
У Claude prompt caching есть одна прекрасная цифра и одна ловушка, в которую легко влететь: чтение из кэша стоит 0,1× от обычного ввода, но запись в кэш дороже обычного ввода. В текущей документации Anthropic указано: запись в 5-минутный кэш стоит 1,25× цены input, запись в 1-часовой — 2×, а попадания в кэш — 0,1× для активных моделей Claude (Anthropic prompt caching docs).
Это делает кэширование не просто фичей для задержки, а полноценной фичей для ценообразования. Если ваше приложение повторяет длинный system prompt, схему tools, набор примеров, пакет политик, найденные документы или состояние многошагового диалога, вам нужно измерять записи и чтения кэша так же внимательно, как output tokens.
Один нюанс на сегодня, 14 июня 2026 года: Anthropic запустила Claude Fable 5 9 июня, а затем 12 июня опубликовала обновление, что доступ к Fable 5 и Mythos 5 приостановлен, пока они работают над восстановлением (Anthropic). OneHop тоже показывает anthropic/claude-fable-5 с поддержкой prompt cache, но сейчас помечает модель как временно недоступную на своей странице модели (OneHop). Соберите интеграцию сейчас, оставьте model id настраиваемым и включите его, когда доступ снова заработает.
Математика кэша, которая реально нужна разработчикам
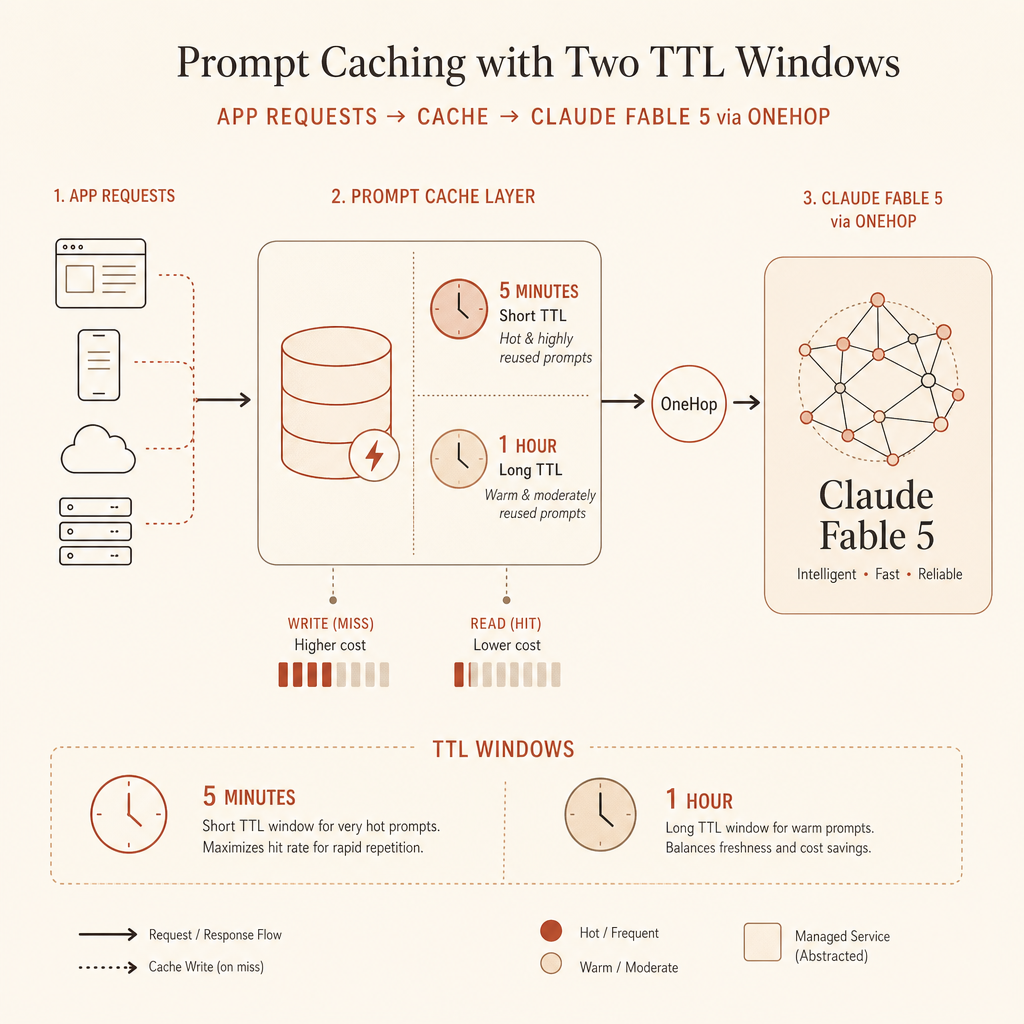
Anthropic prompt cache хранит префиксы prompt. Переиспользуемая часть должна быть идентичной: tools, system content и messages учитываются именно в таком порядке, а кэш применяется до блока, помеченного cache_control (Anthropic prompt caching docs).
Полезная модель цены простая. Допустим, ваш переиспользуемый префикс — 100 000 input tokens.
| Режим кэша | Множитель стоимости записи | Множитель стоимости чтения | Интуиция точки окупаемости |
|---|---|---|---|
| Без кэша | 1,0× на каждый запрос | нет | Платите полную цену input каждый раз |
| 5-минутный кэш | 1,25× один раз | 0,1× за попадание | Окупается уже после первого повторного использования |
| 1-часовой кэш | 2,0× один раз | 0,1× за попадание | Нужны более частые повторы или более длинные паузы |
Для Claude Fable 5 Anthropic указывает $10 за миллион input tokens и $50 за миллион output tokens в посте о запуске, а в документации по prompt caching цены кэша для Fable 5 указаны как $12.50/M за 5-минутную запись, $20/M за 1-часовую запись и $1/M за попадания в кэш (Anthropic, prompt caching docs).
По прайс-листу Anthropic такой префикс на 100k токенов стоит:
- Обычный input:
$1.00 - 5-минутная запись:
$1.25 - 1-часовая запись:
$2.00 - Чтение из кэша:
$0.10
Так что если один и тот же префикс на 100k токенов используется дважды в пределах TTL, 5-минутное кэширование стоит $1.25 + $0.10 = $1.35 против $2.00 без кэша. 1-часовой кэш стоит $2.10 за два использования, то есть проигрывает на двух вызовах, но выигрывает, если появляется третий вызов или если вы избегаете холодной перезаписи после более длинной паузы.
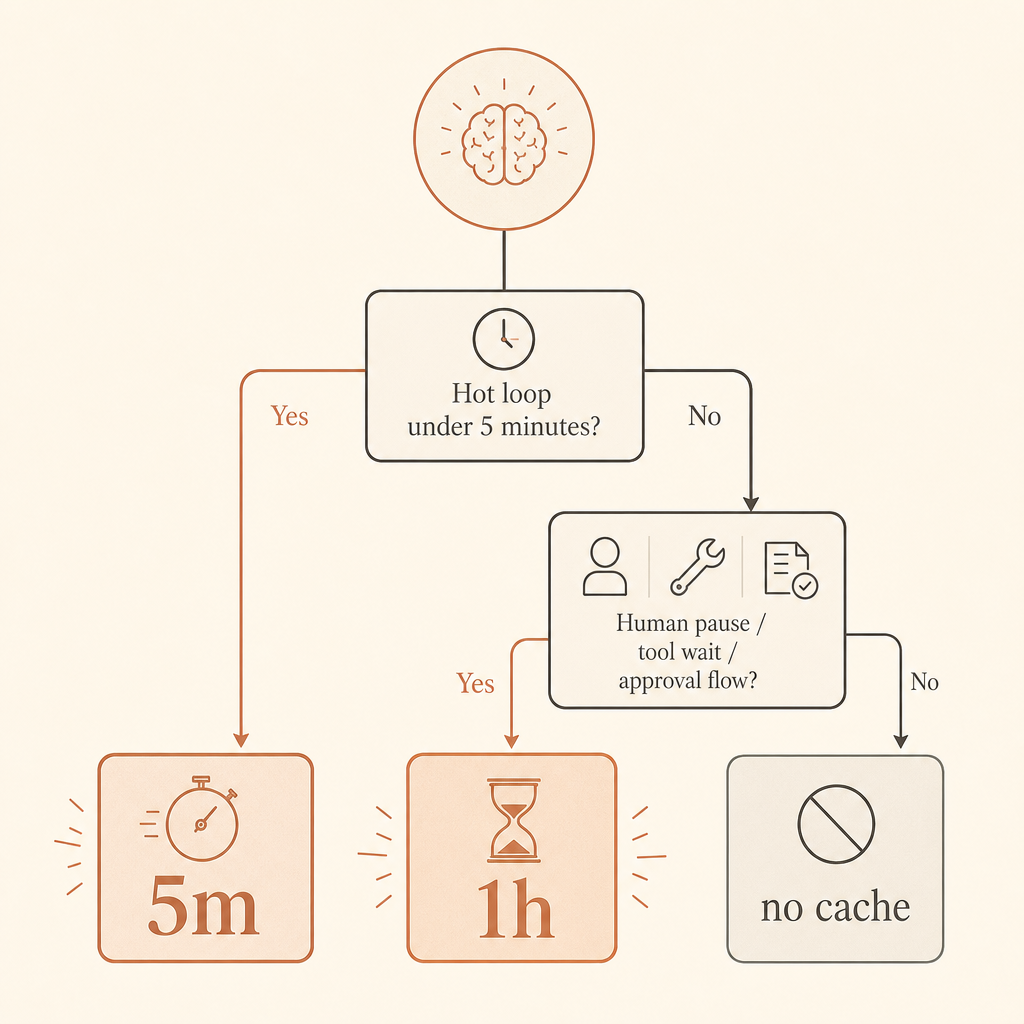
Вот правило, которым я пользуюсь в продакшене: по умолчанию 5 минут для горячих циклов; 1 час — когда люди делают паузы, агенты ждут tools или workflow возобновляется через несколько минут.
Два способа включить кэширование
Anthropic сейчас документирует два подхода. Самый быстрый путь — автоматическое кэширование: добавьте верхнеуровневое поле cache_control, и Claude будет двигать breakpoint вперед по мере роста разговора. Более управляемый путь — явные breakpoints: поставьте cache_control на последний content block в стабильном префиксе (Anthropic prompt caching docs).
Автоматическое кэширование отлично подходит для истории чата и состояния агента:
import os
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://api.onehop.ai/v1"),
)
message = client.messages.create(
model=os.getenv("CLAUDE_MODEL", "anthropic/claude-fable-5"),
max_tokens=700,
cache_control={"type": "ephemeral"},
system="You are a senior backend engineer. Be concise and specific.",
messages=[
{"role": "user", "content": "My app uses FastAPI, Postgres, and Redis."},
{"role": "assistant", "content": "Got it. What do you want to change?"},
{"role": "user", "content": "Design a cache key strategy for user dashboards."},
],
)
print(message.content[0].text)
print(message.usage.model_dump())Это путь конвертации для OneHop: оставьте запрос в стиле Anthropic, сделайте base URL настраиваемым и направьте его на https://api.onehop.ai/v1. Страница модели OneHop также показывает anthropic/claude-fable-5 как model id и говорит, что новые пользователи получают $10 бесплатного кредита без карты (OneHop). Если хотите короткий путь, откройте Claude Fable 5 на OneHop и начните с $10 бесплатно.
Явное кэширование лучше, когда префикс стабилен, а user message меняется в каждом запросе. Поставьте breakpoint перед изменяющейся частью:
from anthropic import Anthropic
import os
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/v1",
)
response = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=500,
system=[
{
"type": "text",
"text": open("system_prompt.md").read(),
"cache_control": {"type": "ephemeral"},
}
],
messages=[
{"role": "user", "content": "Review this migration plan for race conditions."}
],
)
print(response.usage.model_dump())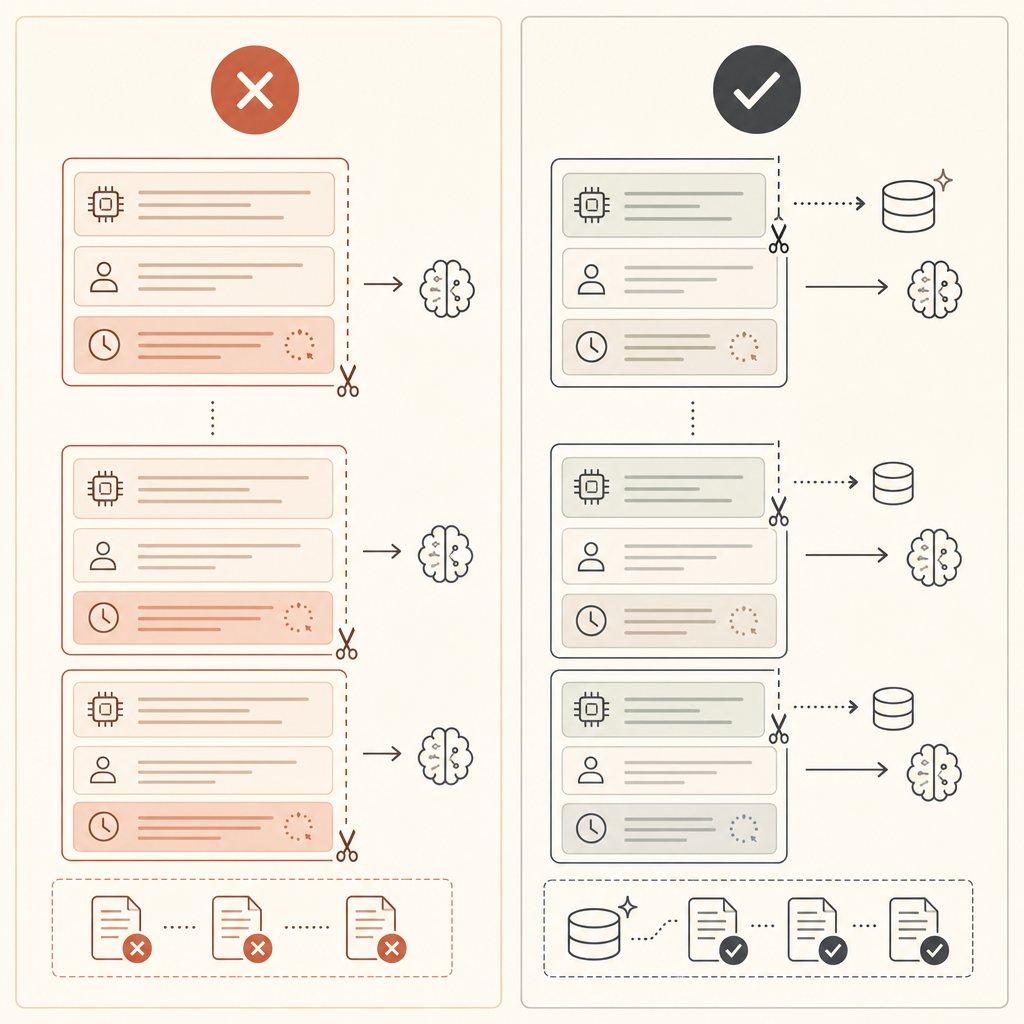
TypeScript-версия с 1-часовым TTL
Используйте 1-часовое кэширование, когда у приложения есть дорогой статический контекст и реальные паузы в работе. Например: агенты для code review, которые ждут CI; copilots для поддержки клиентов, где люди останавливаются; юридические исследования; или многошаговый анализ данных, где tools занимают несколько минут.
В документации Anthropic 1-часовой TTL показан как {"type":"ephemeral","ttl":"1h"}, а также сказано, что автоматическое кэширование по умолчанию использует 5 минут (Anthropic prompt caching docs).
import Anthropic from "@anthropic-ai/sdk";
import fs from "node:fs";
const client = new Anthropic({
apiKey: process.env.ONEHOP_API_KEY!,
baseURL: process.env.ANTHROPIC_BASE_URL ?? "https://api.onehop.ai/v1",
});
const policyPack = fs.readFileSync("policy-pack.md", "utf8");
const msg = await client.messages.create({
model: process.env.CLAUDE_MODEL ?? "anthropic/claude-fable-5",
max_tokens: 800,
system: [
{
type: "text",
text: policyPack,
cache_control: { type: "ephemeral", ttl: "1h" },
},
],
messages: [
{
role: "user",
content: "Apply the policy pack to this refund request: customer used 3 of 10 seats.",
},
],
});
console.log(msg.content);
console.log(msg.usage);Главное здесь скучное: не прячьте model и base URL глубоко в коде. Держите оба значения в переменных окружения. Доступность Fable 5 сейчас меняется; ваша интеграция должна уметь откатываться на другую активную модель Claude без правок бизнес-логики.
Что смотреть в usage
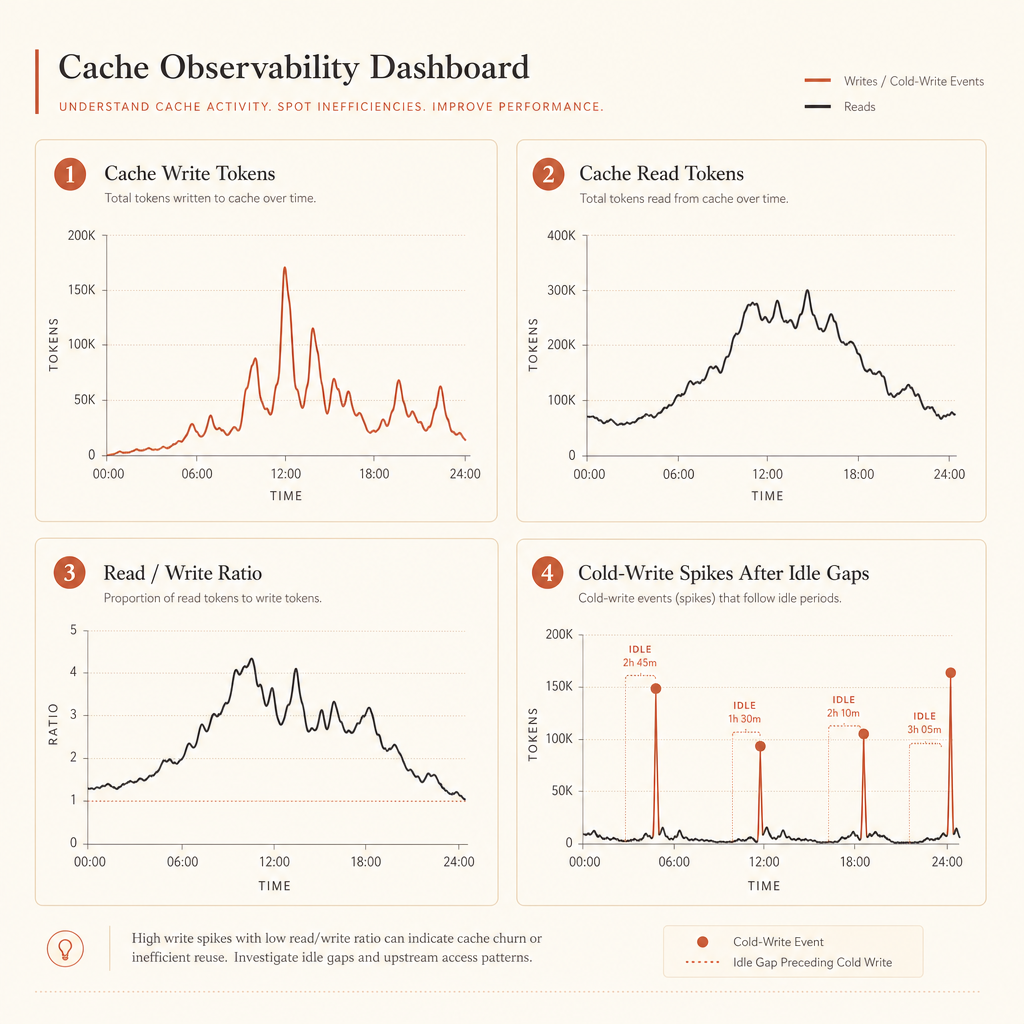
Prompt caching невидим, пока вы не начнете проверять поля usage. Anthropic говорит проверять кэширование по полям вроде cache_creation_input_tokens и cache_read_input_tokens; если оба равны нулю, prompt не был закэширован — часто потому, что не дотянул до минимальной длины, которую модель умеет кэшировать (Anthropic prompt caching docs).
Логируйте это на каждый запрос:
const usage = msg.usage;
console.log({
input: usage.input_tokens,
output: usage.output_tokens,
cacheCreate: usage.cache_creation_input_tokens,
cacheRead: usage.cache_read_input_tokens,
});Для новых объектов usage документация Anthropic также показывает разбиение создания кэша по TTL-бакетам вроде ephemeral_5m_input_tokens и ephemeral_1h_input_tokens. Сначала сохраняйте весь объект usage целиком. Нормализуете позже, когда точно поймете, какой gateway и какую версию SDK используете.
Хорошие дашборды отвечают на четыре вопроса:
- Сколько токенов записывается в кэш?
- Сколько читается из кэша?
- Какое соотношение чтения и записи кэша по route?
- Какие prompts создают большие холодные записи после пауз?
Если cache_creation_input_tokens высокий, а cache_read_input_tokens держится около нуля, ваш breakpoint, скорее всего, стоит после меняющегося контента. Передвиньте его раньше.
5 минут или 1 час: выбирайте по поведению пользователей
Используйте 5-минутное кэширование для плотных циклов запросов. Coding agent, который вызывает tools каждые 20 секунд, чат-приложение, где пользователи быстро отправляют уточнения, или пачка похожих classification jobs — все это должно начинаться там. Надбавка за запись всего 1,25×, и каждое чтение бесплатно продлевает срок жизни кэша, согласно документации Anthropic (Anthropic prompt caching docs).
Используйте 1-часовое кэширование, когда дорогой префикс, скорее всего, будет переиспользован позже чем через пять минут. Human-in-the-loop workflows — классический случай. То же самое с долгоживущими агентами, где модель отправляет работу во внешние системы, ждет браузер, опрашивает CI или делает паузу для approval.
Не кэшируйте крошечные prompts. Anthropic документирует минимальные кэшируемые длины prompt по модели и платформе; для Fable 5 минимум Claude API указан как 512 токенов, а у Bedrock для некоторых моделей другие минимумы (Anthropic prompt caching docs). Более короткие prompts могут просто обработаться без кэширования.
Практичный чеклист:
- Ставьте стабильный контент первым: tools, system prompts, примеры, справочные документы.
- Держите меняющиеся данные после закэшированного префикса: timestamps, request ids, user text.
- Начинайте с автоматического кэширования для разговоров.
- Переходите на явные breakpoints, когда suffix меняется при каждом вызове.
- Используйте 1-часовой TTL только когда паузы оправдывают запись за 2×.
- Логируйте поля usage, прежде чем объявлять победу.
Подключите через OneHop, потом измеряйте
Самая чистая интеграция — сменить endpoint одной строкой и выбирать модель через env:
export ONEHOP_API_KEY="..."
export ANTHROPIC_BASE_URL="https://api.onehop.ai/v1"
export CLAUDE_MODEL="anthropic/claude-fable-5"Затем оставьте свой код Anthropic Messages и добавьте cache_control.
Страница Fable 5 на OneHop сейчас рекламирует цены ниже официального прайс-листа, стартовый кредит $10 без карты и route Anthropic Messages для модели (OneHop). Поскольку доступ к Fable 5 временно приостановлен согласно обновлению Anthropic от 12 июня, сделайте fallback модели частью rollout, а не мыслью на потом.
Выигрыш простой. Если ваше приложение повторяет большие префиксы, чтение из кэша за 0,1× превращает prompt engineering в cost engineering. Начните с 5-минутного кэширования. Переведите отдельные workflows на 1-часовое кэширование, когда логи покажут холодные перезаписи после пауз. Если хотите короткий путь к Claude Fable 5, когда доступность вернется, попробуйте Claude Fable 5 на OneHop и начните с $10 бесплатно.

