El 28 de mayo de 2026, Anthropic lanzó Claude Opus 4.8 con tres cambios orientados a desarrolladores que importan más que el nombre del modelo: Claude Code recibió flujos de trabajo dinámicos, los usuarios obtuvieron niveles de esfuerzo seleccionables, y el modo rápido de Opus pasó a ser 2,5 veces más veloz con un precio de 10 dólares por millón de tokens de entrada y 50 dólares por millón de tokens de salida, lo que según Anthropic es tres veces más barato que el modo rápido en modelos Opus anteriores (Anthropic).
Esa es la historia de verdad. El titular no es “Claude venció a GPT en otro gráfico”. El titular es que Anthropic está intentando sacar a los agentes de programación de la caja del chat único.
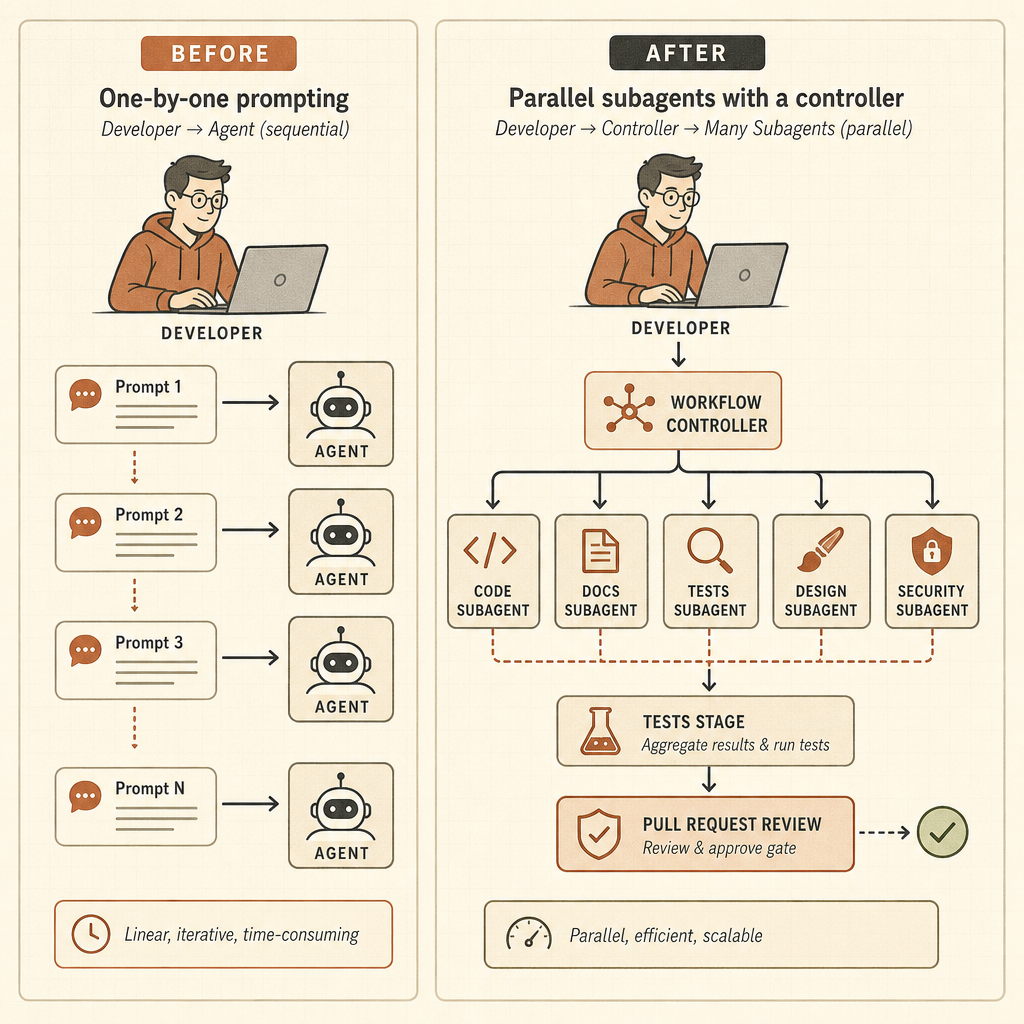
El bucle anterior era simple: prompt, esperar, revisar el diff, volver a pedir. Opus 4.8 apunta a otro bucle: asignar un objetivo, dejar que el sistema divida el trabajo entre subagentes, mantener el estado fuera de la conversación principal, verificar resultados y volver con una respuesta coordinada. Eso cambia el trabajo del desarrollador: de escribir prompts a operar agentes.
La mejora en benchmarks es real, pero no es el foso defensivo
Opus 4.8 es más fuerte que Opus 4.7. Anthropic dice que mejora en programación, habilidades agénticas, razonamiento y trabajo profesional, con el precio regular de la API sin cambios: 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida (Anthropic). La empresa también afirma que el modelo tiene unas cuatro veces menos probabilidades que Opus 4.7 de dejar pasar fallos en su propio código sin señalarlos.
Las cifras de la system card dejan clara la posición. En SWE-bench Pro, Opus 4.8 aparece con 69,2%, por delante de Opus 4.7 con 64,3%, GPT-5.5 con 58,6% y Gemini 3.1 Pro con 54,2%, según resúmenes publicados de los datos de la system card de Opus 4.8 de Anthropic (Vellum, PDF de la system card de Anthropic). En Terminal-Bench 2.1, la historia es más enredada: GPT-5.5 lidera en el mismo harness Terminus-2 con 78,2%, mientras que Opus 4.8 queda en 74,6%. Anthropic también señala que la puntuación reportada de GPT-5.5 en el harness Codex CLI es 83,4%, un recordatorio útil de que los benchmarks de agentes miden el modelo más el harness, no inteligencia pura metida en un frasco (Anthropic).
| Benchmark | Claude Opus 4.8 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | n/a en la tabla de Anthropic | 80.6% |
| Terminal-Bench 2.1, Terminus-2 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE con herramientas | 57.9% | 54.7% | 52.2% | 51.4% |
Lee esa tabla como ingeniero, no como fan. Opus 4.8 es un lanzamiento importante. También está lejos de ser un nocaut limpio. OpenAI aún tiene una historia creíble de agentes de terminal alrededor de GPT-5.5, que OpenAI presentó en clave de IA agéntica y trabajo real cuando lanzó el modelo en abril (OpenAI). Gemini 3.1 Pro de Google, lanzado el 19 de febrero de 2026, también se posicionó alrededor de un razonamiento más fuerte y una amplia disponibilidad en las superficies de Google (Google).
Entonces, ¿por qué Opus 4.8 se siente estratégicamente distinto? Porque Anthropic está vendiendo el modelo operativo, no solo el modelo.
Los flujos de trabajo dinámicos convierten Claude Code en un runtime
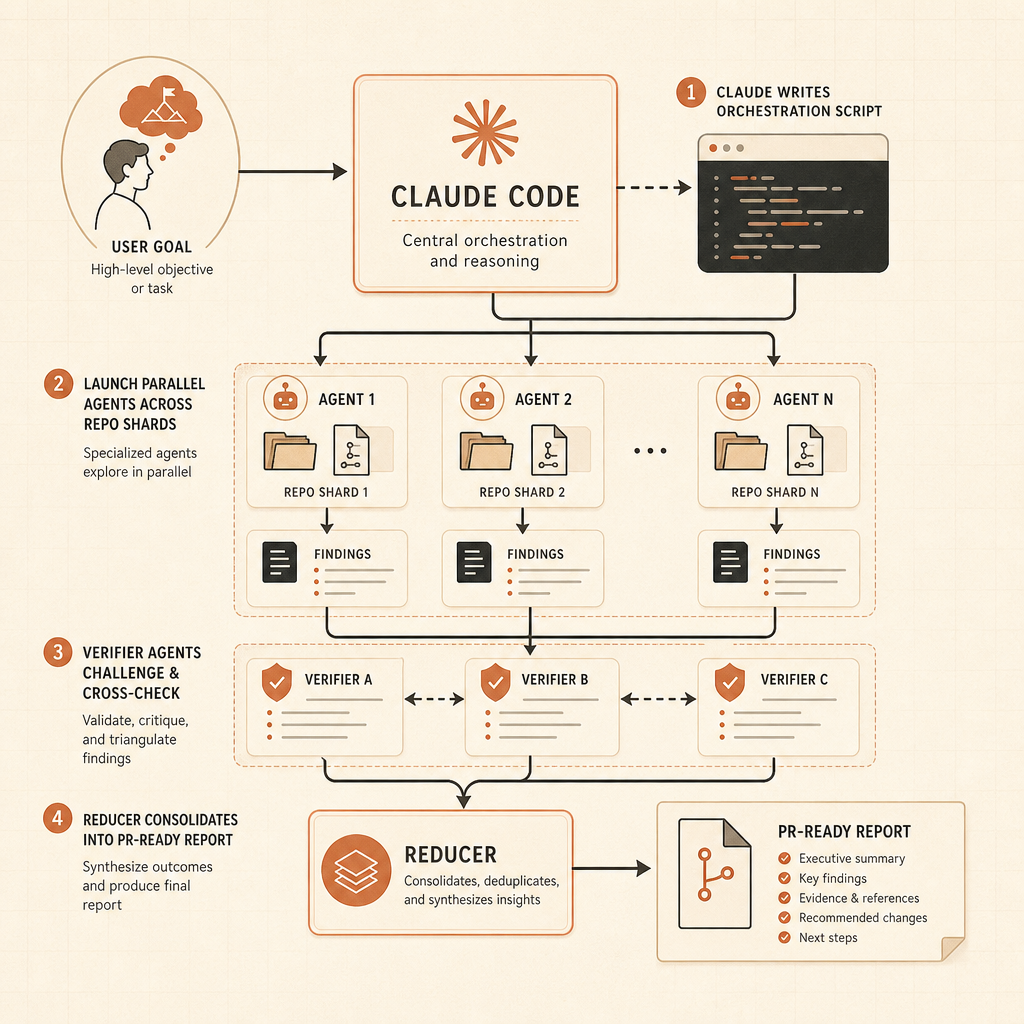
Los flujos de trabajo dinámicos son el filo del lanzamiento. La publicación de Anthropic sobre Claude Code dice que Claude puede escribir scripts de orquestación que ejecutan “decenas a cientos” de subagentes en paralelo en una sola sesión, revisan su trabajo y devuelven un resultado coordinado (Claude). Los ejemplos no son prompts de juguete: búsquedas de bugs en toda una base de código, auditorías de optimización guiadas por profiler, auditorías de seguridad, grandes migraciones, modernización y revisión adversarial.
El ejemplo de Bun es el tipo de afirmación que los desarrolladores van a recordar. Anthropic dice que Jarred Sumner usó flujos de trabajo dinámicos para portar Bun de Zig a Rust con el 99,8% de la suite de pruebas existente pasando, unas 750.000 líneas de Rust y once días desde el primer commit hasta el merge (Claude). Eso no significa que cualquier equipo pueda tirarle un monolito legacy a Claude e irse a comer. Sí significa que Anthropic está diseñando explícitamente para trabajos que superan una sola ventana de contexto y una sola traza de agente.
Un prompt razonable ahora se parece menos a “arregla este bug” y más a una especificación de trabajo para un sistema interno de automatización:
Create a dynamic workflow to audit this repo for unsafe auth bypasses.
Split by service boundary, require two independent reviewers per finding,
run relevant tests, and return only confirmed issues with file paths,
risk level, repro steps, and a minimal patch plan.Es una habilidad distinta. El desarrollador tiene que definir alcance, presupuestos, permisos, puertas de verificación y comportamiento de rollback. El modelo mental útil ya no es la programación en pareja. Es gestionar un equipo de ingeniería pequeño, rápido, irregular, que nunca duerme y a veces entiende mal el ticket.
Los niveles de esfuerzo convierten el cómputo en una perilla de producto
Es fácil subestimar el selector de esfuerzo. Anthropic dice que Opus 4.8 usa por defecto esfuerzo alto; los usuarios pueden elegir “extra” o xhigh en Claude Code, además de max, y los niveles más altos gastan más tokens para obtener mejores resultados (Anthropic). La documentación de la Claude API describe xhigh como apropiado para programación avanzada y trabajo agéntico complejo con llamadas repetidas a herramientas y búsqueda detallada, y aclara que el ultracode de Claude Code no es un nivel de esfuerzo separado de la API. Lo empareja con permiso para lanzar flujos de trabajo multiagente (Anthropic Docs).
Esto es Anthropic admitiendo algo que los desarrolladores ya aprendieron por las malas y pagando caro: “el mejor modelo” es la abstracción equivocada. La pregunta correcta es: ¿cuánta búsqueda, uso de herramientas, verificación y paralelismo debería comprar esta tarea?
Arreglar un typo no debería lanzar cien agentes. Una migración de auth entre servicios quizá los necesite. Una investigación de tests flaky puede ser perfecta para hipótesis en paralelo. Un cambio de copy en la UI no.
El modo rápido encaja con la misma tesis. El precio estándar de Opus 4.8 no cambia: 5/25 dólares por millón de tokens, mientras que el modo rápido cuesta 10/50 dólares y corre a 2,5 veces la velocidad (Anthropic). Eso no es “Claude barato”. Es una prima de latencia. Anthropic redujo lo suficiente la prima anterior del modo rápido para que los equipos puedan empezar a tratar la velocidad como una decisión operativa, no como un ajuste de lujo.
La comparación con OpenAI y Gemini va de superficies
OpenAI, Google y Anthropic persiguen todos puntuaciones de modelos frontier. Nadie puede bajarse de esa carrera. Los compradores todavía preguntan quién lidera SWE-bench, GPQA, HLE, OSWorld y evaluaciones internas. Las presentaciones de procurement todavía necesitan un gráfico.
Pero la carrera de herramientas para desarrolladores está pasando de “¿qué modelo responde mejor?” a “¿qué entorno permite que el modelo siga trabajando de forma segura?”.
El posicionamiento tipo Codex de OpenAI es fuerte en ejecución de terminal, interacción con repositorios y trabajo de programación con harness. La ventaja de GPT-5.5 en Terminal-Bench es una advertencia para Anthropic: en fiabilidad de terminal de bajo nivel, el CLI y el harness de ejecución alrededor del modelo pueden superar diferencias brutas de benchmark. La ventaja de Google es la distribución. Los modelos Gemini llegan a la app Gemini, AI Studio, Vertex AI, superficies tipo Workspace y flujos cercanos a Android. Eso hace que Gemini sea difícil de ignorar incluso cuando un modelo rival gana en un gráfico de programación.
La respuesta de Anthropic es más estrecha y más opinada: Claude Code debería convertirse en el lugar donde el trabajo de ingeniería de larga duración se planifica, se despliega en abanico, se revisa, se retoma y se evalúa. La página de Opus describe el modelo como construido para programación seria y agentes de IA, con una ventana de contexto de 1M y disponibilidad en Claude Platform, AWS, Google Cloud y Microsoft Foundry (Anthropic). Los flujos de trabajo dinámicos llevan eso del marketing de modelo a la arquitectura de producto.

El flujo de trabajo del desarrollador cambia de cuatro formas prácticas
Primero, la planificación se vuelve más importante. Un flujo de trabajo dinámico amplifica la instrucción inicial. Un prompt vago puede gastar más tokens, tocar más archivos y producir un desastre más grande. Los mejores usuarios escribirán tickets con límites explícitos: directorios dentro del alcance, tests a ejecutar, APIs que no deben cambiar y definiciones de terminado.
Segundo, la verificación se convierte en un artefacto de primera clase. Anthropic dice que los flujos de trabajo pueden usar intentos independientes y agentes adversariales para romper un resultado antes de que el usuario lo vea (Claude). Ese es el patrón correcto. La salida de un agente debería llegar con evidencia: logs de tests, resultados de grep, deltas de benchmarks y riesgos no resueltos.
Tercero, el coste pasa de ruido de fondo invisible a arquitectura. Los flujos de trabajo dinámicos pueden consumir bastante más uso que una sesión típica de Claude Code, y Anthropic recomienda explícitamente empezar con tareas acotadas (Claude). Los equipos necesitarán reglas internas: cuándo usar esfuerzo alto, cuándo usar xhigh, cuándo permitir flujos de trabajo y cuándo obligar primero a una revisión humana de diseño.
Cuarto, el rol del ingeniero senior sube de nivel. Menos tiempo revisando manualmente cada referencia. Más tiempo diseñando el harness: mapas del repo, comandos de test, modos de permisos, estrategia de ramas, puertas de CI y prompts de revisión. Las mejores configuraciones de programación con IA se parecerán a pequeñas plataformas internas, no a colecciones ingeniosas de prompts.
La apuesta de Anthropic: gana el gestor de agentes
Opus 4.8 es un buen lanzamiento de modelo. El lanzamiento más interesante es el plano de control que lo rodea.
Anthropic apuesta a que la inteligencia frontier estará lo bastante pareja entre los principales laboratorios como para que la lealtad de los desarrolladores venga de la orquestación: qué tan bien descompone el sistema el trabajo, ejecuta agentes en paralelo, gestiona contexto, pide confirmación, verifica afirmaciones y expone suficiente estado para que los humanos confíen en él. Los benchmarks siguen importando. Deciden quién entra en la evaluación. Los flujos de trabajo deciden quién se queda en el día a día.
Es la apuesta correcta. El próximo salto en productividad de desarrolladores no vendrá de pedirle a un único agente que sea un poco más inteligente en un solo turno. Vendrá de darles a modelos capaces un runtime que se parezca a cómo ocurre el trabajo real de ingeniería: investigación en paralelo, implementación por etapas, revisión independiente, tests y rollback.
Opus 4.8 es Anthropic diciendo en voz alta lo que antes se decía en voz baja. La carrera de modelos continúa, pero la carrera de producto se ha movido a la orquestación de agentes.
Los lectores que quieran probar Claude Fable 5 por su cuenta pueden usarlo a través de Claude Fable 5 en OneHop, un endpoint drop-in con un precio alrededor de un 30% por debajo del precio de lista. Las cuentas nuevas pueden empezar con 10 dólares gratis, sin tarjeta.
Lectura adicional: Primeros pasos con Claude Fable 5.

