2026 年 5 月 28 日,Anthropic 发布了 Claude Opus 4.8。真正值得开发者关注的,不只是这个模型名字,而是三个面向开发者的变化:Claude Code 获得了动态工作流,用户可以选择不同的 effort 等级,Opus fast mode 速度提升到 2.5 倍,价格为每百万输入 token 10 美元、每百万输出 token 50 美元。Anthropic 表示,这比此前 Opus 模型的 fast mode 便宜了三倍(Anthropic)。
这才是真正的重点。标题不该是“Claude 又在某张榜单上打赢了 GPT”。真正的标题是:Anthropic 正试图把编码智能体从单一聊天框里搬出来。
过去的循环很简单:写 prompt,等待,检查 diff,再写 prompt。Opus 4.8 指向的是另一种循环:交给系统一个目标,让它把工作拆给多个子智能体,把状态保存在主对话之外,验证结果,然后带着一份协调好的答案回来。这会把开发者的角色从 prompt 作者变成智能体操作员。
基准分数确实涨了,但这不是护城河
Opus 4.8 比 Opus 4.7 更强。Anthropic 表示,它在编码、智能体能力、推理和专业工作方面都有提升,常规 API 价格保持不变,仍为每百万输入 token 5 美元、每百万输出 token 25 美元(Anthropic)。该公司还表示,相比 Opus 4.7,这个模型让自己代码里的缺陷不经提醒就通过的概率大约低了四倍。
系统卡里的数字把定位说得很清楚。根据 Anthropic Opus 4.8 系统卡数据的公开汇总,Opus 4.8 在 SWE-bench Pro 上为 69.2%,领先 Opus 4.7 的 64.3%、GPT-5.5 的 58.6% 和 Gemini 3.1 Pro 的 54.2%(Vellum,Anthropic system card PDF)。到了 Terminal-Bench 2.1,情况就没那么干净了:在同一个 Terminus-2 harness 上,GPT-5.5 以 78.2% 领先,而 Opus 4.8 为 74.6%。Anthropic 还指出,GPT-5.5 在 Codex CLI harness 上报告的分数是 83.4%。这是个有用的提醒:智能体基准测的是模型加 harness,而不是装在罐子里的纯智能(Anthropic)。
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | Anthropic 表中未列 | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE with tools | 57.9% | 54.7% | 52.2% | 51.4% |
读这张表时,要像工程师,不要像粉丝。Opus 4.8 是一次有分量的发布。但它也不是一拳 KO。OpenAI 围绕 GPT-5.5 仍然有一套可信的终端智能体叙事;OpenAI 在 4 月发布该模型时,也把它包装在智能体 AI 和真实世界工作之中(OpenAI)。Google 在 2026 年 2 月 19 日发布的 Gemini 3.1 Pro,也被定位为推理更强,并在 Google 各类入口中广泛可用(Google)。
那为什么 Opus 4.8 在战略上感觉不一样?因为 Anthropic 卖的不只是模型,而是工作方式。
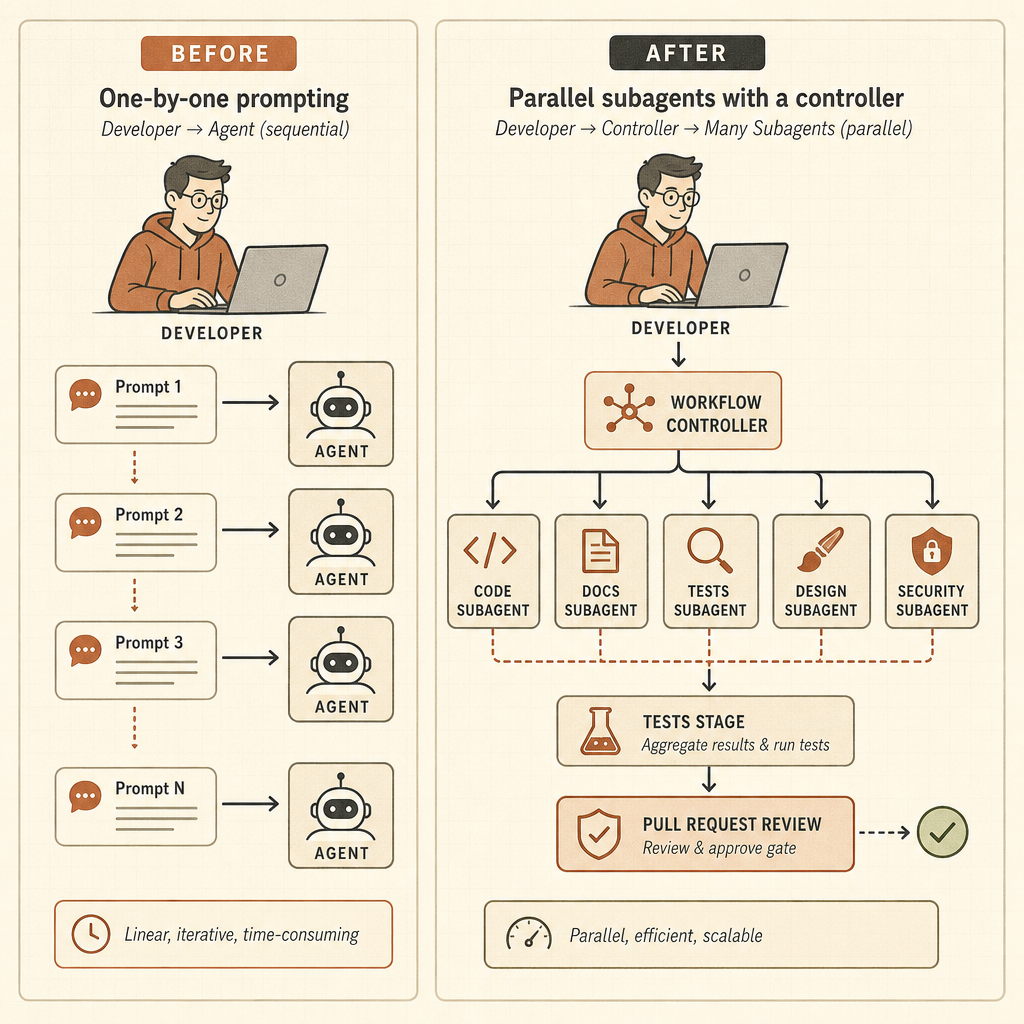
动态工作流把 Claude Code 变成运行时
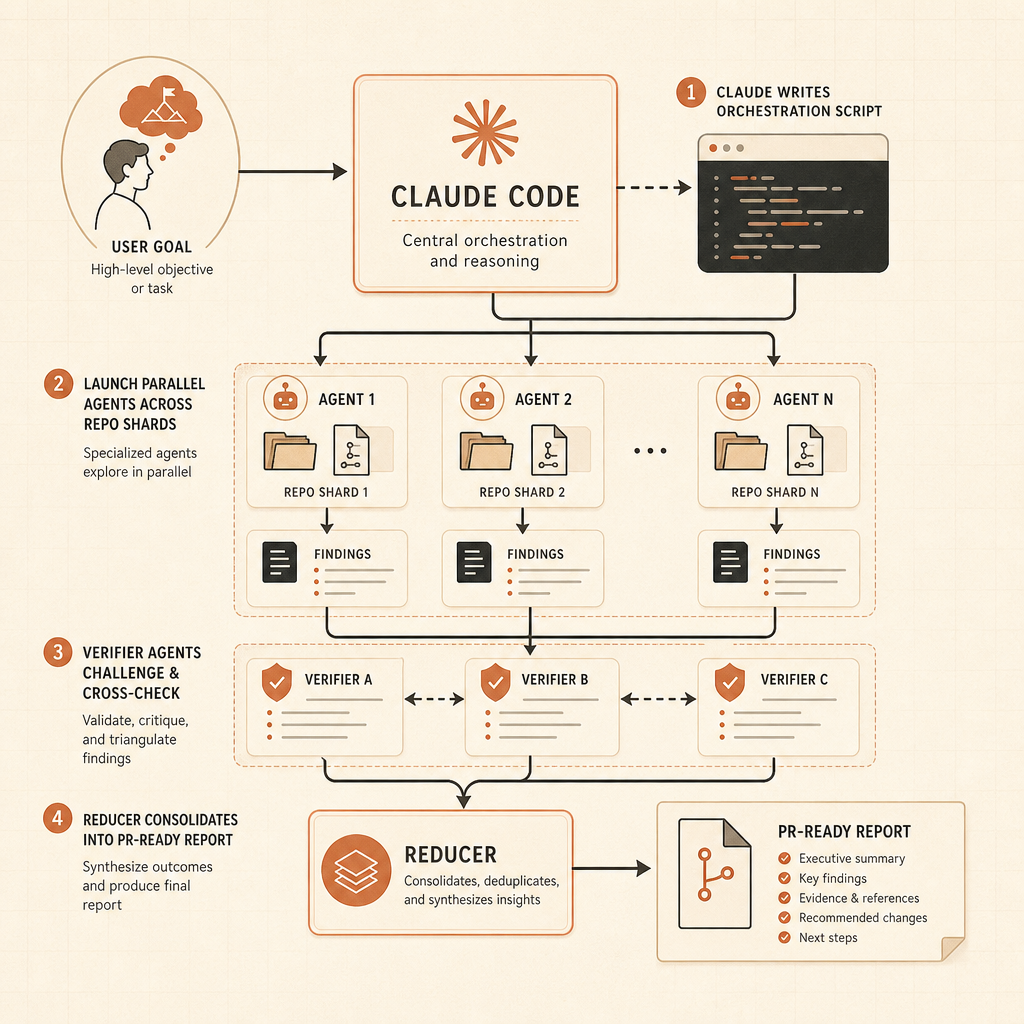
动态工作流是这次发布最锋利的部分。Anthropic 在 Claude Code 的文章中表示,Claude 可以编写编排脚本,在一次会话里运行“数十到数百个”并行子智能体,检查它们的工作,并返回一个协调后的结果(Claude)。这些例子不是玩具 prompt:全代码库 bug 搜索、基于 profiler 的优化审计、安全审计、大规模迁移、现代化改造,以及对抗式评审。
Bun 的例子是开发者会记住的那类说法。Anthropic 表示,Jarred Sumner 使用动态工作流把 Bun 从 Zig 移植到 Rust,现有测试套件通过率达到 99.8%,产出约 75 万行 Rust,从第一次提交到合并用了 11 天(Claude)。这并不意味着每个团队都能把一个遗留巨石扔给 Claude 然后去吃午饭。但它确实意味着,Anthropic 正明确为那些超出一个上下文窗口、一个智能体轨迹的工作而设计。
现在,一个合理的 prompt 看起来不再像“修这个 bug”,而更像一份给内部自动化系统的任务说明:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.这是一种不同的技能。开发者必须定义范围、预算、权限、验证门槛和回滚行为。更有用的心智模型不再是结对编程,而是管理一支小型、快速、水平参差不齐、从不睡觉、而且有时会误解工单的工程团队。
Effort 等级让算力变成产品旋钮
effort 选择器很容易被低估。Anthropic 表示,Opus 4.8 默认使用 high effort;用户可以在 Claude Code 中选择 “extra” 或 xhigh,以及 max,更高的 effort 会消耗更多 token,以换取更好的结果(Anthropic)。Claude API 文档将 xhigh 描述为适合高级编码和复杂智能体工作的等级,尤其是需要反复工具调用和细致搜索的任务;同时也说明 Claude Code 的 ultracode 并不是一个单独的 API effort 等级。它把 xhigh 和启动多智能体工作流的权限配在一起(Anthropic Docs)。
这是 Anthropic 承认了一件开发者早已用钱学会的事:“最好的模型”是错误抽象。真正的问题是:这个任务值得购买多少搜索、工具使用、验证和并行度?
修一个拼写错误不该跑一百个智能体。跨服务认证迁移可能需要。排查一个 flaky test 也许非常适合并行假设。改一段 UI 文案就不需要。
fast mode 也符合这套逻辑。标准 Opus 4.8 价格保持在每百万 token 5/25 美元,而 fast mode 是 10/50 美元,速度达到 2.5 倍(Anthropic)。这不是“便宜版 Claude”。这是延迟溢价。Anthropic 把此前 fast-mode 溢价降到一个程度,让团队可以开始把速度当作运营决策,而不是奢侈设置。
与 OpenAI 和 Gemini 的比较,关键在入口
OpenAI、Google 和 Anthropic 都在追逐前沿模型分数。没人能退出这场比赛。买方仍然会问谁领先 SWE-bench、GPQA、HLE、OSWorld 和内部评测。采购材料里仍然需要一张图表。
但开发者工具之争正在从“哪个模型回答最好?”转向“哪个环境能让模型安全地持续工作?”
OpenAI 的 Codex 式定位,在终端执行、代码库交互和带 harness 的编码工作上很强。GPT-5.5 在 Terminal-Bench 上的优势是在提醒 Anthropic:对于底层终端可靠性来说,周围的 CLI 和执行 harness 可以压过原始基准差距。Google 的优势是分发。Gemini 模型会落到 Gemini app、AI Studio、Vertex AI、Workspace 形态的入口,以及 Android 相邻的工作流里。这让 Gemini 即使在某张编码榜单上输给竞争对手,也很难被忽视。
Anthropic 的答案更窄,也更有主张:Claude Code 应该成为长期工程工作被规划、分发、检查、恢复和评审的地方。Opus 页面把该模型描述为面向严肃编码和 AI 智能体构建,具备 1M 上下文窗口,并可通过 Claude Platform、AWS、Google Cloud 和 Microsoft Foundry 使用(Anthropic)。动态工作流把这句话从模型营销推进到了产品架构。

开发者工作流会发生四个实际变化
第一,规划变得更重要。动态工作流会放大初始指令。含糊的 prompt 会浪费更多 token,触碰更多文件,制造更大的混乱。最会用的人会写边界清晰的工单:哪些目录在范围内,要跑哪些测试,哪些 API 不能改,以及怎样才算完成。
第二,验证会变成一等产物。Anthropic 表示,工作流可以使用独立尝试和对抗式智能体,在用户看到结果之前先把结果打破(Claude)。这是正确模式。智能体输出应该带着证据一起到达:测试日志、grep 结果、基准差异和未解决风险。
第三,成本会从看不见的背景噪音变成架构问题。动态工作流的用量可能远高于一次典型的 Claude Code 会话,Anthropic 也明确建议从范围受限的任务开始(Claude)。团队需要内部规则:什么时候用 high effort,什么时候用 xhigh,什么时候允许工作流,什么时候必须先进行人工设计评审。
第四,高级工程师的角色会上移。手动检查每一个引用的时间会变少。更多时间会花在设计 harness 上:仓库地图、测试命令、权限模式、分支策略、CI 门禁和评审 prompt。最好的 AI 编码配置会像小型内部平台,而不是一堆聪明 prompt 的收藏夹。
Anthropic 的赌注:智能体管理者会赢
Opus 4.8 是一次不错的模型发布。更有意思的是它周围的控制平面。
Anthropic 押注的是:顶级实验室之间的前沿智能会足够接近,开发者忠诚度会来自编排能力——系统分解工作、并行运行智能体、管理上下文、请求确认、验证说法,以及暴露足够状态让人类信任它的能力。基准仍然重要。它们决定谁能进入评估名单。工作流决定谁能留在日常循环里。
这是正确的赌注。开发者生产力的下一次跃迁,不会来自让单个智能体在单轮对话里再聪明一点。它会来自给有能力的模型一个运行时,让它匹配真实工程工作的样子:并行调查、分阶段实现、独立评审、测试和回滚。
Opus 4.8 是 Anthropic 把潜台词说了出来。模型竞赛还在继续,但产品竞赛已经转向智能体编排。
想亲自试试 Claude Fable 5 的读者,可以通过 Claude Fable 5 on OneHop 使用它,这是一个可直接替换的 endpoint,价格比标价低约 30%。新账号可以从 $10 免费额度开始,无需绑卡。
延伸阅读:Claude Fable 5 入门指南.

