
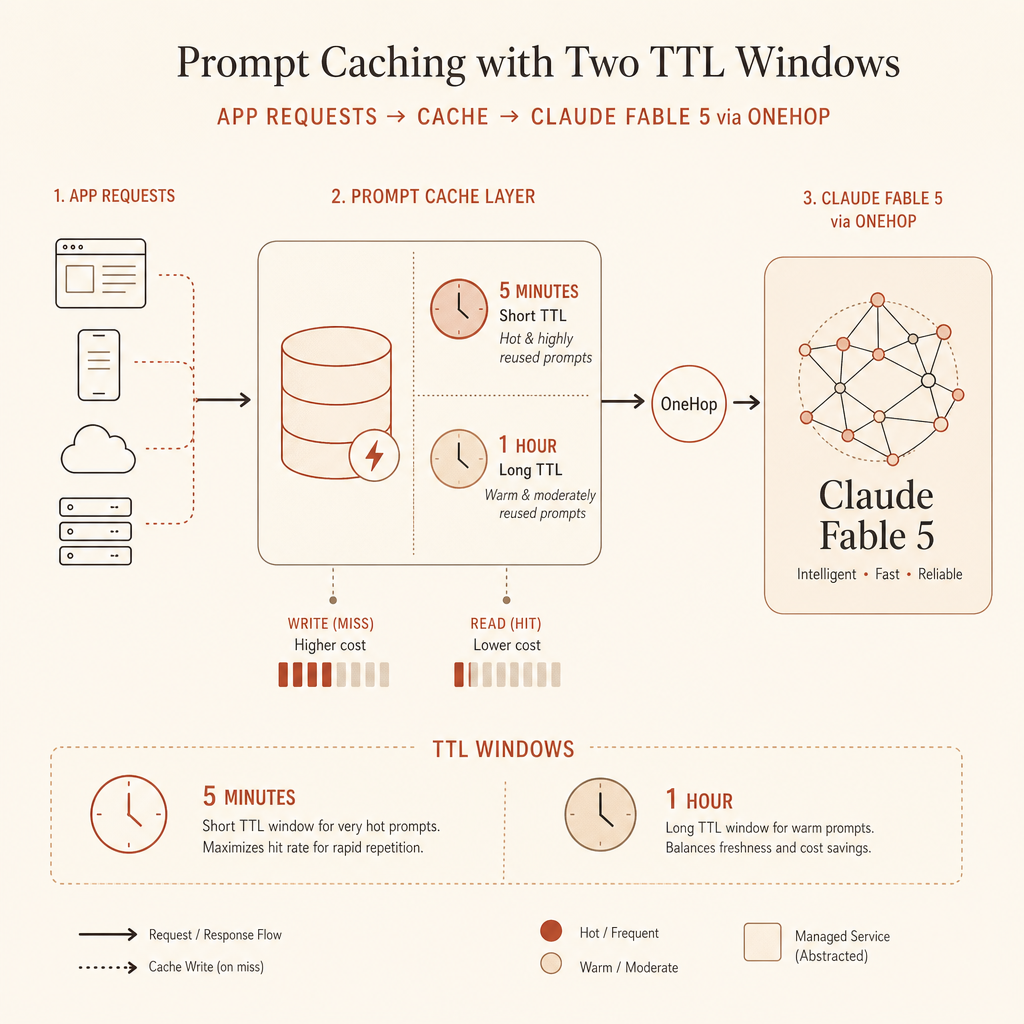
Claude Prompt-Caching hat eine wunderschöne Zahl und eine leichte Falle: Cache-Reads kosten 0,1× des normalen Inputs, Cache-Writes aber mehr als normaler Input. In den aktuellen Anthropic-Dokumenten stehen 5-Minuten-Cache-Writes bei 1,25× Input-Preis, 1-Stunden-Writes bei 2× und Cache-Hits bei 0,1× für aktive Claude-Modelle (Anthropic prompt caching docs).
Damit ist Caching ein Preis-Feature, nicht nur ein Latenz-Feature. Wenn deine App einen langen System-Prompt, ein Tool-Schema, ein Beispielpaket, ein Policy-Bundle, abgerufene Docs oder Multi-Turn-State wiederholt, solltest du Cache-Writes und -Reads genauso messen wie Output-Tokens.
Ein Haken Stand heute, 14. Juni 2026: Anthropic hat Claude Fable 5 am 9. Juni veröffentlicht und dann am 12. Juni ein Update gepostet, dass der Zugriff auf Fable 5 und Mythos 5 ausgesetzt wurde, während sie daran arbeiten, ihn wiederherzustellen (Anthropic). OneHop listet ebenfalls anthropic/claude-fable-5, mit Prompt-Cache-Support, markiert es auf der Modellseite aktuell aber als vorübergehend nicht verfügbar (OneHop). Bau die Integration jetzt, halte die Modell-ID konfigurierbar und schalte sie ein, sobald der Zugriff live ist.
Die Cache-Mathematik, die Entwickler wirklich brauchen
Anthropic speichert beim Prompt-Caching Prompt-Präfixe. Der wiederverwendbare Teil muss identisch sein: Tools, System-Inhalt und Messages werden in dieser Reihenfolge betrachtet, und der Cache gilt bis zu dem Block, der mit cache_control markiert ist (Anthropic prompt caching docs).
Das nützliche Preismodell ist simpel. Angenommen, dein wiederverwendbarer Präfix hat 100.000 Input-Tokens.
| Cache-Modus | Write-Kostenmultiplikator | Read-Kostenmultiplikator | Break-even-Gefühl |
|---|---|---|---|
| Kein Cache | 1,0× pro Request | keiner | Du zahlst jedes Mal den vollen Input |
| 5-Minuten-Cache | 1,25× einmalig | 0,1× pro Hit | Zahlt sich nach der ersten Wiederverwendung aus |
| 1-Stunden-Cache | 2,0× einmalig | 0,1× pro Hit | Braucht mehr Wiederverwendung oder längere Leerlaufpausen |
Für Claude Fable 5 nennt Anthropic im Launch-Post $10 pro Million Input-Tokens und $50 pro Million Output-Tokens; die Prompt-Caching-Dokumente listen für Fable 5 Cache-Preise von $12,50/M für 5-Minuten-Writes, $20/M für 1-Stunden-Writes und $1/M für Cache-Hits (Anthropic, prompt caching docs).
Mit Anthropic-Listenpreisen kostet dieser 100k-Token-Präfix:
- Normaler Input:
$1.00 - 5-Minuten-Write:
$1.25 - 1-Stunden-Write:
$2.00 - Cache-Read:
$0.10
Wenn derselbe 100k-Token-Präfix also zweimal innerhalb der TTL genutzt wird, kostet 5-Minuten-Caching $1.25 + $0.10 = $1.35, gegenüber $2.00 ohne Caching. Der 1-Stunden-Cache kostet bei zwei Nutzungen $2.10, verliert also bei zwei Calls, gewinnt aber ab einem dritten Call oder wenn du nach einer längeren Pause einen kalten Rewrite vermeidest.
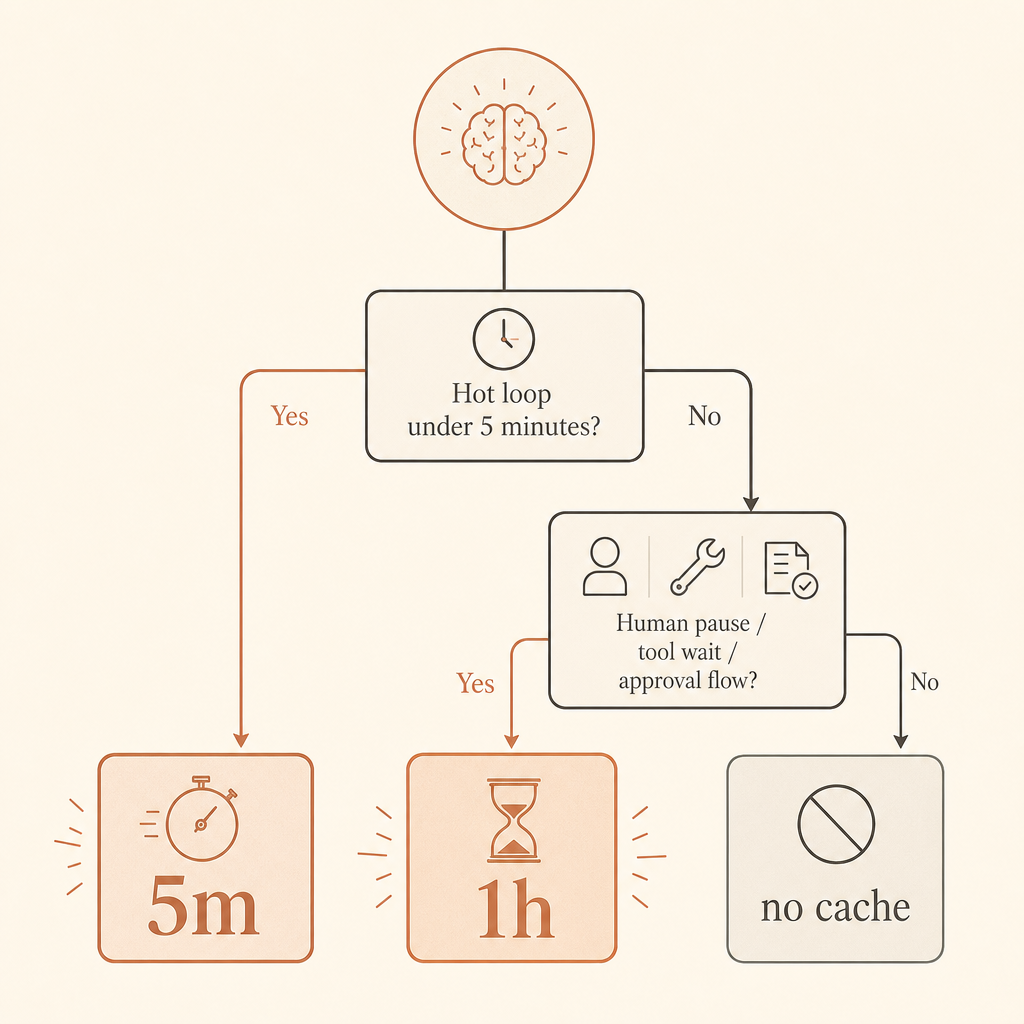
Das ist die Regel, die ich in Produktion nutze: standardmäßig 5 Minuten für Hot Loops; 1 Stunde, wenn Menschen pausieren, Agenten auf Tools warten oder Workflows nach mehreren Minuten wieder aufgenommen werden.
Zwei Wege, Caching einzuschalten
Anthropic dokumentiert inzwischen zwei Ansätze. Der schnellste Weg ist automatisches Caching: Füge ein Top-Level-Feld cache_control hinzu, und Claude verschiebt den Breakpoint nach vorne, während die Konversation wächst. Der kontrolliertere Weg sind explizite Breakpoints: Setze cache_control auf den letzten Content-Block im stabilen Präfix (Anthropic prompt caching docs).
Automatisches Caching ist großartig für Chat-History und Agent-State:
import os
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://api.onehop.ai/v1"),
)
message = client.messages.create(
model=os.getenv("CLAUDE_MODEL", "anthropic/claude-fable-5"),
max_tokens=700,
cache_control={"type": "ephemeral"},
system="You are a senior backend engineer. Be concise and specific.",
messages=[
{"role": "user", "content": "My app uses FastAPI, Postgres, and Redis."},
{"role": "assistant", "content": "Got it. What do you want to change?"},
{"role": "user", "content": "Design a cache key strategy for user dashboards."},
],
)
print(message.content[0].text)
print(message.usage.model_dump())Das ist der OneHop-Umstellungspfad: Behalte deinen Anthropic-artigen Request, mache die base URL konfigurierbar und zeige auf https://api.onehop.ai/v1. Die Modellseite von OneHop zeigt außerdem anthropic/claude-fable-5 als Modell-ID und sagt, dass neue Nutzer $10 Startguthaben ohne Kreditkarte bekommen (OneHop). Wenn du den kurzen Weg willst, öffne Claude Fable 5 auf OneHop und starte mit $10 gratis.
Explizites Caching ist besser, wenn der Präfix stabil ist, sich die User-Message aber bei jedem Request ändert. Setze den Breakpoint vor den veränderlichen Teil:
from anthropic import Anthropic
import os
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/v1",
)
response = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=500,
system=[
{
"type": "text",
"text": open("system_prompt.md").read(),
"cache_control": {"type": "ephemeral"},
}
],
messages=[
{"role": "user", "content": "Review this migration plan for race conditions."}
],
)
print(response.usage.model_dump())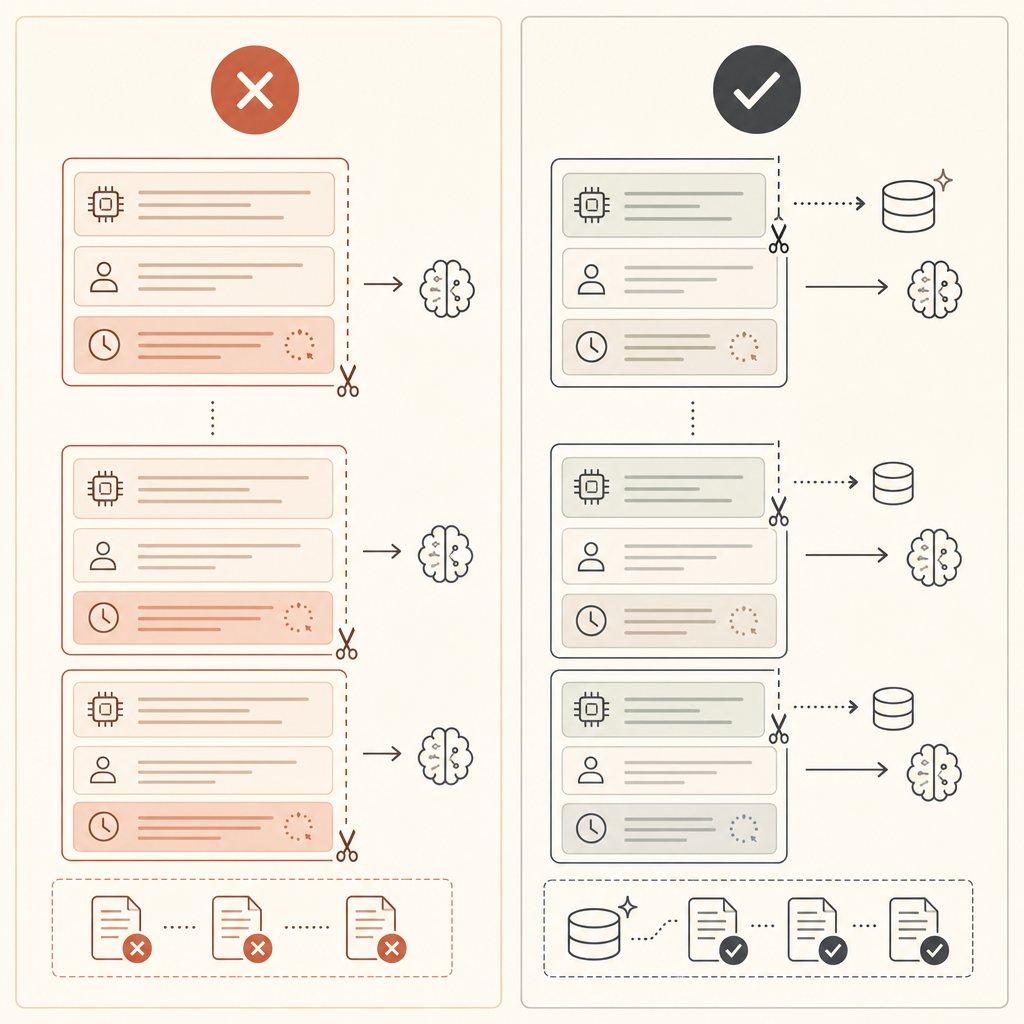
TypeScript-Version mit 1-Stunden-TTL
Nutze 1-Stunden-Caching, wenn die App teuren statischen Kontext und realistische Leerlaufpausen hat. Denk an Code-Review-Agenten, die auf CI warten, Customer-Support-Copilots, bei denen Menschen pausieren, juristische Recherche-Sessions oder mehrstufige Datenanalysen, bei denen Tools mehrere Minuten brauchen.
Anthropic zeigt in den Docs die 1-Stunden-TTL als {"type":"ephemeral","ttl":"1h"} und schreibt, dass automatisches Caching standardmäßig 5 Minuten nutzt (Anthropic prompt caching docs).
import Anthropic from "@anthropic-ai/sdk";
import fs from "node:fs";
const client = new Anthropic({
apiKey: process.env.ONEHOP_API_KEY!,
baseURL: process.env.ANTHROPIC_BASE_URL ?? "https://api.onehop.ai/v1",
});
const policyPack = fs.readFileSync("policy-pack.md", "utf8");
const msg = await client.messages.create({
model: process.env.CLAUDE_MODEL ?? "anthropic/claude-fable-5",
max_tokens: 800,
system: [
{
type: "text",
text: policyPack,
cache_control: { type: "ephemeral", ttl: "1h" },
},
],
messages: [
{
role: "user",
content: "Apply the policy pack to this refund request: customer used 3 of 10 seats.",
},
],
});
console.log(msg.content);
console.log(msg.usage);Der wichtige Teil ist langweilig: Verstecke Modell und base URL nicht tief im Code. Halte beides in Umgebungsvariablen. Die Verfügbarkeit von Fable 5 bewegt sich gerade; deine Integration sollte auf ein anderes aktives Claude-Modell zurückfallen können, ohne Business-Logik anzufassen.
Was du in Usage überwachen solltest
Prompt-Caching bleibt unsichtbar, bis du die Usage-Felder prüfst. Anthropic sagt, du sollst Caching verifizieren, indem du Felder wie cache_creation_input_tokens und cache_read_input_tokens prüfst; wenn beide null sind, wurde der Prompt nicht gecacht, oft weil die Mindestlänge des Modells für cachingfähige Prompts nicht erreicht wurde (Anthropic prompt caching docs).
Logge das pro Request:
const usage = msg.usage;
console.log({
input: usage.input_tokens,
output: usage.output_tokens,
cacheCreate: usage.cache_creation_input_tokens,
cacheRead: usage.cache_read_input_tokens,
});Für neuere Usage-Objekte zeigen Anthropic-Dokumente Cache-Creation außerdem aufgeteilt in TTL-spezifische Buckets wie ephemeral_5m_input_tokens und ephemeral_1h_input_tokens. Erfasse am Anfang das vollständige Usage-Objekt. Normalisiere es später, sobald du genau weißt, welches Gateway und welche SDK-Version du nutzt.
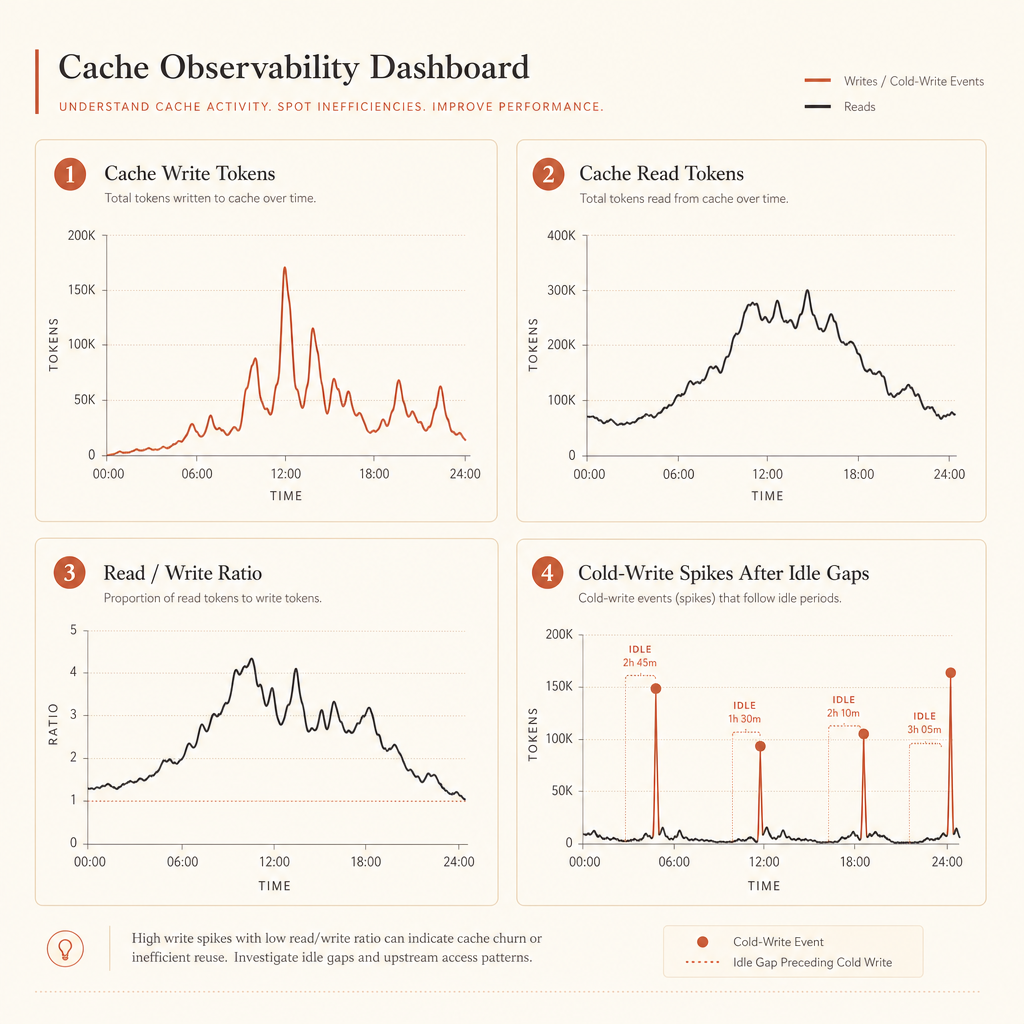
Gute Dashboards beantworten vier Fragen:
- Wie viele Tokens werden in den Cache geschrieben?
- Wie viele werden aus dem Cache gelesen?
- Wie ist das Cache-Read/Write-Verhältnis je Route?
- Welche Prompts erzeugen große Cold Writes nach Leerlaufpausen?
Wenn cache_creation_input_tokens hoch ist und cache_read_input_tokens nahe null bleibt, liegt dein Breakpoint wahrscheinlich hinter veränderlichem Content. Verschiebe ihn nach vorne.
5 Minuten oder 1 Stunde: Entscheide nach Nutzerverhalten
Nutze 5-Minuten-Caching für enge Request-Loops. Ein Coding-Agent, der alle 20 Sekunden Tools aufruft, eine Chat-App, in der Nutzer schnell Follow-ups schicken, oder ein Batch ähnlicher Klassifizierungsjobs sollte dort anfangen. Der Write-Aufpreis beträgt nur 1,25×, und jeder Read verlängert laut Anthropic-Dokumenten die Cache-Lebensdauer kostenlos (Anthropic prompt caching docs).
Nutze 1-Stunden-Caching, wenn der teure Präfix wahrscheinlich nach mehr als fünf Minuten wiederverwendet wird. Human-in-the-loop-Workflows sind der klassische Fall. Ebenso lang laufende Agenten, bei denen das Modell Arbeit an externe Systeme schickt, auf einen Browser wartet, CI pollt oder für eine Freigabe pausiert.
Cache keine winzigen Prompts. Anthropic dokumentiert Mindestlängen für cachingfähige Prompts nach Modell und Plattform; für Fable 5 ist das Claude API-Minimum mit 512 Tokens angegeben, während Bedrock für einige Modelle andere Mindestwerte hat (Anthropic prompt caching docs). Kürzere Prompts können schlicht ohne Caching verarbeitet werden.
Eine praktische Checkliste:
- Stabile Inhalte zuerst: Tools, System-Prompts, Beispiele, Referenzdokumente.
- Veränderliche Daten nach dem gecachten Präfix: Timestamps, Request-IDs, User-Text.
- Starte mit automatischem Caching für Konversationen.
- Wechsle zu expliziten Breakpoints, wenn sich dein Suffix bei jedem Call ändert.
- Nutze 1-Stunden-TTL nur, wenn Leerlaufpausen den 2×-Write rechtfertigen.
- Logge Usage-Felder, bevor du den Sieg ausrufst.
Über OneHop anbinden, dann messen
Die sauberste Integration ist eine einzeilige Endpoint-Änderung plus Modellwahl per Env-Konfiguration:
export ONEHOP_API_KEY="..."
export ANTHROPIC_BASE_URL="https://api.onehop.ai/v1"
export CLAUDE_MODEL="anthropic/claude-fable-5"Dann behältst du deinen Anthropic Messages-Code und fügst cache_control hinzu.
Die Fable-5-Seite von OneHop bewirbt aktuell Preise unter der offiziellen Liste, ein $10-Startguthaben ohne Kreditkarte und eine Anthropic Messages-Route für das Modell (OneHop). Weil der Zugriff auf Fable 5 laut Anthropic-Update vom 12. Juni vorübergehend ausgesetzt ist, sollte Modell-Fallback Teil deines Rollouts sein, nicht ein nachträglicher Gedanke.
Der Gewinn ist simpel. Wenn deine App große Präfixe wiederholt, machen gecachte Reads zu 0,1× aus Prompt Engineering Kosten-Engineering. Starte mit 5-Minuten-Caching. Verschiebe ausgewählte Workflows auf 1-Stunden-Caching, wenn die Logs nach Pausen Cold Rewrites zeigen. Wenn du den kurzen Weg für Claude Fable 5 willst, sobald die Verfügbarkeit zurück ist, probiere Claude Fable 5 auf OneHop und starte mit $10 gratis.

