On May 28, 2026, Anthropic shipped Claude Opus 4.8 with three developer-facing changes that matter more than the model name: Claude Code gained dynamic workflows, users got selectable effort levels, and Opus fast mode became 2.5× faster while priced at $10 per million input tokens and $50 per million output tokens, which Anthropic says is three times cheaper than fast mode on prior Opus models (Anthropic).
That is the real story. The headline is not “Claude beat GPT on another chart.” The headline is that Anthropic is trying to move coding agents out of the single-chat box.
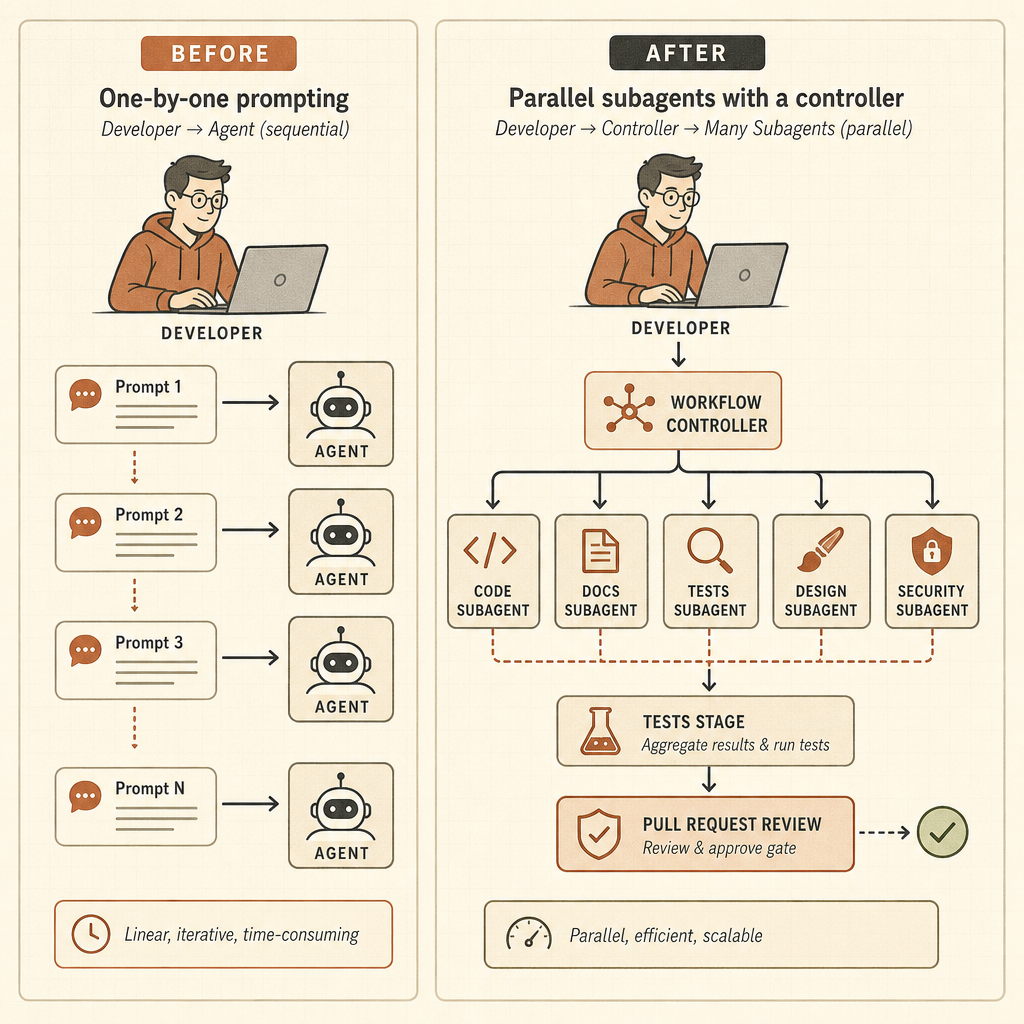
The old loop was simple: prompt, wait, inspect diff, prompt again. Opus 4.8 points at a different loop: assign a goal, let the system split work across subagents, keep state outside the main conversation, verify results, then come back with a coordinated answer. That changes the developer’s job from prompt writer to agent operator.
The Benchmark Bump Is Real, but It Is Not the Moat
Opus 4.8 is stronger than Opus 4.7. Anthropic says it improves across coding, agentic skills, reasoning, and professional work, with regular API pricing unchanged at $5 per million input tokens and $25 per million output tokens (Anthropic). The company also says the model is around four times less likely than Opus 4.7 to let flaws in its own code pass without comment.
The system-card numbers make the positioning clear. On SWE-bench Pro, Opus 4.8 is reported at 69.2%, ahead of Opus 4.7 at 64.3%, GPT-5.5 at 58.6%, and Gemini 3.1 Pro at 54.2%, according to published summaries of Anthropic’s Opus 4.8 system card data (Vellum, Anthropic system card PDF). On Terminal-Bench 2.1, the story is messier: GPT-5.5 leads on the same Terminus-2 harness at 78.2%, while Opus 4.8 lands at 74.6%. Anthropic also notes that GPT-5.5’s reported Codex CLI harness score is 83.4%, a useful reminder that agent benchmarks measure the model plus the harness, not pure intelligence in a jar (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | n/a in Anthropic table | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE with tools | 57.9% | 54.7% | 52.2% | 51.4% |
Read that table like an engineer, not a fan. Opus 4.8 is a meaningful release. It is also not a clean knockout. OpenAI still has a credible terminal-agent story around GPT-5.5, which OpenAI framed around agentic AI and real-world work when it launched the model in April (OpenAI). Google’s Gemini 3.1 Pro, released February 19, 2026, was also positioned around stronger reasoning and broad availability across Google surfaces (Google).
So why does Opus 4.8 feel strategically different? Because Anthropic is selling the operating model, not just the model.
Dynamic Workflows Turn Claude Code Into a Runtime
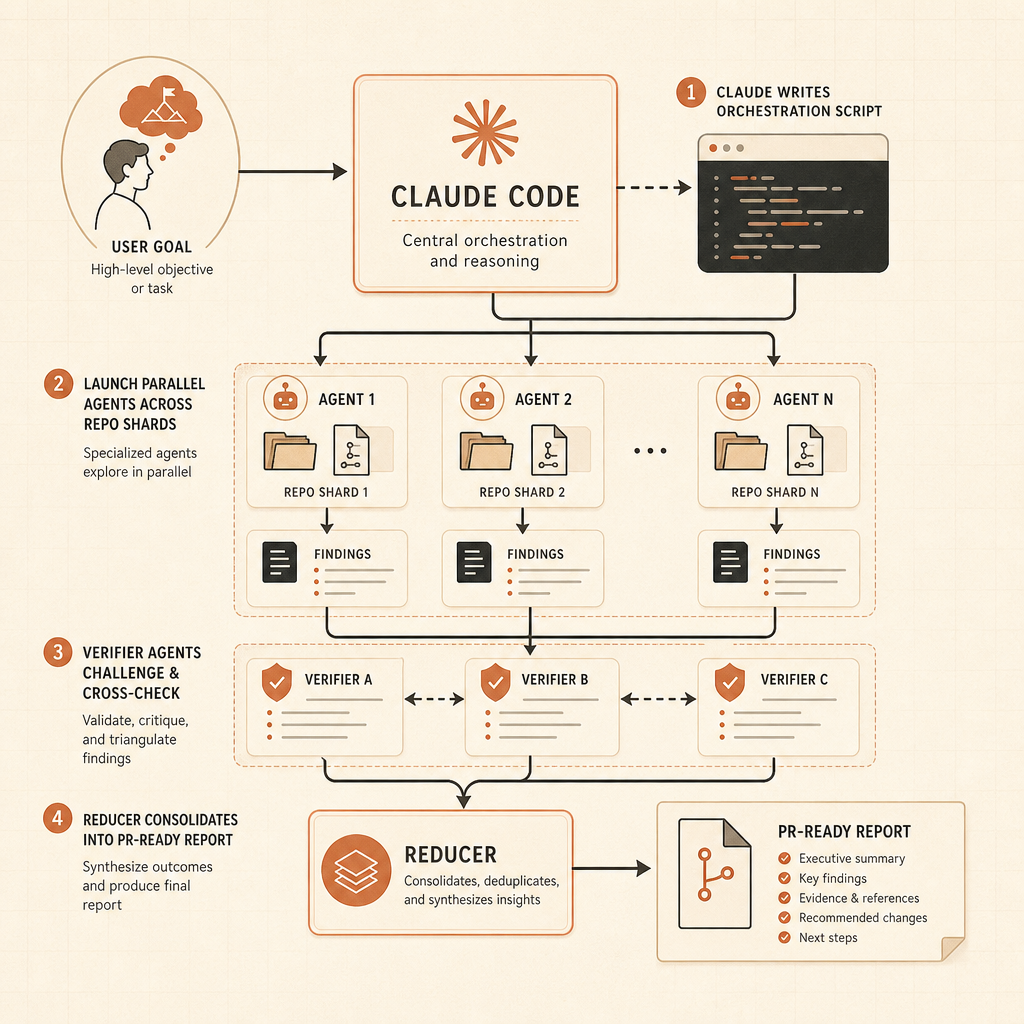
Dynamic workflows are the sharp edge of the launch. Anthropic’s Claude Code post says Claude can write orchestration scripts that run “tens to hundreds” of parallel subagents in one session, check their work, and return a coordinated result (Claude). The examples are not toy prompts: codebase-wide bug hunts, profiler-guided optimization audits, security audits, large migrations, modernization work, and adversarial review.
The Bun example is the kind of claim developers will remember. Anthropic says Jarred Sumner used dynamic workflows to port Bun from Zig to Rust with 99.8% of the existing test suite passing, roughly 750,000 lines of Rust, and eleven days from first commit to merge (Claude). That does not mean every team can throw a legacy monolith at Claude and go to lunch. It does mean Anthropic is explicitly designing for work that outgrows one context window and one agent trace.
A reasonable prompt now looks less like “fix this bug” and more like a job spec for an internal automation system:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.That is a different skill. The developer has to define scope, budgets, permissions, verification gates, and rollback behavior. The useful mental model is no longer pair programming. It is managing a small, fast, uneven engineering team that never sleeps and sometimes misunderstands the ticket.
Effort Levels Make Compute a Product Knob
The effort selector is easy to underestimate. Anthropic says Opus 4.8 defaults to high effort; users can choose “extra” or xhigh in Claude Code, plus max, with higher effort spending more tokens for better results (Anthropic). The Claude API docs describe xhigh as appropriate for advanced coding and complex agentic work with repeated tool calls and detailed search, while clarifying that Claude Code’s ultracode is not a separate API effort level. It pairs xhigh with permission to launch multi-agent workflows (Anthropic Docs).
This is Anthropic admitting something developers already learned the expensive way: “best model” is the wrong abstraction. The right question is: how much search, tool use, verification, and parallelism should this task buy?
A typo fix should not run a hundred agents. A cross-service auth migration might need them. A flaky test investigation may be perfect for parallel hypotheses. A UI copy change is not.
Fast mode fits the same thesis. The standard Opus 4.8 price is unchanged at $5/$25 per million tokens, while fast mode is $10/$50 and runs at 2.5× speed (Anthropic). That is not “cheap Claude.” It is a latency premium. Anthropic cut the prior fast-mode premium enough that teams can start treating speed as an operational decision instead of a luxury setting.
The Comparison With OpenAI and Gemini Is About Surfaces
OpenAI, Google, and Anthropic are all chasing frontier model scores. Nobody gets to opt out of that race. Buyers still ask who leads SWE-bench, GPQA, HLE, OSWorld, and internal evals. Procurement decks still need a chart.
But the developer-tool race is shifting from “which model answers best?” to “which environment lets the model keep working safely?”
OpenAI’s Codex-style positioning is strong around terminal execution, repository interaction, and harnessed coding work. GPT-5.5’s Terminal-Bench edge is a warning to Anthropic: for low-level terminal reliability, the surrounding CLI and execution harness can beat raw benchmark deltas. Google’s advantage is distribution. Gemini models land across the Gemini app, AI Studio, Vertex AI, Workspace-shaped surfaces, and Android-adjacent workflows. That makes Gemini hard to ignore even when a competing model wins a coding chart.
Anthropic’s answer is narrower and more opinionated: Claude Code should become the place where long-running engineering work is planned, fanned out, checked, resumed, and reviewed. The Opus page describes the model as built for serious coding and AI agents, with a 1M context window and availability across Claude Platform, AWS, Google Cloud, and Microsoft Foundry (Anthropic). Dynamic workflows push that from model marketing into product architecture.

The Developer Workflow Changes in Four Practical Ways
First, planning becomes more important. A dynamic workflow amplifies the initial instruction. A vague prompt can waste more tokens, touch more files, and produce a larger mess. The best users will write tickets with explicit boundaries: directories in scope, tests to run, APIs that must not change, and definitions of done.
Second, verification becomes a first-class artifact. Anthropic says workflows can use independent attempts and adversarial agents to break a result before the user sees it (Claude). That is the right pattern. Agent output should arrive with evidence: test logs, grep results, benchmark deltas, and unresolved risks.
Third, cost moves from invisible background noise to architecture. Dynamic workflows can consume substantially more usage than a typical Claude Code session, and Anthropic explicitly recommends starting with scoped tasks (Claude). Teams will need house rules: when to use high effort, when to use xhigh, when to allow workflows, and when to force a human design review first.
Fourth, the senior engineer’s role shifts upward. Less time manually checking every reference. More time designing the harness: repo maps, test commands, permission modes, branch strategy, CI gates, and review prompts. The best AI coding setups will look like small internal platforms, not clever prompt collections.
Anthropic’s Bet: The Agent Manager Wins
Opus 4.8 is a good model release. The more interesting release is the surrounding control plane.
Anthropic is betting that frontier intelligence will be close enough among top labs that developer loyalty will come from orchestration: how well the system decomposes work, runs agents in parallel, manages context, asks for confirmation, verifies claims, and exposes enough state for humans to trust it. Benchmarks still matter. They decide who gets into the evaluation. Workflows decide who stays in the daily loop.
That is the right bet. The next jump in developer productivity will not come from asking a single agent to be a little smarter in a single turn. It will come from giving capable models a runtime that matches how real engineering work happens: parallel investigation, staged implementation, independent review, tests, and rollback.
Opus 4.8 is Anthropic saying the quiet part out loud. The model race continues, but the product race has moved to agent orchestration.
Readers who want to try Claude Fable 5 themselves can use it through Claude Fable 5 on OneHop, a drop-in endpoint priced about 30% under list. New accounts can start with $10 free, with no card required.
Further reading: Getting started with Claude Fable 5.

