Em 28 de maio de 2026, a Anthropic lançou o Claude Opus 4.8 com três mudanças voltadas a desenvolvedores que importam mais do que o nome do modelo: o Claude Code ganhou workflows dinâmicos, os usuários passaram a escolher níveis de esforço, e o modo rápido do Opus ficou 2,5× mais veloz, com preço de $10 por milhão de tokens de entrada e $50 por milhão de tokens de saída, o que, segundo a Anthropic, é três vezes mais barato do que o modo rápido em modelos Opus anteriores (Anthropic).
Essa é a história de verdade. A manchete não é “Claude superou o GPT em mais um gráfico”. A manchete é que a Anthropic está tentando tirar os agentes de programação da caixinha do chat único.
O loop antigo era simples: escrever o prompt, esperar, revisar o diff, escrever outro prompt. O Opus 4.8 aponta para outro loop: definir um objetivo, deixar o sistema dividir o trabalho entre subagentes, manter o estado fora da conversa principal, verificar os resultados e então voltar com uma resposta coordenada. Isso muda o papel do desenvolvedor: de autor de prompts para operador de agentes.
O salto nos benchmarks é real, mas não é o fosso competitivo
O Opus 4.8 é mais forte que o Opus 4.7. A Anthropic diz que ele melhora em programação, habilidades agentivas, raciocínio e trabalho profissional, com o preço regular da API mantido em $5 por milhão de tokens de entrada e $25 por milhão de tokens de saída (Anthropic). A empresa também afirma que o modelo tem cerca de quatro vezes menos chance do que o Opus 4.7 de deixar falhas no próprio código passarem sem comentário.
Os números do system card deixam o posicionamento claro. No SWE-bench Pro, o Opus 4.8 aparece com 69,2%, à frente do Opus 4.7 com 64,3%, do GPT-5.5 com 58,6% e do Gemini 3.1 Pro com 54,2%, segundo resumos publicados dos dados do system card do Opus 4.8 da Anthropic (Vellum, Anthropic system card PDF). No Terminal-Bench 2.1, a história é mais embolada: o GPT-5.5 lidera no mesmo harness Terminus-2 com 78,2%, enquanto o Opus 4.8 chega a 74,6%. A Anthropic também observa que a pontuação reportada do GPT-5.5 no harness Codex CLI é 83,4%, um bom lembrete de que benchmarks de agentes medem o modelo mais o harness, não inteligência pura dentro de um pote (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69,2% | 64,3% | 58,6% | 54,2% |
| SWE-bench Verified | 88,6% | 87,6% | n/a na tabela da Anthropic | 80,6% |
| Terminal-Bench 2.1, Terminus-2 | 74,6% | 66,1% | 78,2% | 70,3% |
| HLE com ferramentas | 57,9% | 54,7% | 52,2% | 51,4% |
Leia essa tabela como engenheiro, não como fã. O Opus 4.8 é um lançamento relevante. Também não é um nocaute limpo. A OpenAI ainda tem uma narrativa crível de agente de terminal em torno do GPT-5.5, que a OpenAI posicionou em torno de IA agentiva e trabalho no mundo real quando lançou o modelo em abril (OpenAI). O Gemini 3.1 Pro, do Google, lançado em 19 de fevereiro de 2026, também foi apresentado com foco em raciocínio mais forte e ampla disponibilidade nas superfícies do Google (Google).
Então por que o Opus 4.8 parece estrategicamente diferente? Porque a Anthropic está vendendo o modelo operacional, não só o modelo.
Workflows dinâmicos transformam o Claude Code em um runtime
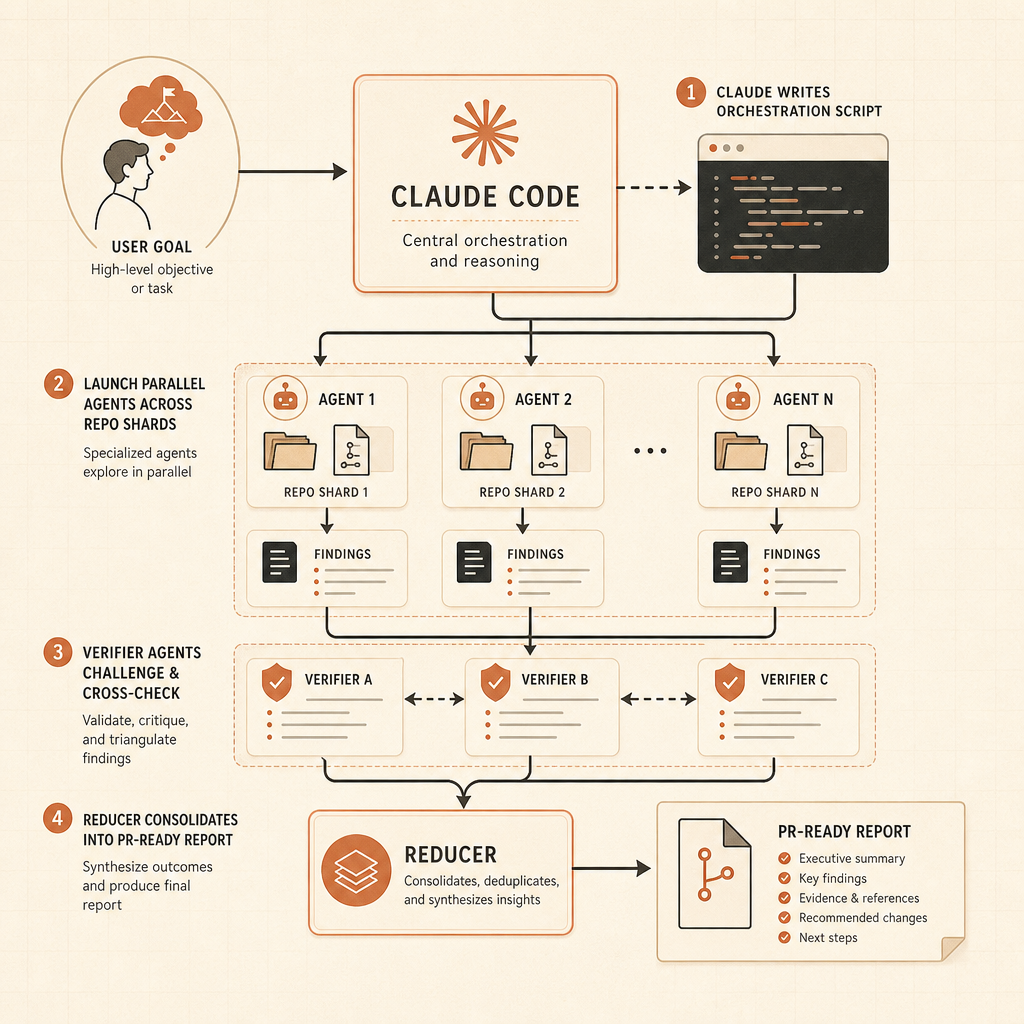
Os workflows dinâmicos são a ponta mais afiada do lançamento. O post da Anthropic sobre o Claude Code diz que o Claude pode escrever scripts de orquestração que rodam “dezenas a centenas” de subagentes paralelos em uma única sessão, verificam o trabalho deles e devolvem um resultado coordenado (Claude). Os exemplos não são prompts de brinquedo: caçadas a bugs em codebases inteiras, auditorias de otimização guiadas por profiler, auditorias de segurança, grandes migrações, trabalhos de modernização e revisão adversarial.
O exemplo do Bun é o tipo de afirmação que desenvolvedores vão lembrar. A Anthropic diz que Jarred Sumner usou workflows dinâmicos para portar o Bun de Zig para Rust com 99,8% da suíte de testes existente passando, cerca de 750.000 linhas de Rust e onze dias do primeiro commit ao merge (Claude). Isso não significa que qualquer equipe pode jogar um monólito legado no Claude e sair para almoçar. Significa, sim, que a Anthropic está projetando explicitamente para trabalhos que passam do tamanho de uma janela de contexto e de um único rastro de agente.
Um prompt razoável agora parece menos com “corrija este bug” e mais com uma especificação de trabalho para um sistema interno de automação:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.Isso exige outra habilidade. O desenvolvedor precisa definir escopo, orçamentos, permissões, etapas de verificação e comportamento de rollback. O modelo mental útil já não é programação em par. É gerenciar uma equipe de engenharia pequena, rápida, irregular, que nunca dorme e às vezes entende errado o ticket.
Níveis de esforço transformam computação em ajuste de produto
É fácil subestimar o seletor de esforço. A Anthropic diz que o Opus 4.8 usa esforço alto por padrão; usuários podem escolher “extra” ou xhigh no Claude Code, além de max, com esforços maiores gastando mais tokens para obter resultados melhores (Anthropic). A documentação da Claude API descreve xhigh como apropriado para programação avançada e trabalho agentivo complexo com chamadas repetidas de ferramentas e busca detalhada, enquanto esclarece que o ultracode do Claude Code não é um nível de esforço separado da API. Ele combina xhigh com permissão para lançar workflows multiagente (Anthropic Docs).
Isso é a Anthropic admitindo algo que desenvolvedores já aprenderam do jeito caro: “melhor modelo” é a abstração errada. A pergunta certa é: quanta busca, uso de ferramentas, verificação e paralelismo esta tarefa deve comprar?
Corrigir um erro de digitação não deveria acionar cem agentes. Uma migração de autenticação entre serviços talvez precise deles. Investigar um teste instável pode ser perfeito para hipóteses em paralelo. Uma mudança de texto na UI, não.
O modo rápido segue a mesma tese. O preço padrão do Opus 4.8 segue em $5/$25 por milhão de tokens, enquanto o modo rápido custa $10/$50 e roda a 2,5× a velocidade (Anthropic). Isso não é “Claude barato”. É um prêmio por latência. A Anthropic reduziu o prêmio do modo rápido anterior o suficiente para que equipes comecem a tratar velocidade como decisão operacional, não como configuração de luxo.
A comparação com OpenAI e Gemini é sobre superfícies
OpenAI, Google e Anthropic estão todas perseguindo pontuações de modelos de fronteira. Ninguém pode ficar fora dessa corrida. Compradores ainda perguntam quem lidera SWE-bench, GPQA, HLE, OSWorld e avaliações internas. Apresentações de compras ainda precisam de um gráfico.
Mas a disputa por ferramentas de desenvolvimento está mudando de “qual modelo responde melhor?” para “qual ambiente deixa o modelo continuar trabalhando com segurança?”
O posicionamento estilo Codex da OpenAI é forte em execução no terminal, interação com repositórios e trabalho de programação com harness. A vantagem do GPT-5.5 no Terminal-Bench é um alerta para a Anthropic: em confiabilidade de terminal de baixo nível, o CLI e o harness de execução ao redor podem superar diferenças brutas de benchmark. A vantagem do Google é distribuição. Modelos Gemini chegam ao app Gemini, AI Studio, Vertex AI, superfícies no estilo Workspace e fluxos adjacentes ao Android. Isso torna o Gemini difícil de ignorar mesmo quando um modelo concorrente vence um gráfico de programação.
A resposta da Anthropic é mais estreita e mais opinativa: o Claude Code deve virar o lugar onde trabalho de engenharia de longa duração é planejado, distribuído, checado, retomado e revisado. A página do Opus descreve o modelo como feito para programação séria e agentes de IA, com janela de contexto de 1M e disponibilidade na Claude Platform, AWS, Google Cloud e Microsoft Foundry (Anthropic). Workflows dinâmicos levam isso do marketing de modelo para a arquitetura do produto.

O workflow do desenvolvedor muda de quatro formas práticas
Primeiro, o planejamento fica mais importante. Um workflow dinâmico amplifica a instrução inicial. Um prompt vago pode gastar mais tokens, mexer em mais arquivos e produzir uma bagunça maior. Os melhores usuários vão escrever tickets com limites explícitos: diretórios dentro do escopo, testes a rodar, APIs que não podem mudar e definições de pronto.
Segundo, a verificação vira artefato de primeira classe. A Anthropic diz que workflows podem usar tentativas independentes e agentes adversariais para quebrar um resultado antes que o usuário o veja (Claude). Esse é o padrão certo. A saída de agentes deve chegar com evidências: logs de testes, resultados de grep, deltas de benchmark e riscos não resolvidos.
Terceiro, custo deixa de ser ruído de fundo invisível e vira arquitetura. Workflows dinâmicos podem consumir substancialmente mais uso do que uma sessão típica do Claude Code, e a Anthropic recomenda explicitamente começar com tarefas bem delimitadas (Claude). Equipes vão precisar de regras internas: quando usar esforço alto, quando usar xhigh, quando permitir workflows e quando exigir antes uma revisão humana de design.
Quarto, o papel do engenheiro sênior sobe um nível. Menos tempo checando manualmente cada referência. Mais tempo desenhando o harness: mapas do repositório, comandos de teste, modos de permissão, estratégia de branches, gates de CI e prompts de revisão. As melhores configurações de programação com IA vão parecer pequenas plataformas internas, não coleções espertas de prompts.
A aposta da Anthropic: quem vence é o gerente de agentes
O Opus 4.8 é um bom lançamento de modelo. O lançamento mais interessante é o plano de controle ao redor dele.
A Anthropic está apostando que a inteligência de fronteira será parecida o bastante entre os principais laboratórios para que a fidelidade dos desenvolvedores venha da orquestração: quão bem o sistema decompõe trabalho, roda agentes em paralelo, gerencia contexto, pede confirmação, verifica afirmações e expõe estado suficiente para humanos confiarem nele. Benchmarks ainda importam. Eles decidem quem entra na avaliação. Workflows decidem quem fica no loop diário.
Essa é a aposta certa. O próximo salto em produtividade de desenvolvedores não virá de pedir a um único agente que seja um pouco mais inteligente em uma única rodada. Virá de dar a modelos capazes um runtime que combine com a forma como o trabalho real de engenharia acontece: investigação em paralelo, implementação em etapas, revisão independente, testes e rollback.
O Opus 4.8 é a Anthropic dizendo em voz alta a parte que ficava implícita. A corrida dos modelos continua, mas a corrida de produto mudou para a orquestração de agentes.
Leitores que quiserem testar o Claude Fable 5 por conta própria podem usá-lo pelo Claude Fable 5 on OneHop, um endpoint drop-in com preço cerca de 30% abaixo do preço de lista. Novas contas podem começar com $10 grátis, sem precisar de cartão.
Leitura complementar: Primeiros passos com Claude Fable 5.

