
Claude prompt caching 有一个很漂亮的数字,也有一个很容易踩的坑:缓存读取只要正常输入成本的 0.1×,但缓存写入比正常输入更贵。Anthropic 当前文档列出的价格是:5 分钟缓存写入为输入价格的 1.25×,1 小时写入为 2×,活跃 Claude 模型的缓存命中都是 0.1×(Anthropic prompt caching docs)。
这意味着缓存不只是延迟优化功能,也是定价功能。如果你的应用会反复使用很长的 system prompt、工具 schema、示例包、策略包、检索到的文档,或多轮状态,那你就应该像衡量输出 token 一样,衡量缓存写入和读取。
截至今天,也就是 2026 年 6 月 14 日,还有一个小变数:Anthropic 在 6 月 9 日发布了 Claude Fable 5,随后在 6 月 12 日更新称,Fable 5 和 Mythos 5 的访问已暂停,他们正在恢复访问(Anthropic)。OneHop 也列出了 anthropic/claude-fable-5,并标注支持 prompt cache,但目前在模型页面上显示暂时不可用(OneHop)。现在先把集成做好,把模型 id 做成可配置,等访问恢复后再打开。
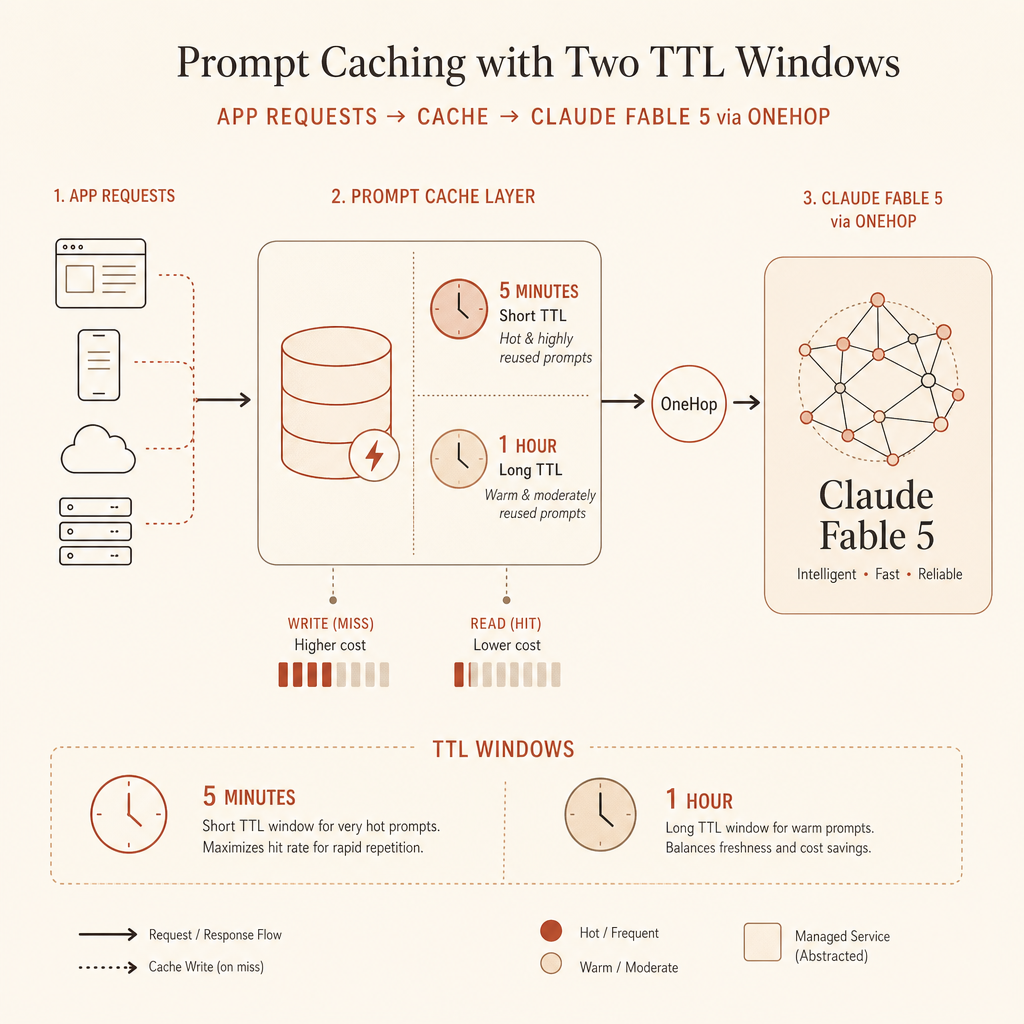
开发者真正需要的缓存算账方式
Anthropic 的 prompt cache 存的是 prompt 前缀。可复用的部分必须完全一致:tools、system 内容和 messages 会按这个顺序处理,缓存会应用到标有 cache_control 的 block 为止(Anthropic prompt caching docs)。
有用的计价模型很简单。假设你的可复用前缀是 100,000 个输入 token。
| 缓存模式 | 写入成本倍数 | 读取成本倍数 | 回本直觉 |
|---|---|---|---|
| 不缓存 | 每次请求 1.0× | 无 | 每次都付完整输入成本 |
| 5 分钟缓存 | 一次 1.25× | 每次命中 0.1× | 第一次复用后就回本 |
| 1 小时缓存 | 一次 2.0× | 每次命中 0.1× | 需要更多复用,或更长的空闲间隔 |
对于 Claude Fable 5,Anthropic 在发布文章中列出的价格是每百万输入 token 10 美元、每百万输出 token 50 美元;prompt caching 文档中列出的 Fable 5 缓存价格是:5 分钟写入 $12.50/M,1 小时写入 $20/M,缓存命中 $1/M(Anthropic, prompt caching docs)。
按 Anthropic 标价计算,这个 100k-token 前缀的成本是:
- 正常输入:
$1.00 - 5 分钟写入:
$1.25 - 1 小时写入:
$2.00 - 缓存读取:
$0.10
所以,如果同一个 100k-token 前缀在 TTL 内用了两次,5 分钟缓存成本是 $1.25 + $0.10 = $1.35,而不缓存是 $2.00。1 小时缓存两次使用的成本是 $2.10,所以两次调用时它不划算;但只要有第三次调用,或者它帮你避开了一次较长暂停后的冷写入,它就赢了。
这就是我在生产里用的规则:热循环默认 5 分钟;人会停下来、agent 要等工具,或工作流几分钟后恢复时,用 1 小时。
开启缓存的两种方式
Anthropic 现在记录了两种做法。最快的路径是自动缓存:加一个顶层 cache_control 字段,Claude 会随着对话增长自动把断点往前推进。控制更精细的路径是显式断点:把 cache_control 放在稳定前缀里最后一个 content block 上(Anthropic prompt caching docs)。
自动缓存很适合聊天历史和 agent 状态:
import os
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://api.onehop.ai/v1"),
)
message = client.messages.create(
model=os.getenv("CLAUDE_MODEL", "anthropic/claude-fable-5"),
max_tokens=700,
cache_control={"type": "ephemeral"},
system="You are a senior backend engineer. Be concise and specific.",
messages=[
{"role": "user", "content": "My app uses FastAPI, Postgres, and Redis."},
{"role": "assistant", "content": "Got it. What do you want to change?"},
{"role": "user", "content": "Design a cache key strategy for user dashboards."},
],
)
print(message.content[0].text)
print(message.usage.model_dump())这就是 OneHop 的迁移路径:保留 Anthropic 风格的请求,把 base URL 做成可配置,然后指向 https://api.onehop.ai/v1。OneHop 的模型页面也显示 anthropic/claude-fable-5 是模型 id,并称新用户无需绑卡即可获得 10 美元免费额度(OneHop)。如果你想走最短路径,可以打开 OneHop 上的 Claude Fable 5,然后用 10 美元免费额度开始。
当你的前缀稳定、但每次请求的用户消息都变化时,显式缓存更好。把断点放在变化部分之前:
from anthropic import Anthropic
import os
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/v1",
)
response = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=500,
system=[
{
"type": "text",
"text": open("system_prompt.md").read(),
"cache_control": {"type": "ephemeral"},
}
],
messages=[
{"role": "user", "content": "Review this migration plan for race conditions."}
],
)
print(response.usage.model_dump())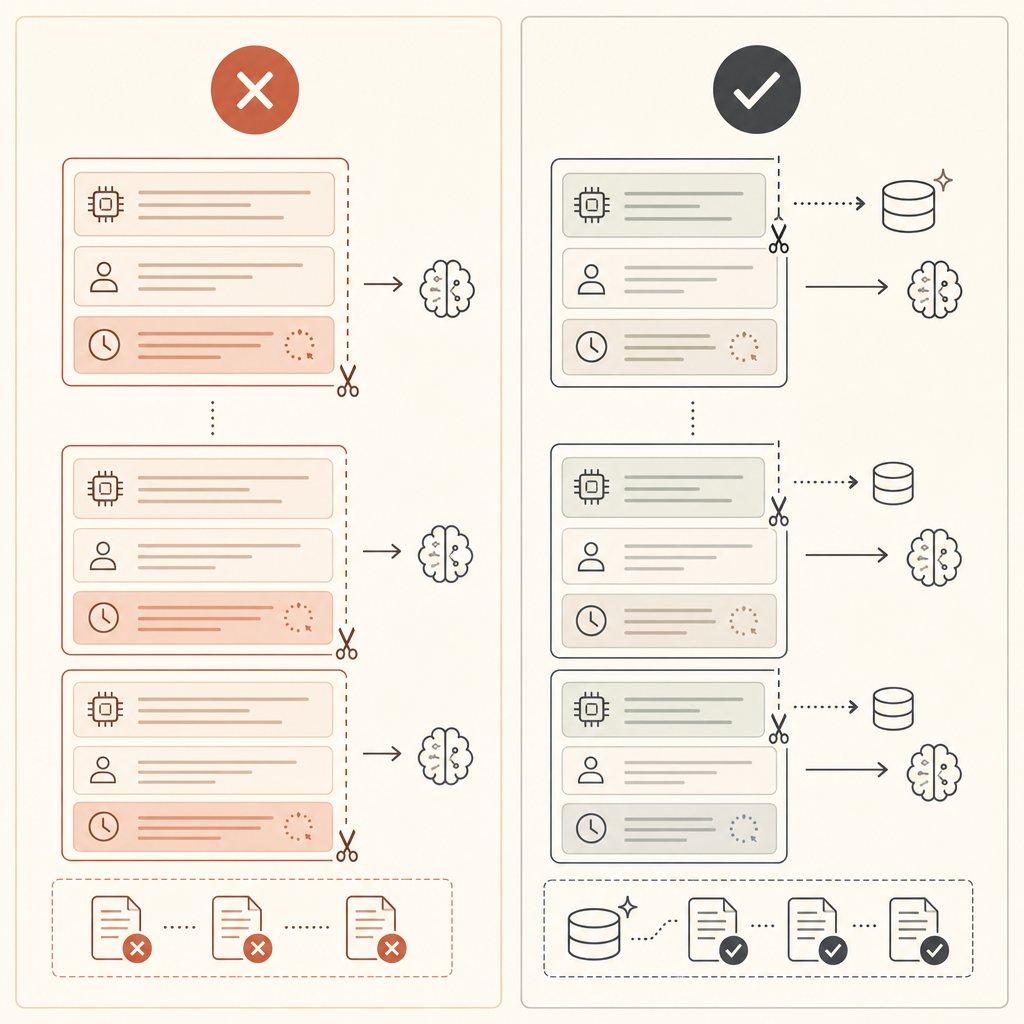
带 1 小时 TTL 的 TypeScript 版本
当应用有昂贵的静态上下文,并且现实中确实会出现空闲间隔时,使用 1 小时缓存。比如:等待 CI 的代码审查 agent、人会暂停的客服 copilot、法律研究会话,或工具需要跑好几分钟的多步骤数据分析。
Anthropic 文档把 1 小时 TTL 写作 {"type":"ephemeral","ttl":"1h"},并说明自动缓存默认使用 5 分钟(Anthropic prompt caching docs)。
import Anthropic from "@anthropic-ai/sdk";
import fs from "node:fs";
const client = new Anthropic({
apiKey: process.env.ONEHOP_API_KEY!,
baseURL: process.env.ANTHROPIC_BASE_URL ?? "https://api.onehop.ai/v1",
});
const policyPack = fs.readFileSync("policy-pack.md", "utf8");
const msg = await client.messages.create({
model: process.env.CLAUDE_MODEL ?? "anthropic/claude-fable-5",
max_tokens: 800,
system: [
{
type: "text",
text: policyPack,
cache_control: { type: "ephemeral", ttl: "1h" },
},
],
messages: [
{
role: "user",
content: "Apply the policy pack to this refund request: customer used 3 of 10 seats.",
},
],
});
console.log(msg.content);
console.log(msg.usage);重点很无聊:别把模型和 base URL 深埋在代码里。两者都放进环境变量。今天 Fable 5 的可用性还在变化;你的集成应该能回退到另一个活跃 Claude 模型,而不是非得改业务逻辑。
usage 里该监控什么
Prompt caching 在你检查 usage 字段之前是看不见的。Anthropic 说,验证缓存要看 cache_creation_input_tokens 和 cache_read_input_tokens 等字段;如果两者都是 0,说明 prompt 没有被缓存,常见原因是没达到该模型的最小可缓存长度(Anthropic prompt caching docs)。
每次请求都记录这些:
const usage = msg.usage;
console.log({
input: usage.input_tokens,
output: usage.output_tokens,
cacheCreate: usage.cache_creation_input_tokens,
cacheRead: usage.cache_read_input_tokens,
});对于更新的 usage 对象,Anthropic 文档还展示了按 TTL 拆分的缓存创建桶,例如 ephemeral_5m_input_tokens 和 ephemeral_1h_input_tokens。一开始先捕获完整 usage 对象。等你确认自己实际运行的是哪个网关和 SDK 版本,再做归一化。
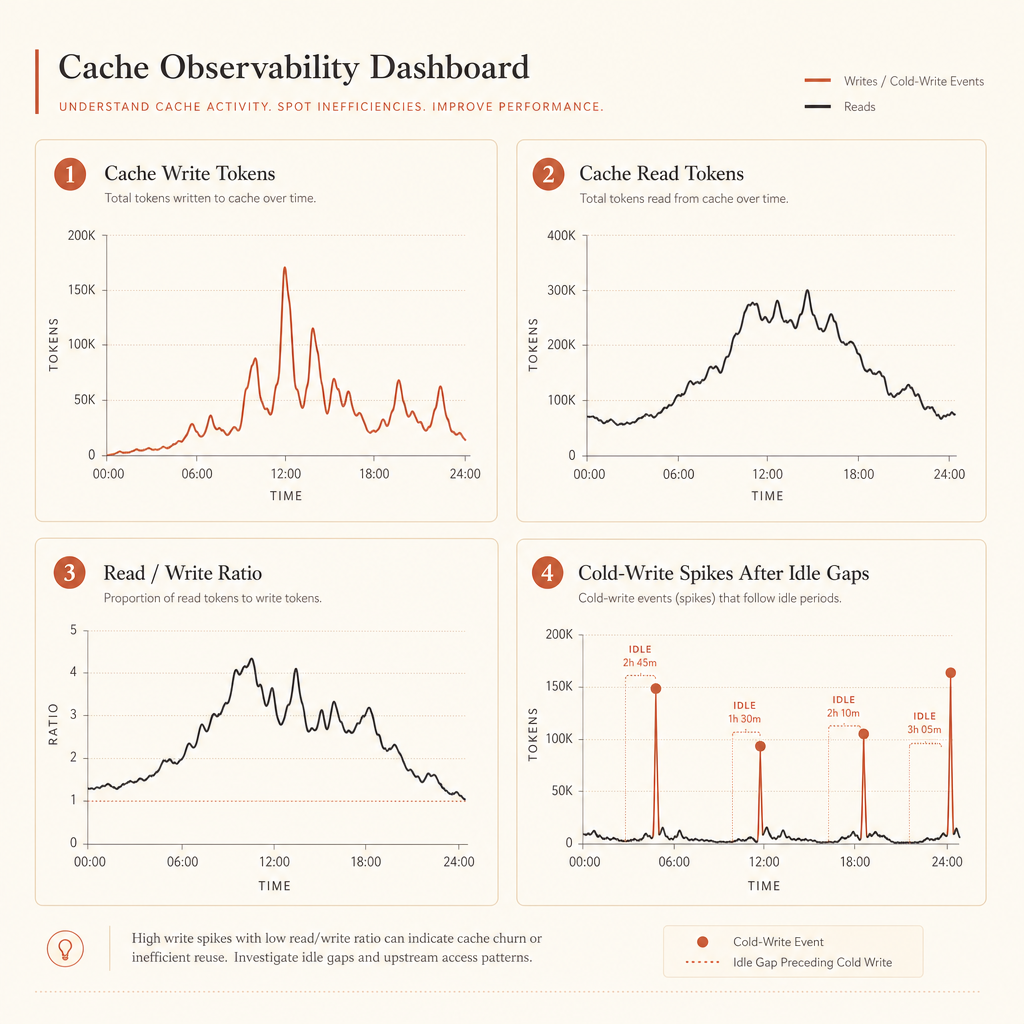
好的仪表盘要回答四个问题:
- 有多少 token 被写入缓存?
- 有多少 token 从缓存读取?
- 按 route 看,缓存读写比是多少?
- 哪些 prompt 会在空闲间隔后产生很大的冷写入?
如果 cache_creation_input_tokens 很高,而 cache_read_input_tokens 一直接近 0,你的断点很可能放在变化内容之后了。把它往前移。
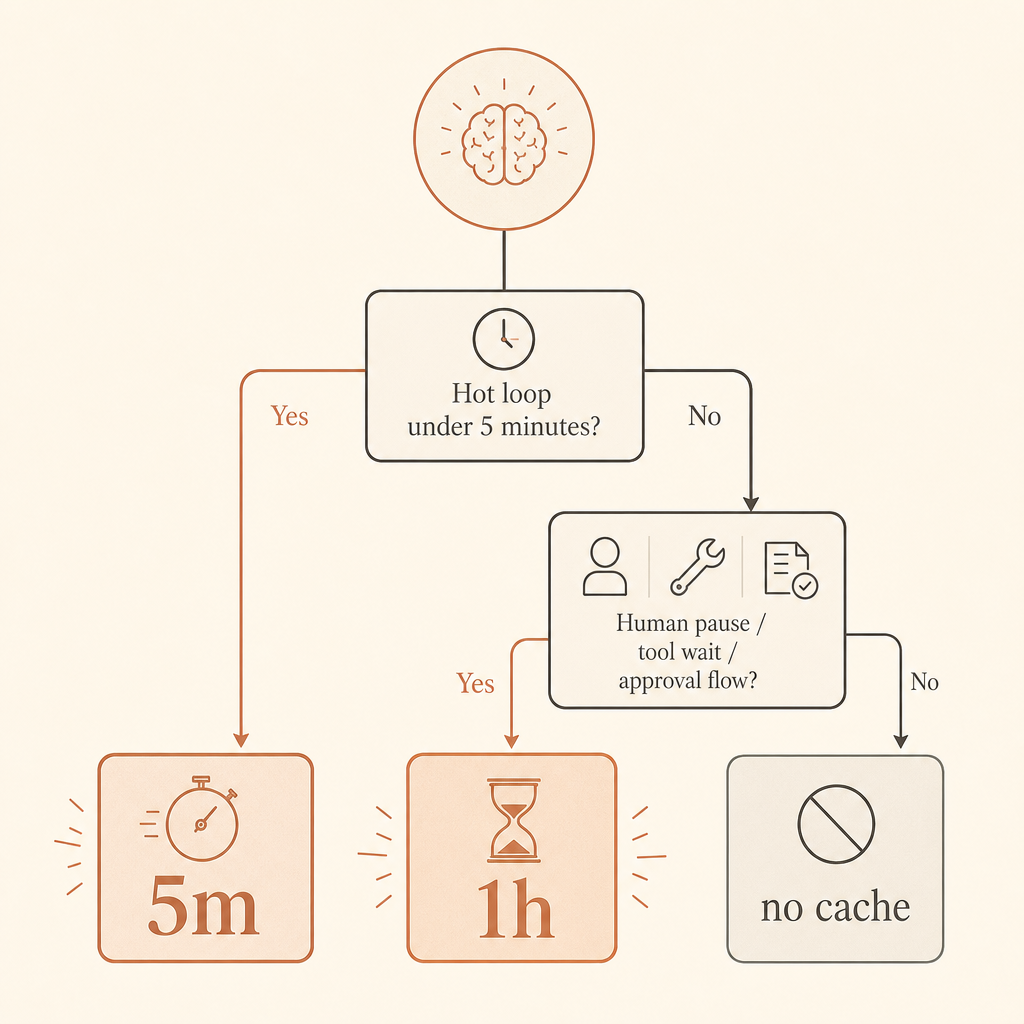
5 分钟还是 1 小时:按用户行为选
紧密请求循环用 5 分钟缓存。每 20 秒调用一次工具的编码 agent、用户很快追问的聊天应用,或一批相似分类任务,都应该从这里开始。根据 Anthropic 文档,写入溢价只有 1.25×,而且每次读取都会免费刷新缓存生命周期(Anthropic prompt caching docs)。
当昂贵前缀很可能在五分钟之后再次被复用时,用 1 小时缓存。Human-in-the-loop 工作流是典型场景。长时间运行的 agent 也是:模型把任务交给外部系统,等待浏览器,轮询 CI,或暂停等审批。
不要缓存很小的 prompt。Anthropic 记录了不同模型和平台的最小可缓存 prompt 长度;对 Fable 5 来说,Claude API 的最小值列为 512 token,而 Bedrock 上某些模型有不同的最小值(Anthropic prompt caching docs)。更短的 prompt 可能只是正常处理,不会缓存。
实用清单:
- 把稳定内容放前面:tools、system prompts、示例、参考文档。
- 把变化数据放在缓存前缀之后:时间戳、请求 id、用户文本。
- 对话场景先用自动缓存。
- 当你的后缀每次调用都会变化时,切到显式断点。
- 只有当空闲间隔能证明 2× 写入值得时,才使用 1 小时 TTL。
- 先记录 usage 字段,再宣布胜利。
通过 OneHop 接好,然后测量
最干净的集成就是改一行 endpoint,再用环境变量配置模型选择:
export ONEHOP_API_KEY="..."
export ANTHROPIC_BASE_URL="https://api.onehop.ai/v1"
export CLAUDE_MODEL="anthropic/claude-fable-5"然后保留你的 Anthropic Messages 代码,加上 cache_control。
OneHop 的 Fable 5 页面目前展示了低于官方标价的价格、无需绑卡的 10 美元入门额度,以及该模型的 Anthropic Messages 路由(OneHop)。由于根据 Anthropic 6 月 12 日更新,Fable 5 访问暂时暂停,把模型回退做成发布计划的一部分,而不是事后补丁。
收益很直接。如果你的应用会重复大前缀,0.1× 的缓存读取会把 prompt engineering 变成成本工程。先从 5 分钟缓存开始。日志显示暂停后出现冷重写时,再把选定工作流迁到 1 小时缓存。如果你想在 Claude Fable 5 恢复可用后走最短路径,可以试试 OneHop 上的 Claude Fable 5,并用 10 美元免费额度开始。

