
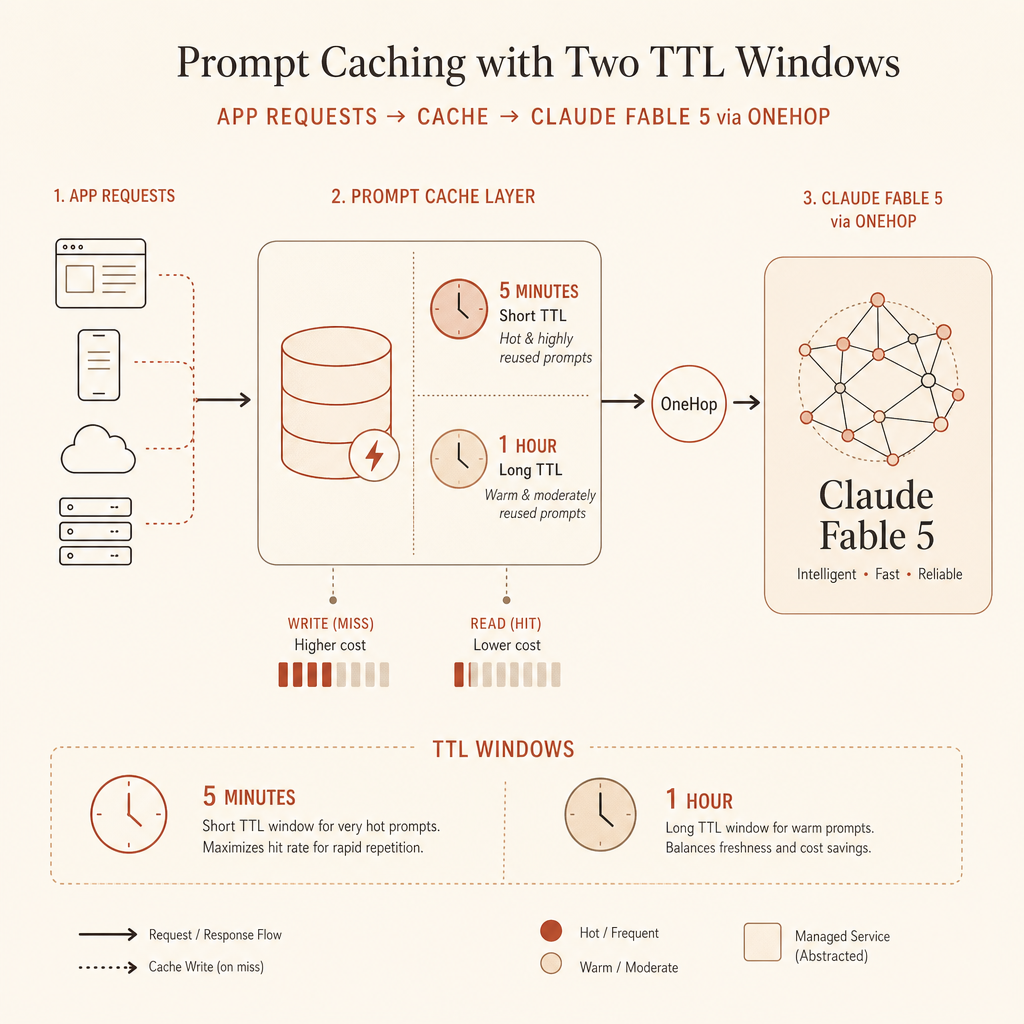
El prompt caching de Claude tiene una cifra preciosa y una trampa muy fácil: las lecturas de caché cuestan 0.1× de la entrada normal, pero las escrituras de caché cuestan más que la entrada normal. La documentación actual de Anthropic lista las escrituras de caché de 5 minutos a 1.25× el precio de entrada, las escrituras de 1 hora a 2×, y los aciertos de caché a 0.1× en los modelos Claude activos (documentación de prompt caching de Anthropic).
Eso convierte la caché en una función de precio, no solo de latencia. Si tu app repite un prompt de sistema largo, un esquema de herramientas, un paquete de ejemplos, un bloque de políticas, documentos recuperados o estado multi-turno, deberías medir escrituras y lecturas de caché igual que mides tokens de salida.
Un matiz a día de hoy, 14 de junio de 2026: Anthropic lanzó Claude Fable 5 el 9 de junio, y luego publicó una actualización el 12 de junio diciendo que el acceso a Fable 5 y Mythos 5 quedaba suspendido mientras trabajan para restaurarlo (Anthropic). OneHop también lista anthropic/claude-fable-5, con soporte de prompt cache, pero ahora mismo lo marca como temporalmente no disponible en su página del modelo (OneHop). Construye la integración ya, mantén configurable el id del modelo y actívala cuando el acceso vuelva a estar disponible.
La matemática de caché que los desarrolladores sí necesitan
La prompt cache de Anthropic almacena prefijos de prompts. La parte reutilizable debe ser idéntica: herramientas, contenido de sistema y mensajes se consideran en ese orden, y la caché se aplica hasta el bloque marcado con cache_control (documentación de prompt caching de Anthropic).
El modelo de precios útil es sencillo. Supón que tu prefijo reutilizable tiene 100,000 tokens de entrada.
| Modo de caché | Multiplicador de coste de escritura | Multiplicador de coste de lectura | Intuición del punto de equilibrio |
|---|---|---|---|
| Sin caché | 1.0× en cada solicitud | ninguno | Pagas la entrada completa cada vez |
| Caché de 5 minutos | 1.25× una vez | 0.1× por acierto | Sale a cuenta tras la primera reutilización |
| Caché de 1 hora | 2.0× una vez | 0.1× por acierto | Necesita más reutilización o pausas más largas |
Para Claude Fable 5, Anthropic lista $10 por millón de tokens de entrada y $50 por millón de tokens de salida en el post de lanzamiento, y la documentación de prompt caching lista los precios de caché de Fable 5 como $12.50/M para escrituras de 5 minutos, $20/M para escrituras de 1 hora y $1/M para aciertos de caché (Anthropic, documentación de prompt caching).
Usando los precios de lista de Anthropic, ese prefijo de 100k tokens cuesta:
- Entrada normal:
$1.00 - Escritura de 5 minutos:
$1.25 - Escritura de 1 hora:
$2.00 - Lectura de caché:
$0.10
Así que si el mismo prefijo de 100k tokens se usa dos veces dentro del TTL, la caché de 5 minutos cuesta $1.25 + $0.10 = $1.35, frente a $2.00 sin caché. La caché de 1 hora cuesta $2.10 para dos usos, así que pierde con dos llamadas, pero gana cuando tienes una tercera llamada o evitas una reescritura fría tras una pausa más larga.
Esa es la regla que uso en producción: 5 minutos por defecto para bucles calientes; 1 hora cuando las personas hacen pausas, los agentes esperan a herramientas o los flujos se reanudan tras varios minutos.
Dos formas de activar la caché
Anthropic documenta ahora dos enfoques. El camino más rápido es la caché automática: añade un campo cache_control de nivel superior y Claude mueve el punto de corte hacia delante a medida que la conversación crece. El camino con más control son los puntos de corte explícitos: pon cache_control en el último bloque de contenido del prefijo estable (documentación de prompt caching de Anthropic).
La caché automática va genial para historial de chat y estado de agentes:
import os
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://api.onehop.ai/v1"),
)
message = client.messages.create(
model=os.getenv("CLAUDE_MODEL", "anthropic/claude-fable-5"),
max_tokens=700,
cache_control={"type": "ephemeral"},
system="You are a senior backend engineer. Be concise and specific.",
messages=[
{"role": "user", "content": "My app uses FastAPI, Postgres, and Redis."},
{"role": "assistant", "content": "Got it. What do you want to change?"},
{"role": "user", "content": "Design a cache key strategy for user dashboards."},
],
)
print(message.content[0].text)
print(message.usage.model_dump())Ese es el camino de conversión a OneHop: conserva tu solicitud estilo Anthropic, haz configurable la base URL y apúntala a https://api.onehop.ai/v1. La página del modelo de OneHop también muestra anthropic/claude-fable-5 como id del modelo y dice que los usuarios nuevos reciben $10 de crédito gratis sin tarjeta (OneHop). Si quieres la ruta corta, abre Claude Fable 5 en OneHop y empieza con $10 gratis.
La caché explícita es mejor cuando el prefijo es estable pero el mensaje del usuario cambia en cada solicitud. Pon el punto de corte antes de la parte que cambia:
from anthropic import Anthropic
import os
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/v1",
)
response = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=500,
system=[
{
"type": "text",
"text": open("system_prompt.md").read(),
"cache_control": {"type": "ephemeral"},
}
],
messages=[
{"role": "user", "content": "Review this migration plan for race conditions."}
],
)
print(response.usage.model_dump())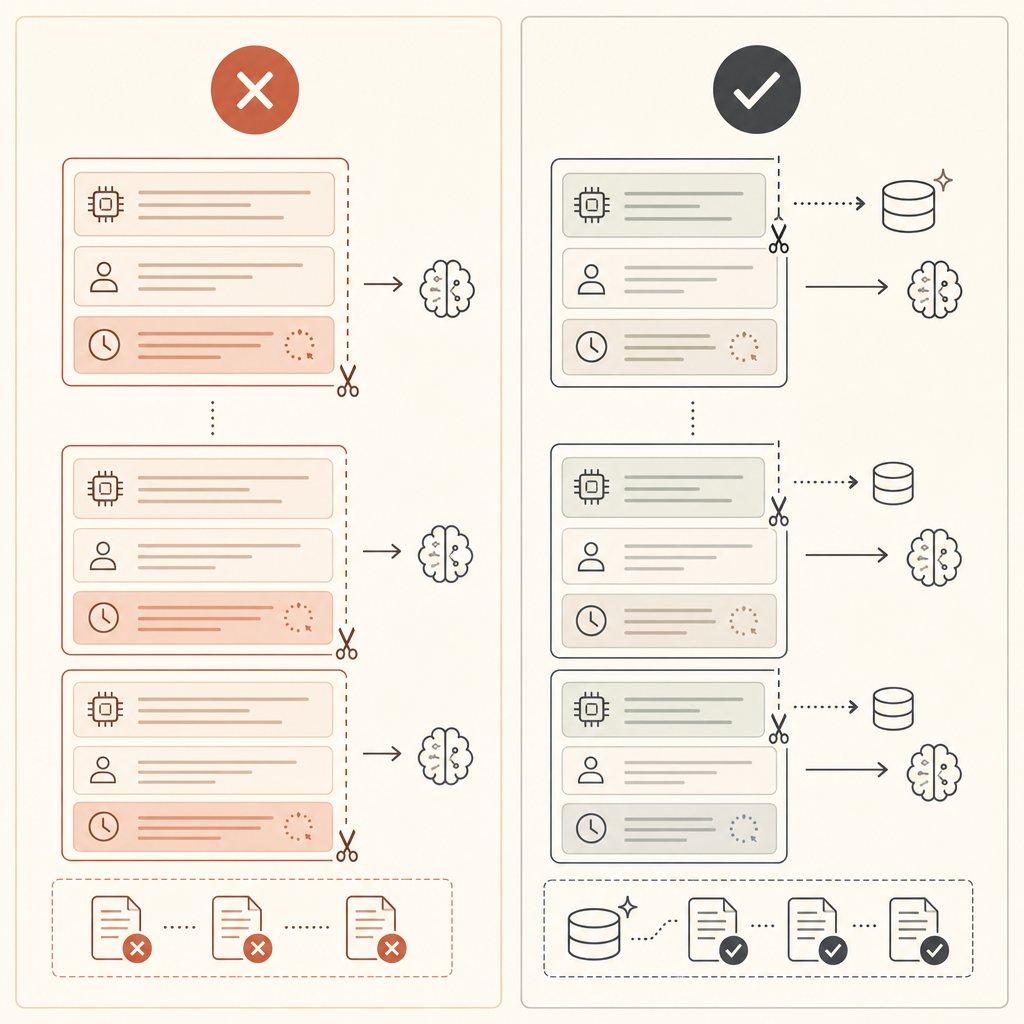
Versión TypeScript con un TTL de 1 hora
Usa caché de 1 hora cuando la app tenga contexto estático caro y pausas realistas. Piensa en agentes de revisión de código esperando a CI, copilotos de atención al cliente donde las personas se detienen, sesiones de investigación legal o análisis de datos de varios pasos donde las herramientas tardan varios minutos.
La documentación de Anthropic muestra el TTL de 1 hora como {"type":"ephemeral","ttl":"1h"} y afirma que la caché automática usa 5 minutos por defecto (documentación de prompt caching de Anthropic).
import Anthropic from "@anthropic-ai/sdk";
import fs from "node:fs";
const client = new Anthropic({
apiKey: process.env.ONEHOP_API_KEY!,
baseURL: process.env.ANTHROPIC_BASE_URL ?? "https://api.onehop.ai/v1",
});
const policyPack = fs.readFileSync("policy-pack.md", "utf8");
const msg = await client.messages.create({
model: process.env.CLAUDE_MODEL ?? "anthropic/claude-fable-5",
max_tokens: 800,
system: [
{
type: "text",
text: policyPack,
cache_control: { type: "ephemeral", ttl: "1h" },
},
],
messages: [
{
role: "user",
content: "Apply the policy pack to this refund request: customer used 3 of 10 seats.",
},
],
});
console.log(msg.content);
console.log(msg.usage);La parte importante es aburrida: no escondas el modelo y la base URL en lo profundo del código. Mantén ambos en variables de entorno. La disponibilidad actual de Fable 5 está cambiando; tu integración debería poder caer a otro modelo Claude activo sin tocar la lógica de negocio.
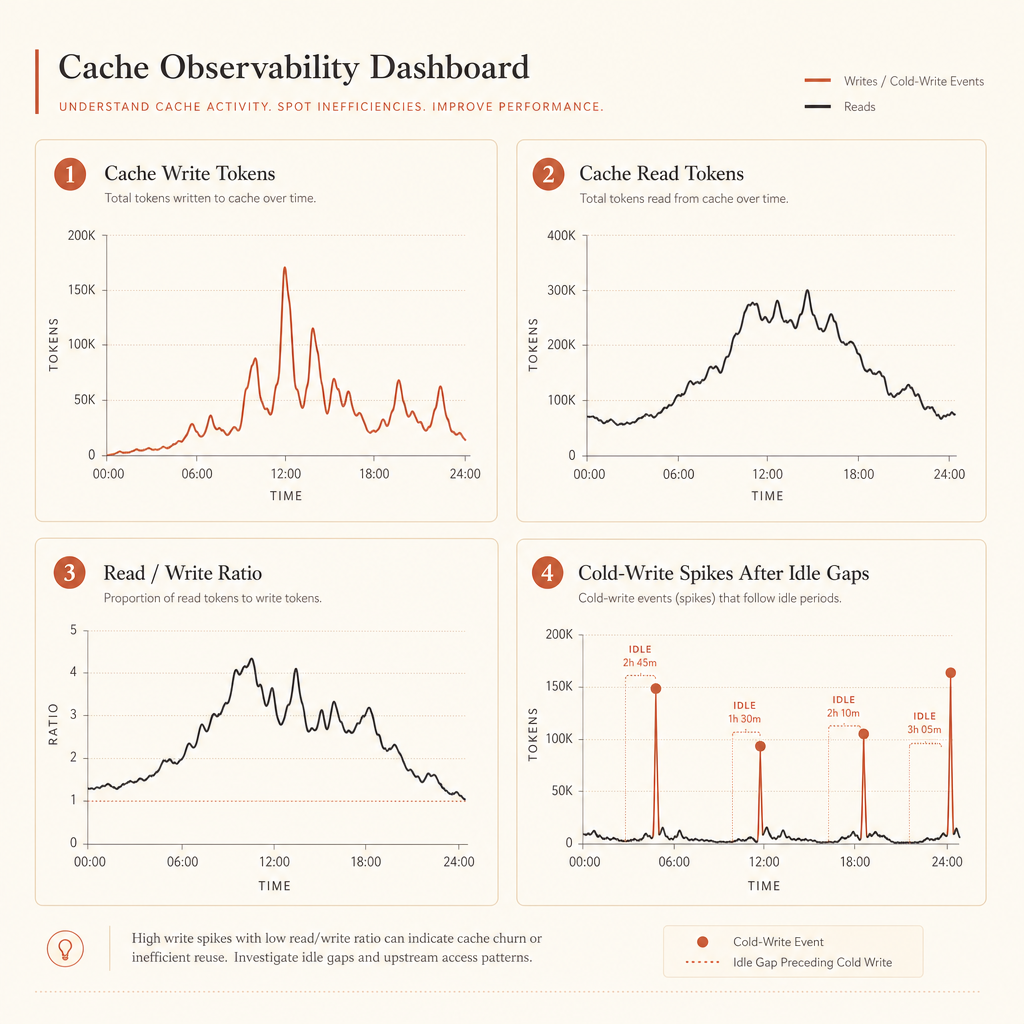
Qué monitorizar en el uso
El prompt caching es invisible hasta que inspeccionas los campos de uso. Anthropic dice que verifiques la caché revisando campos como cache_creation_input_tokens y cache_read_input_tokens; si ambos son cero, el prompt no se cacheó, a menudo porque no alcanzó la longitud mínima cacheable del modelo (documentación de prompt caching de Anthropic).
Registra esto por solicitud:
const usage = msg.usage;
console.log({
input: usage.input_tokens,
output: usage.output_tokens,
cacheCreate: usage.cache_creation_input_tokens,
cacheRead: usage.cache_read_input_tokens,
});Para objetos de uso más nuevos, la documentación de Anthropic también muestra la creación de caché dividida en buckets específicos de TTL como ephemeral_5m_input_tokens y ephemeral_1h_input_tokens. Captura el objeto de uso completo al principio. Normalízalo después, cuando sepas exactamente qué gateway y versión de SDK estás usando.
Los buenos dashboards responden cuatro preguntas:
- ¿Cuántos tokens se están escribiendo en caché?
- ¿Cuántos se están leyendo desde caché?
- ¿Cuál es la relación lectura/escritura de caché por ruta?
- ¿Qué prompts provocan grandes escrituras frías tras pausas?
Si cache_creation_input_tokens es alto y cache_read_input_tokens se mantiene cerca de cero, probablemente tu punto de corte está después de contenido cambiante. Muévelo antes.
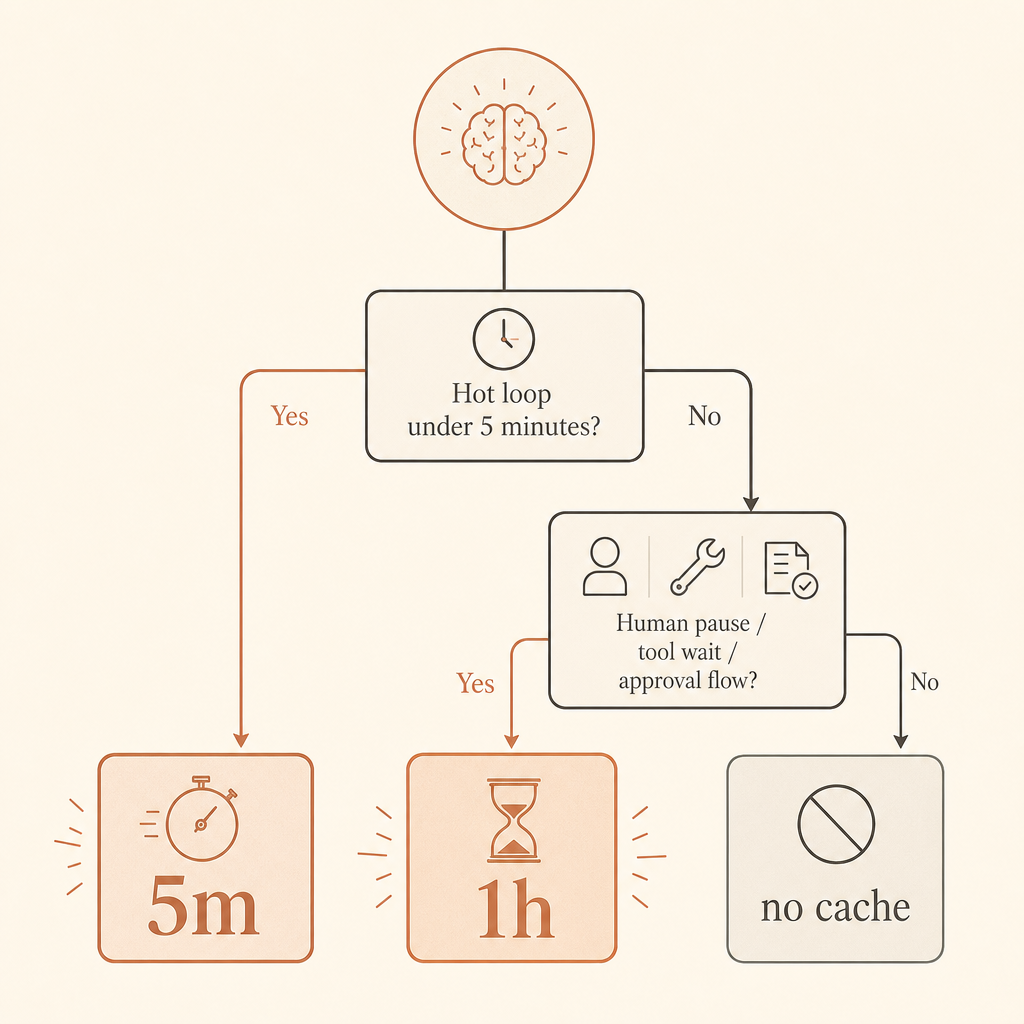
5 minutos o 1 hora: elige según el comportamiento del usuario
Usa caché de 5 minutos para bucles de solicitudes apretados. Un agente de programación que llama a herramientas cada 20 segundos, una app de chat donde los usuarios envían seguimientos rápido o un lote de trabajos de clasificación similares deberían empezar ahí. La prima de escritura es solo 1.25× y cada lectura refresca gratis la vida de la caché, según la documentación de Anthropic (documentación de prompt caching de Anthropic).
Usa caché de 1 hora cuando sea probable reutilizar el prefijo caro después de más de cinco minutos. Los flujos con humano en el bucle son el caso clásico. También lo son los agentes de larga duración donde el modelo envía trabajo a sistemas externos, espera a un navegador, sondea CI o se pausa para aprobación.
No cachees prompts diminutos. Anthropic documenta longitudes mínimas cacheables por modelo y plataforma; para Fable 5, el mínimo de la Claude API aparece como 512 tokens, mientras que Bedrock tiene mínimos distintos para algunos modelos (documentación de prompt caching de Anthropic). Los prompts más cortos pueden simplemente procesarse sin caché.
Una checklist práctica:
- Pon primero el contenido estable: herramientas, prompts de sistema, ejemplos, documentos de referencia.
- Mantén los datos cambiantes después del prefijo cacheado: timestamps, ids de solicitud, texto del usuario.
- Empieza con caché automática para conversaciones.
- Cambia a puntos de corte explícitos cuando tu sufijo cambie en cada llamada.
- Usa TTL de 1 hora solo cuando las pausas justifiquen la escritura a 2×.
- Registra los campos de uso antes de cantar victoria.
Conéctalo por OneHop y luego mide
La integración más limpia es un cambio de endpoint de una línea más selección de modelo configurada por entorno:
export ONEHOP_API_KEY="..."
export ANTHROPIC_BASE_URL="https://api.onehop.ai/v1"
export CLAUDE_MODEL="anthropic/claude-fable-5"Después conserva tu código de Anthropic Messages y añade cache_control.
La página de Fable 5 de OneHop anuncia ahora mismo precios por debajo de la lista oficial, un crédito inicial de $10 sin tarjeta y una ruta de Anthropic Messages para el modelo (OneHop). Como el acceso a Fable 5 está temporalmente suspendido desde la actualización de Anthropic del 12 de junio, incorpora el fallback de modelo a tu despliegue en vez de dejarlo como ocurrencia tardía.
La recompensa es simple. Si tu app repite prefijos grandes, las lecturas cacheadas a 0.1× convierten la ingeniería de prompts en ingeniería de costes. Empieza con caché de 5 minutos. Mueve flujos seleccionados a caché de 1 hora cuando los logs muestren reescrituras frías tras pausas. Si quieres el camino corto para Claude Fable 5 cuando vuelva la disponibilidad, prueba Claude Fable 5 en OneHop y empieza con $10 gratis.

