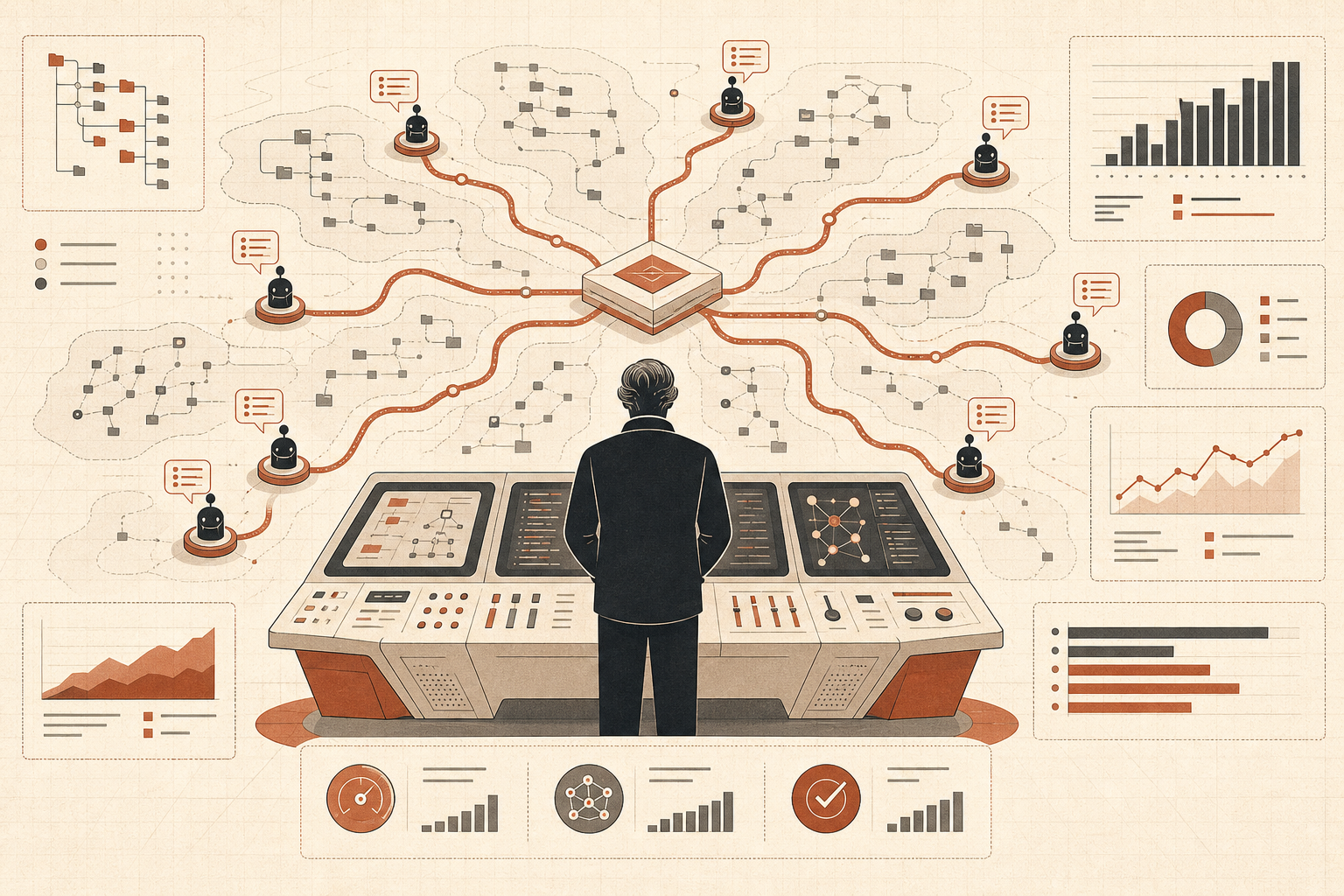
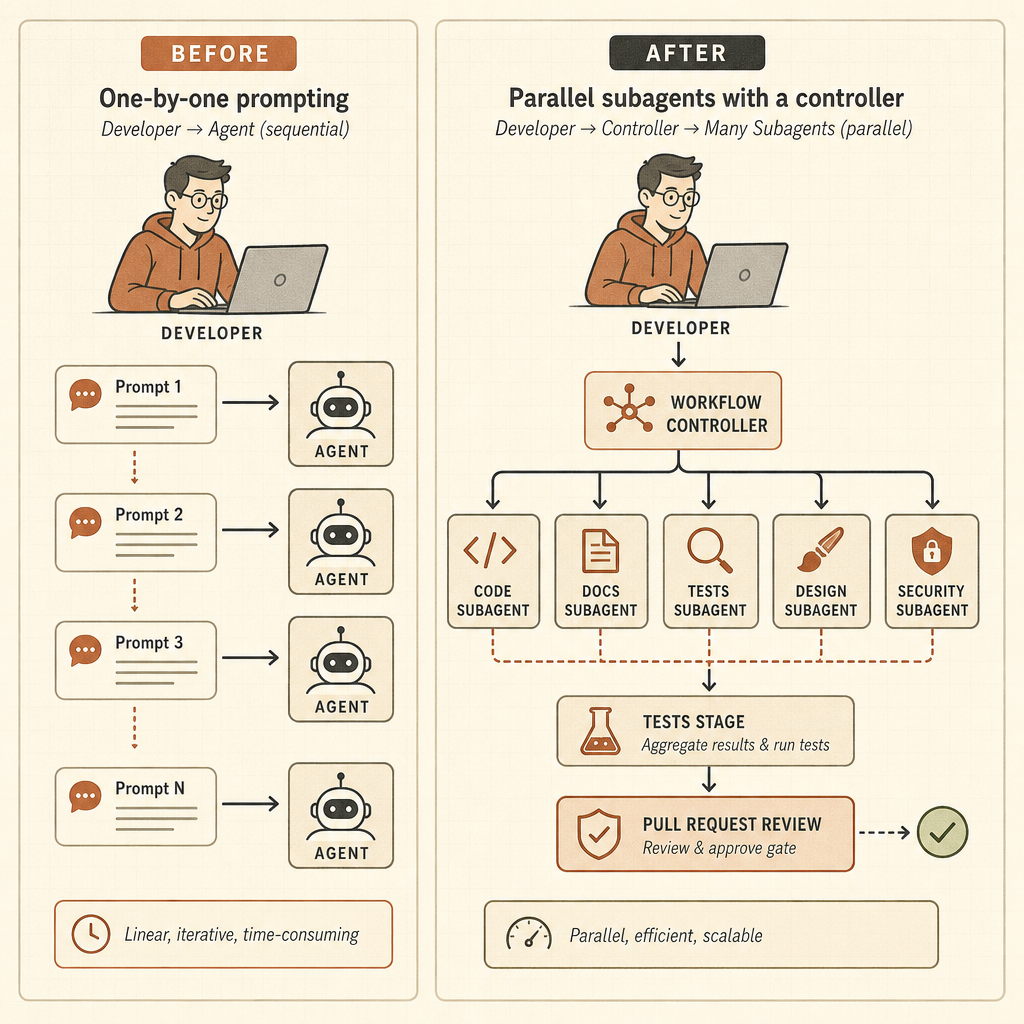
Старый цикл был простым: написать prompt, подождать, посмотреть diff, снова написать prompt. Opus 4.8 указывает на другой цикл: поставить цель, дать системе разнести работу по subagents, держать состояние вне основного разговора, проверить результаты, а затем вернуться с согласованным ответом. Это меняет роль разработчика: он уже не автор prompts, а оператор агентов.
Прирост в бенчмарках реален, но это не ров
Opus 4.8 сильнее Opus 4.7. Anthropic говорит об улучшениях в программировании, agentic-навыках, рассуждении и профессиональных задачах, при этом обычные цены API не изменились: $5 за миллион входных токенов и $25 за миллион выходных токенов (Anthropic). Компания также утверждает, что модель примерно в четыре раза реже, чем Opus 4.7, пропускает ошибки в собственном коде без замечаний.
Цифры из system card ясно показывают позиционирование. На SWE-bench Pro у Opus 4.8 заявлены 69,2%, выше Opus 4.7 с 64,3%, GPT-5.5 с 58,6% и Gemini 3.1 Pro с 54,2%, согласно опубликованным сводкам данных из system card Opus 4.8 от Anthropic (Vellum, Anthropic system card PDF). На Terminal-Bench 2.1 картина грязнее: GPT-5.5 лидирует на том же Terminus-2 harness с 78,2%, а Opus 4.8 получает 74,6%. Anthropic также отмечает, что заявленный результат GPT-5.5 в Codex CLI harness — 83,4%, полезное напоминание: agent benchmarks измеряют модель плюс harness, а не чистый интеллект в банке (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | n/a in Anthropic table | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE with tools | 57.9% | 54.7% | 52.2% | 51.4% |
Читайте эту таблицу как инженер, а не как фанат. Opus 4.8 — значимый релиз. Но это не чистый нокаут. У OpenAI по-прежнему есть убедительная история про terminal-agent вокруг GPT-5.5, которую OpenAI при запуске модели в апреле подала через agentic AI и реальную работу (OpenAI). Google’s Gemini 3.1 Pro, выпущенная 19 февраля 2026 года, тоже позиционировалась вокруг более сильного рассуждения и широкой доступности на поверхностях Google (Google).
Так почему Opus 4.8 ощущается стратегически иначе? Потому что Anthropic продает операционную модель, а не просто модель.
Динамические рабочие процессы превращают Claude Code в runtime
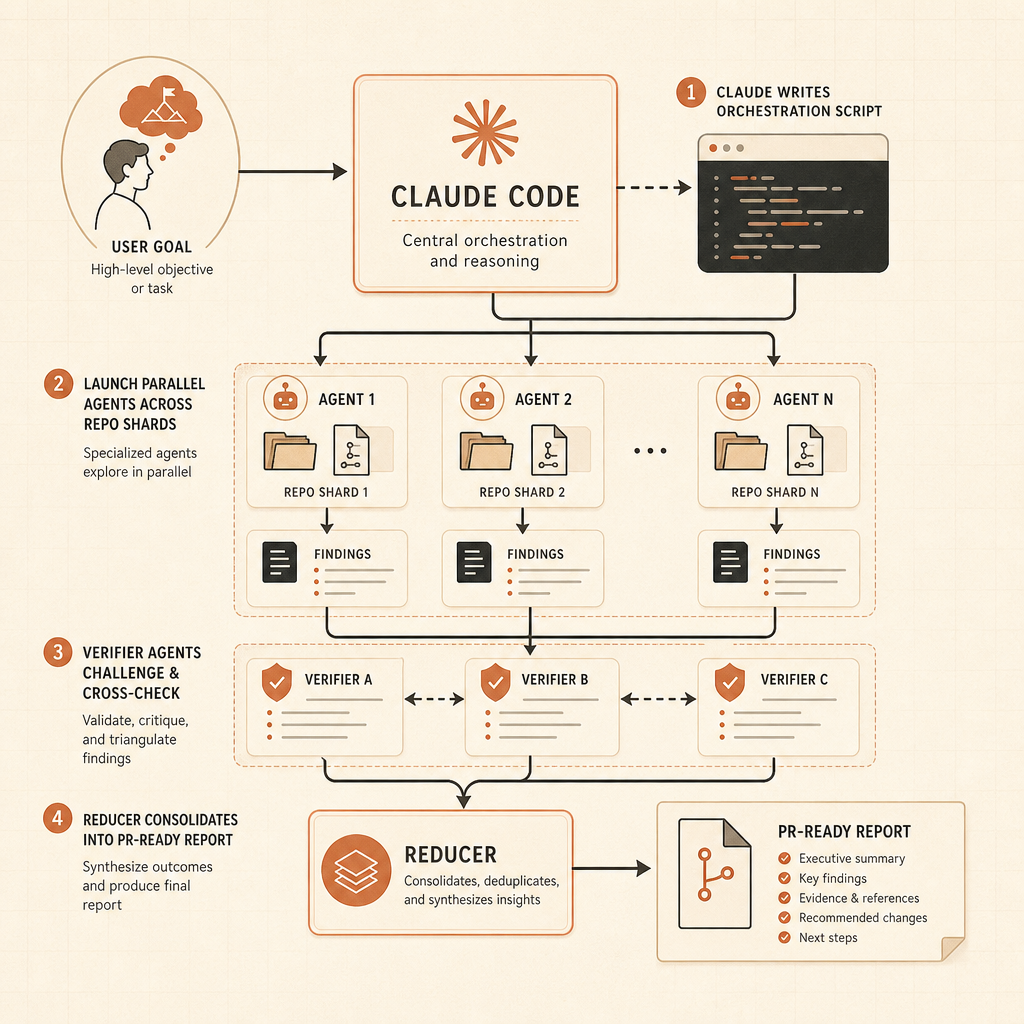
Динамические рабочие процессы — самое острое лезвие этого запуска. В посте Anthropic о Claude Code говорится, что Claude может писать orchestration scripts, которые запускают «десятки и сотни» параллельных subagents за одну сессию, проверяют их работу и возвращают согласованный результат (Claude). Примеры — не игрушечные prompts: поиск багов по всей кодовой базе, profiler-guided optimization audits, security audits, крупные миграции, модернизация и adversarial review.
Пример с Bun — именно тот тип заявления, который разработчики запомнят. Anthropic говорит, что Jarred Sumner использовал динамические рабочие процессы, чтобы портировать Bun с Zig на Rust: 99,8% существующего test suite прошли, получилось около 750 000 строк Rust, а от первого commit до merge прошло одиннадцать дней (Claude). Это не значит, что любая команда может бросить legacy-монолит в Claude и уйти обедать. Но это значит, что Anthropic явно проектирует систему под работу, которая перерастает одно context window и один agent trace.
Разумный prompt теперь выглядит не как «почини этот баг», а скорее как техзадание для внутренней системы автоматизации:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.Это другой навык. Разработчик должен определить scope, budgets, permissions, verification gates и rollback behavior. Полезная ментальная модель — уже не парное программирование. Это управление маленькой, быстрой, неровной инженерной командой, которая никогда не спит и иногда неправильно понимает тикет.
Уровни усилия превращают вычисления в продуктовую ручку
Селектор усилия легко недооценить. Anthropic говорит, что Opus 4.8 по умолчанию работает на высоком усилии; пользователи могут выбрать “extra” или xhigh в Claude Code, а также max, причем более высокий уровень тратит больше токенов ради лучшего результата (Anthropic). В документации Claude API xhigh описан как подходящий для продвинутого программирования и сложной agentic-работы с повторными tool calls и детальным поиском; там же уточняется, что ultracode в Claude Code не является отдельным уровнем усилия API. xhigh сочетается с разрешением запускать multi-agent workflows (Anthropic Docs).
Так Anthropic признает то, что разработчики уже усвоили дорогим способом: «лучшая модель» — неправильная абстракция. Правильный вопрос такой: сколько поиска, использования tools, проверки и параллелизма должна купить эта задача?
Исправление опечатки не должно запускать сотню агентов. Cross-service auth migration, возможно, потребует их. Расследование flaky test может идеально лечь на параллельные гипотезы. Изменение текста в UI — нет.
Быстрый режим укладывается в ту же логику. Стандартная цена Opus 4.8 не изменилась: $5/$25 за миллион токенов, а fast mode стоит $10/$50 и работает в 2,5 раза быстрее (Anthropic). Это не «дешевый Claude». Это премия за latency. Anthropic достаточно снизила прежнюю надбавку fast-mode, чтобы команды начали воспринимать скорость как операционное решение, а не как роскошную настройку.
Сравнение с OpenAI и Gemini — это сравнение поверхностей
OpenAI, Google и Anthropic все гонятся за frontier model scores. Никто не может выйти из этой гонки. Покупатели все еще спрашивают, кто лидирует в SWE-bench, GPQA, HLE, OSWorld и внутренних evals. В procurement decks все еще нужна диаграмма.
Но гонка developer tools смещается от «какая модель отвечает лучше?» к «какая среда позволяет модели безопасно продолжать работу?»
Позиционирование OpenAI в стиле Codex сильно там, где речь о terminal execution, repository interaction и harnessed coding work. Преимущество GPT-5.5 в Terminal-Bench — предупреждение для Anthropic: в низкоуровневой надежности терминала окружающие CLI и execution harness могут перебить разницу в сырых бенчмарках. Преимущество Google — дистрибуция. Модели Gemini попадают в Gemini app, AI Studio, Vertex AI, Workspace-shaped surfaces и Android-adjacent workflows. Поэтому Gemini трудно игнорировать даже тогда, когда конкурирующая модель выигрывает coding chart.
Ответ Anthropic уже и более упрямый: Claude Code должен стать местом, где долгие инженерные задачи планируются, распараллеливаются, проверяются, возобновляются и ревьюятся. Страница Opus описывает модель как созданную для серьезного программирования и AI agents, с 1M context window и доступностью через Claude Platform, AWS, Google Cloud и Microsoft Foundry (Anthropic). Динамические рабочие процессы переносят это из model marketing в product architecture.

Рабочий процесс разработчика меняется четырьмя практическими способами
Во-первых, планирование становится важнее. Динамический рабочий процесс усиливает исходную инструкцию. Расплывчатый prompt может потратить больше токенов, затронуть больше файлов и создать больший беспорядок. Лучшие пользователи будут писать тикеты с явными границами: какие директории входят в scope, какие tests запускать, какие APIs нельзя менять и что считается done.
Во-вторых, проверка становится артефактом первого класса. Anthropic говорит, что рабочие процессы могут использовать independent attempts и adversarial agents, чтобы сломать результат до того, как его увидит пользователь (Claude). Это правильный паттерн. Вывод агента должен приходить с доказательствами: test logs, grep results, benchmark deltas и unresolved risks.
В-третьих, стоимость переезжает из невидимого фонового шума в архитектуру. Динамические рабочие процессы могут потреблять заметно больше usage, чем обычная сессия Claude Code, и Anthropic прямо рекомендует начинать с ограниченных задач (Claude). Командам понадобятся внутренние правила: когда использовать high effort, когда использовать xhigh, когда разрешать workflows, а когда сначала требовать human design review.
В-четвертых, роль senior engineer поднимается выше. Меньше времени на ручную проверку каждой ссылки. Больше времени на проектирование harness: repo maps, test commands, permission modes, branch strategy, CI gates и review prompts. Лучшие AI coding setups будут выглядеть как маленькие внутренние платформы, а не как коллекции хитрых prompts.
Ставка Anthropic: выигрывает менеджер агентов
Opus 4.8 — хороший релиз модели. Но более интересный релиз — окружающая control plane.
Anthropic ставит на то, что frontier intelligence у ведущих лабораторий станет достаточно близким, и лояльность разработчиков будет определяться оркестрацией: насколько хорошо система декомпозирует работу, запускает агентов параллельно, управляет context, просит подтверждения, проверяет утверждения и показывает достаточно состояния, чтобы люди ей доверяли. Бенчмарки все еще важны. Они решают, кто попадет в оценку. Workflows решают, кто останется в ежедневном цикле.
Это правильная ставка. Следующий скачок продуктивности разработчиков придет не от просьбы к одному агенту стать чуть умнее за один ход. Он придет от того, что способным моделям дадут runtime, соответствующий реальной инженерной работе: параллельное расследование, staged implementation, independent review, tests и rollback.
Opus 4.8 — это Anthropic, которая произносит тихую часть вслух. Гонка моделей продолжается, но продуктовая гонка переехала в оркестрацию агентов.
Читатели, которые хотят сами попробовать Claude Fable 5, могут использовать его через Claude Fable 5 on OneHop, drop-in endpoint примерно на 30% дешевле list price. Новые аккаунты могут начать с $10 бесплатно, без карты.
Дополнительно: Getting started with Claude Fable 5.

