2026년 5월 28일, Anthropic은 Claude Opus 4.8을 출시했다. 하지만 모델 이름보다 더 중요한 개발자 대상 변화는 세 가지다. Claude Code에 동적 워크플로가 추가됐고, 사용자는 effort 수준을 선택할 수 있게 됐으며, Opus fast mode는 2.5배 빨라졌다. 가격은 입력 토큰 100만 개당 10달러, 출력 토큰 100만 개당 50달러다. Anthropic은 이것이 이전 Opus 모델의 fast mode보다 세 배 저렴하다고 말한다 (Anthropic).
진짜 이야기는 여기에 있다. 헤드라인은 “Claude가 또 다른 차트에서 GPT를 이겼다”가 아니다. 헤드라인은 Anthropic이 코딩 에이전트를 단일 채팅 상자 밖으로 끌어내려 한다는 점이다.
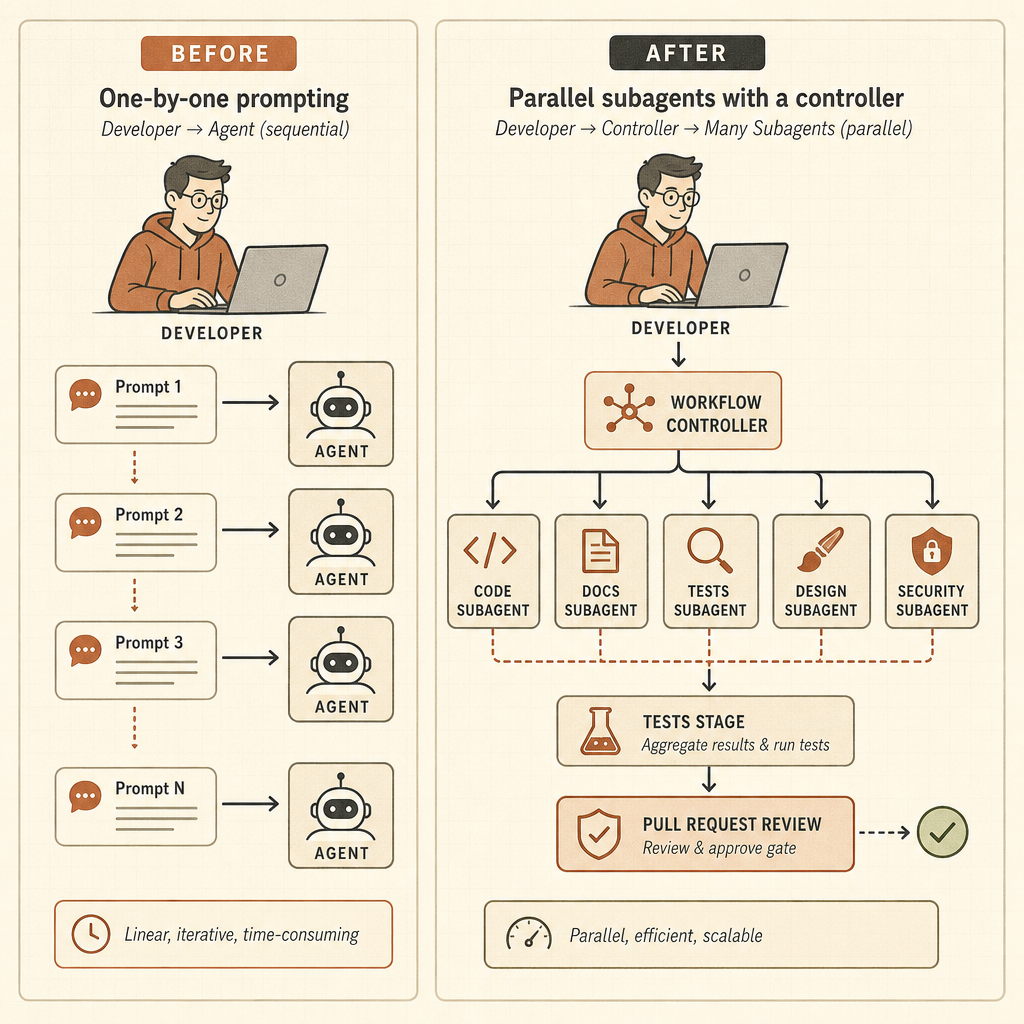
예전 루프는 단순했다. 프롬프트를 넣고, 기다리고, diff를 확인하고, 다시 프롬프트를 넣는다. Opus 4.8은 다른 루프를 가리킨다. 목표를 맡기고, 시스템이 작업을 하위 에이전트로 나누게 하고, 메인 대화 바깥에 상태를 유지하고, 결과를 검증한 뒤, 조율된 답으로 돌아오게 하는 식이다. 개발자의 역할은 프롬프트 작성자에서 에이전트 운영자로 바뀐다.
벤치마크 상승은 진짜지만, 해자는 아니다
Opus 4.8은 Opus 4.7보다 강하다. Anthropic은 코딩, 에이전트 역량, 추론, 전문 업무 전반에서 개선됐다고 말하며, 일반 API 가격은 입력 토큰 100만 개당 5달러, 출력 토큰 100만 개당 25달러로 그대로 유지했다 (Anthropic). 회사는 또 이 모델이 Opus 4.7보다 자기 코드의 결함을 지적하지 않고 넘길 가능성이 약 네 배 낮다고 말한다.
시스템 카드 수치를 보면 포지셔닝이 분명하다. Anthropic의 Opus 4.8 시스템 카드 데이터에 대한 공개 요약에 따르면, SWE-bench Pro에서 Opus 4.8은 69.2%로 보고됐다. Opus 4.7의 64.3%, GPT-5.5의 58.6%, Gemini 3.1 Pro의 54.2%보다 앞선다 (Vellum, Anthropic system card PDF). Terminal-Bench 2.1에서는 이야기가 좀 더 복잡하다. 같은 Terminus-2 하네스 기준으로 GPT-5.5가 78.2%로 앞서고, Opus 4.8은 74.6%다. Anthropic은 또한 GPT-5.5의 Codex CLI 하네스 점수가 83.4%로 보고됐다고 언급한다. 에이전트 벤치마크는 병 속의 순수 지능이 아니라 모델과 하네스를 함께 측정한다는 점을 떠올리게 하는 유용한 대목이다 (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | Anthropic 표에는 n/a | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE with tools | 57.9% | 54.7% | 52.2% | 51.4% |
이 표는 팬이 아니라 엔지니어처럼 읽어야 한다. Opus 4.8은 의미 있는 릴리스다. 동시에 깔끔한 KO승은 아니다. OpenAI는 여전히 GPT-5.5를 둘러싼 설득력 있는 터미널 에이전트 스토리를 갖고 있다. OpenAI는 4월 이 모델을 출시하면서 에이전트형 AI와 실제 업무를 중심에 놓았다 (OpenAI). 2026년 2월 19일 출시된 Google의 Gemini 3.1 Pro 역시 더 강한 추론과 Google 전반의 폭넓은 사용 가능성을 앞세웠다 (Google).
그렇다면 왜 Opus 4.8은 전략적으로 다르게 느껴질까? Anthropic이 모델 자체만이 아니라 운영 모델을 팔고 있기 때문이다.
동적 워크플로는 Claude Code를 런타임으로 바꾼다
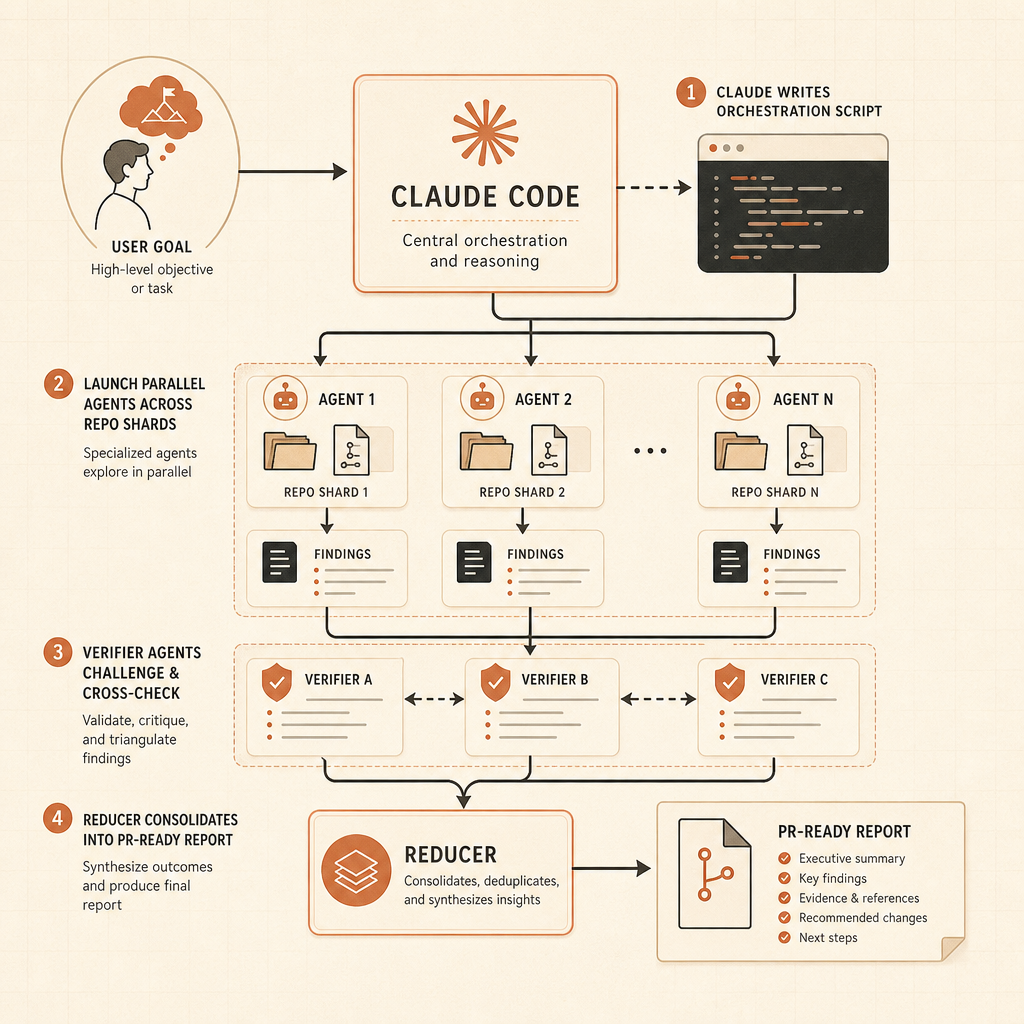
동적 워크플로는 이번 출시의 날카로운 끝이다. Anthropic의 Claude Code 글에 따르면 Claude는 한 세션 안에서 “수십에서 수백” 개의 병렬 하위 에이전트를 실행하는 오케스트레이션 스크립트를 작성하고, 그들의 작업을 확인한 뒤, 조율된 결과를 돌려줄 수 있다 (Claude). 예시는 장난감 프롬프트가 아니다. 코드베이스 전체 버그 사냥, 프로파일러 기반 최적화 감사, 보안 감사, 대규모 마이그레이션, 현대화 작업, 적대적 리뷰가 포함된다.
Bun 사례는 개발자들이 기억할 만한 주장이다. Anthropic은 Jarred Sumner가 동적 워크플로를 사용해 Bun을 Zig에서 Rust로 포팅했고, 기존 테스트 스위트의 99.8%가 통과했으며, 약 75만 줄의 Rust 코드가 나왔고, 첫 커밋부터 머지까지 11일이 걸렸다고 말한다 (Claude). 그렇다고 모든 팀이 레거시 모놀리스를 Claude에게 던져 놓고 점심을 먹으러 가도 된다는 뜻은 아니다. 의미는 따로 있다. Anthropic은 하나의 컨텍스트 창과 하나의 에이전트 추적을 넘어서는 작업을 명시적으로 설계하고 있다.
이제 그럴듯한 프롬프트는 “이 버그 고쳐줘”보다는 내부 자동화 시스템을 위한 작업 명세에 더 가까워진다.
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.이건 다른 기술이다. 개발자는 범위, 예산, 권한, 검증 게이트, 롤백 동작을 정의해야 한다. 더 이상 유용한 사고 모델은 페어 프로그래밍이 아니다. 잠들지 않고 빠르게 움직이지만, 실력은 들쭉날쭉하고 가끔 티켓을 오해하는 작은 엔지니어링 팀을 관리하는 쪽에 가깝다.
effort 수준은 컴퓨트를 제품 조절값으로 만든다
effort 선택기는 과소평가하기 쉽다. Anthropic은 Opus 4.8이 기본적으로 high effort로 동작하며, 사용자는 Claude Code에서 “extra” 또는 xhigh, 그리고 max를 선택할 수 있다고 말한다. effort가 높을수록 더 나은 결과를 위해 더 많은 토큰을 쓴다 (Anthropic). Claude API 문서는 xhigh가 반복적인 도구 호출과 세밀한 검색이 필요한 고급 코딩 및 복잡한 에이전트 작업에 적합하다고 설명하며, Claude Code의 ultracode는 별도의 API effort 수준이 아니라고 명확히 한다. 또한 xhigh를 멀티 에이전트 워크플로 실행 권한과 연결한다 (Anthropic Docs).
이건 Anthropic이 개발자들이 이미 비싼 수업료를 내고 배운 사실을 인정하는 것이다. “최고의 모델”은 잘못된 추상화다. 맞는 질문은 이것이다. 이 작업에 검색, 도구 사용, 검증, 병렬성을 얼마나 사게 할 것인가?
오타 수정에 에이전트 백 개를 돌릴 필요는 없다. 크로스 서비스 인증 마이그레이션에는 필요할 수 있다. flaky 테스트 조사는 병렬 가설 검증에 딱 맞을 수 있다. UI 문구 변경은 아니다.
Fast mode도 같은 논리를 따른다. 표준 Opus 4.8 가격은 토큰 100만 개당 5달러/25달러로 그대로이고, fast mode는 10달러/50달러에 2.5배 속도로 동작한다 (Anthropic). 이건 “저렴한 Claude”가 아니다. 지연시간 프리미엄이다. Anthropic은 이전 fast-mode 프리미엄을 충분히 낮춰, 팀들이 속도를 사치 설정이 아니라 운영상의 결정으로 다루기 시작할 수 있게 했다.
OpenAI와 Gemini와의 비교는 표면에 관한 싸움이다
OpenAI, Google, Anthropic은 모두 프런티어 모델 점수를 쫓고 있다. 그 경쟁에서 빠질 수 있는 회사는 없다. 구매자는 여전히 SWE-bench, GPQA, HLE, OSWorld, 내부 eval에서 누가 앞서는지 묻는다. 구매 검토 자료에는 여전히 차트가 필요하다.
하지만 개발자 도구 경쟁은 “어느 모델이 가장 잘 답하나?”에서 “어느 환경이 모델을 안전하게 계속 일하게 해주나?”로 이동하고 있다.
OpenAI의 Codex식 포지셔닝은 터미널 실행, 저장소 상호작용, 하네스가 붙은 코딩 작업에서 강하다. GPT-5.5의 Terminal-Bench 우위는 Anthropic에게 경고다. 저수준 터미널 신뢰성에서는 주변 CLI와 실행 하네스가 순수 벤치마크 차이를 이길 수 있다. Google의 강점은 배포다. Gemini 모델은 Gemini 앱, AI Studio, Vertex AI, Workspace 형태의 표면, Android 인접 워크플로 전반에 들어간다. 그래서 경쟁 모델이 코딩 차트에서 이겨도 Gemini는 무시하기 어렵다.
Anthropic의 답은 더 좁고 더 고집스럽다. Claude Code는 장시간 엔지니어링 작업이 계획되고, 펼쳐지고, 확인되고, 재개되고, 리뷰되는 장소가 되어야 한다는 것이다. Opus 페이지는 이 모델을 진지한 코딩과 AI 에이전트를 위해 만들어진 모델로 설명하며, 1M 컨텍스트 창과 Claude Platform, AWS, Google Cloud, Microsoft Foundry 전반의 사용 가능성을 내세운다 (Anthropic). 동적 워크플로는 이를 모델 마케팅에서 제품 아키텍처로 밀어 올린다.

개발자 워크플로는 네 가지 실질적 방식으로 바뀐다
첫째, 계획이 더 중요해진다. 동적 워크플로는 초기 지시를 증폭한다. 모호한 프롬프트는 더 많은 토큰을 낭비하고, 더 많은 파일을 건드리고, 더 큰 난장판을 만들 수 있다. 잘 쓰는 사람들은 명확한 경계를 가진 티켓을 작성할 것이다. 범위에 포함되는 디렉터리, 실행할 테스트, 바뀌면 안 되는 APIs, 완료의 정의 같은 것들이다.
둘째, 검증은 1급 산출물이 된다. Anthropic은 워크플로가 사용자가 결과를 보기 전에 독립적인 시도와 적대적 에이전트를 사용해 결과를 깨뜨려볼 수 있다고 말한다 (Claude). 이게 맞는 패턴이다. 에이전트 출력은 증거와 함께 와야 한다. 테스트 로그, grep 결과, 벤치마크 변화, 해결되지 않은 리스크가 포함되어야 한다.
셋째, 비용은 보이지 않는 배경 소음에서 아키텍처로 이동한다. 동적 워크플로는 일반적인 Claude Code 세션보다 훨씬 더 많은 사용량을 소비할 수 있고, Anthropic은 범위가 제한된 작업부터 시작하라고 명시적으로 권장한다 (Claude). 팀에는 내부 규칙이 필요해질 것이다. 언제 high effort를 쓸지, 언제 xhigh를 쓸지, 언제 워크플로를 허용할지, 언제 먼저 사람의 설계 리뷰를 강제할지에 대한 규칙이다.
넷째, 시니어 엔지니어의 역할은 더 위로 올라간다. 모든 참조를 수작업으로 확인하는 시간은 줄어든다. 대신 하네스를 설계하는 시간이 늘어난다. 저장소 맵, 테스트 명령, 권한 모드, 브랜치 전략, CI 게이트, 리뷰 프롬프트가 중요해진다. 최고의 AI 코딩 환경은 영리한 프롬프트 모음이 아니라 작은 내부 플랫폼처럼 보일 것이다.
Anthropic의 베팅: 에이전트 매니저가 이긴다
Opus 4.8은 좋은 모델 릴리스다. 더 흥미로운 릴리스는 그 주변의 제어 평면이다.
Anthropic은 상위 연구소들 사이에서 프런티어 지능이 충분히 비슷해질 것이며, 개발자 충성도는 오케스트레이션에서 나온다고 베팅하고 있다. 시스템이 작업을 얼마나 잘 분해하는지, 에이전트를 병렬로 실행하는지, 컨텍스트를 관리하는지, 확인을 요청하는지, 주장을 검증하는지, 사람이 신뢰할 만큼 충분한 상태를 노출하는지가 중요해진다는 뜻이다. 벤치마크는 여전히 중요하다. 평가 대상에 들어갈 사람을 결정한다. 하지만 일상 루프에 남을 사람은 워크플로가 결정한다.
맞는 베팅이다. 개발자 생산성의 다음 도약은 단일 에이전트에게 한 턴 안에서 조금 더 똑똑해지라고 요구하는 데서 오지 않는다. 실제 엔지니어링 작업 방식에 맞는 런타임을 유능한 모델에게 주는 데서 온다. 병렬 조사, 단계적 구현, 독립 리뷰, 테스트, 롤백 말이다.
Opus 4.8은 Anthropic이 조용히 하던 말을 밖으로 꺼낸 것이다. 모델 경쟁은 계속된다. 하지만 제품 경쟁은 에이전트 오케스트레이션으로 이동했다.
Claude Fable 5를 직접 써보고 싶은 독자는 Claude Fable 5 on OneHop에서 사용할 수 있다. 정가보다 약 30% 낮은 가격의 drop-in endpoint다. 신규 계정은 카드 없이도 $10 무료로 시작할 수 있다.
더 읽기: Claude Fable 5 시작하기.

