
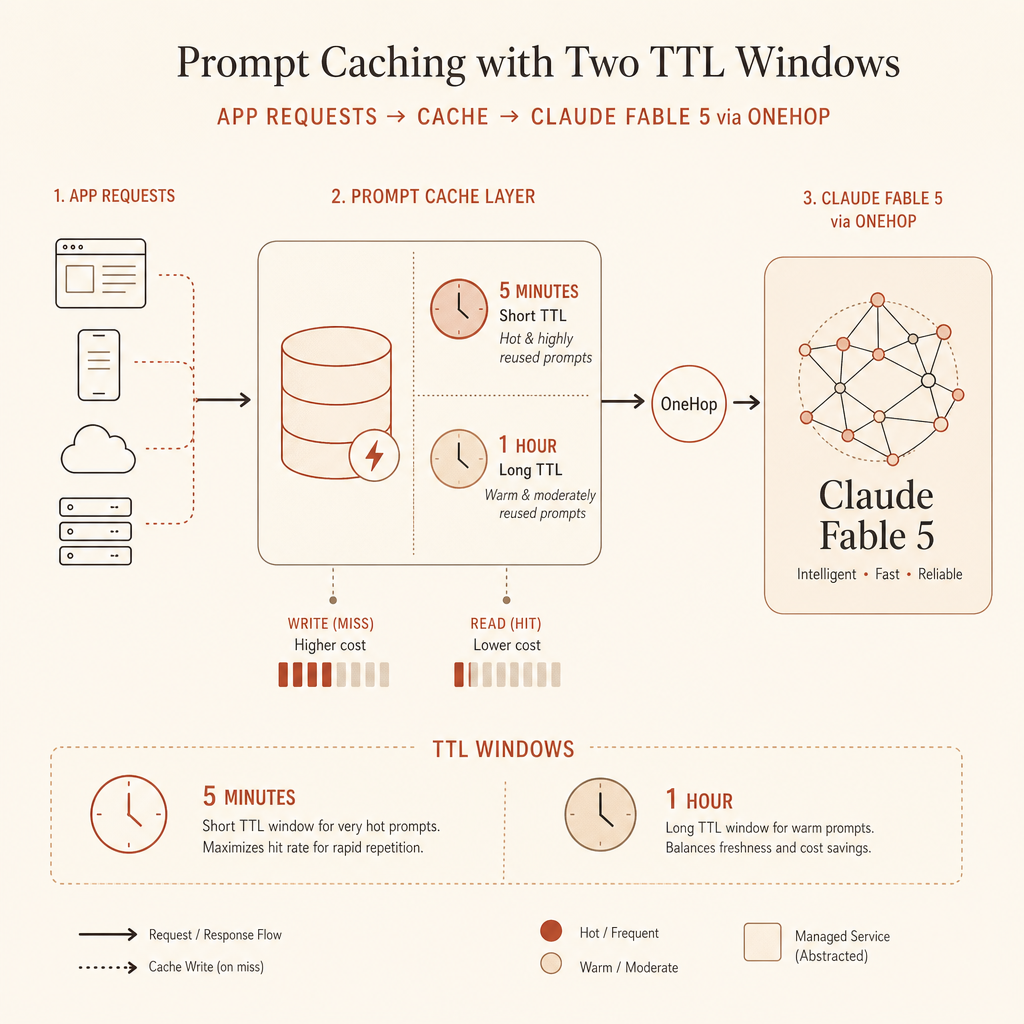
O cache de prompts do Claude tem um número lindo e uma armadilha fácil: leituras de cache custam 0,1× a entrada normal, mas gravações de cache custam mais que a entrada normal. A documentação atual da Anthropic lista gravações de cache de 5 minutos a 1,25× o preço de entrada, gravações de 1 hora a 2×, e acertos de cache a 0,1× em todos os modelos Claude ativos (documentação de cache de prompts da Anthropic).
Isso transforma cache em um recurso de preço, não só de latência. Se o seu app repete um prompt de sistema longo, schema de ferramentas, pacote de exemplos, conjunto de políticas, documentos recuperados ou estado multi-turno, você deveria medir gravações e leituras de cache do mesmo jeito que mede tokens de saída.
Um detalhe em 14 de junho de 2026: a Anthropic lançou o Claude Fable 5 em 9 de junho, depois publicou uma atualização em 12 de junho dizendo que o acesso ao Fable 5 e ao Mythos 5 foi suspenso enquanto trabalham para restaurá-lo (Anthropic). A OneHop também lista anthropic/claude-fable-5, com suporte a cache de prompts, mas atualmente marca o modelo como temporariamente indisponível na página do modelo (OneHop). Monte a integração agora, mantenha o id do modelo configurável e ligue tudo quando o acesso voltar.
A conta de cache que desenvolvedores realmente precisam
O cache de prompts da Anthropic armazena prefixos de prompt. A parte reutilizável precisa ser idêntica: ferramentas, conteúdo de sistema e mensagens são considerados nessa ordem, e o cache se aplica até o bloco marcado com cache_control (documentação de cache de prompts da Anthropic).
O modelo de preço útil é simples. Suponha que seu prefixo reutilizável tenha 100.000 tokens de entrada.
| Modo de cache | Multiplicador de custo de gravação | Multiplicador de custo de leitura | Intuição de break-even |
|---|---|---|---|
| Sem cache | 1,0× em toda requisição | nenhum | Paga a entrada cheia toda vez |
| Cache de 5 minutos | 1,25× uma vez | 0,1× por acerto | Compensa depois do primeiro reúso |
| Cache de 1 hora | 2,0× uma vez | 0,1× por acerto | Precisa de mais reúso ou pausas mais longas |
Para o Claude Fable 5, a Anthropic lista US$ 10 por milhão de tokens de entrada e US$ 50 por milhão de tokens de saída no post de lançamento, e a documentação de cache de prompts lista os preços de cache do Fable 5 como US$ 12,50/M para gravações de 5 minutos, US$ 20/M para gravações de 1 hora, e US$ 1/M para acertos de cache (Anthropic, documentação de cache de prompts).
Usando os preços de tabela da Anthropic, esse prefixo de 100 mil tokens custa:
- Entrada normal:
$1.00 - Gravação de 5 minutos:
$1.25 - Gravação de 1 hora:
$2.00 - Leitura de cache:
$0.10
Então, se o mesmo prefixo de 100 mil tokens for usado duas vezes dentro do TTL, o cache de 5 minutos custa $1.25 + $0.10 = $1.35, contra $2.00 sem cache. O cache de 1 hora custa $2.10 para dois usos, então perde em duas chamadas, mas ganha quando você tem uma terceira chamada ou evita uma nova gravação fria depois de uma pausa mais longa.
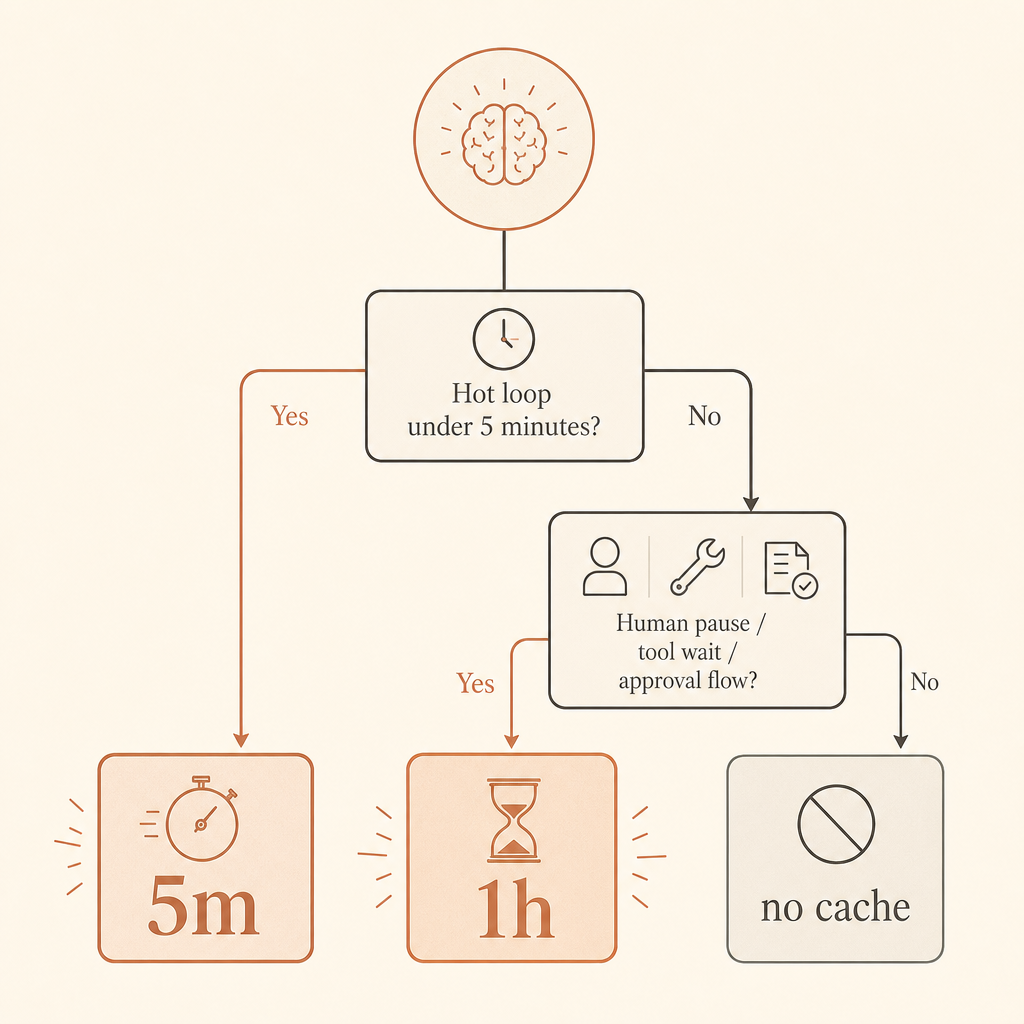
Essa é a regra que uso em produção: 5 minutos por padrão para loops quentes; 1 hora quando humanos fazem pausa, agentes esperam ferramentas, ou fluxos de trabalho são retomados depois de vários minutos.
Duas formas de ativar o cache
A Anthropic agora documenta duas abordagens. O caminho mais rápido é o cache automático: adicione um campo cache_control no nível superior e o Claude move o ponto de quebra para frente conforme a conversa cresce. O caminho com mais controle é usar pontos de quebra explícitos: coloque cache_control no último bloco de conteúdo do prefixo estável (documentação de cache de prompts da Anthropic).
Cache automático é ótimo para histórico de chat e estado de agente:
import os
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://api.onehop.ai/v1"),
)
message = client.messages.create(
model=os.getenv("CLAUDE_MODEL", "anthropic/claude-fable-5"),
max_tokens=700,
cache_control={"type": "ephemeral"},
system="You are a senior backend engineer. Be concise and specific.",
messages=[
{"role": "user", "content": "My app uses FastAPI, Postgres, and Redis."},
{"role": "assistant", "content": "Got it. What do you want to change?"},
{"role": "user", "content": "Design a cache key strategy for user dashboards."},
],
)
print(message.content[0].text)
print(message.usage.model_dump())Esse é o caminho de conversão da OneHop: mantenha sua requisição no estilo Anthropic, deixe o base URL configurável e aponte para https://api.onehop.ai/v1. A página do modelo da OneHop também mostra anthropic/claude-fable-5 como o id do modelo e diz que novos usuários ganham US$ 10 de crédito grátis sem precisar de cartão (OneHop). Se quiser o caminho curto, abra Claude Fable 5 na OneHop e comece com US$ 10 grátis.
Cache explícito é melhor quando o prefixo é estável, mas a mensagem do usuário muda a cada requisição. Coloque o ponto de quebra antes da parte que muda:
from anthropic import Anthropic
import os
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/v1",
)
response = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=500,
system=[
{
"type": "text",
"text": open("system_prompt.md").read(),
"cache_control": {"type": "ephemeral"},
}
],
messages=[
{"role": "user", "content": "Review this migration plan for race conditions."}
],
)
print(response.usage.model_dump())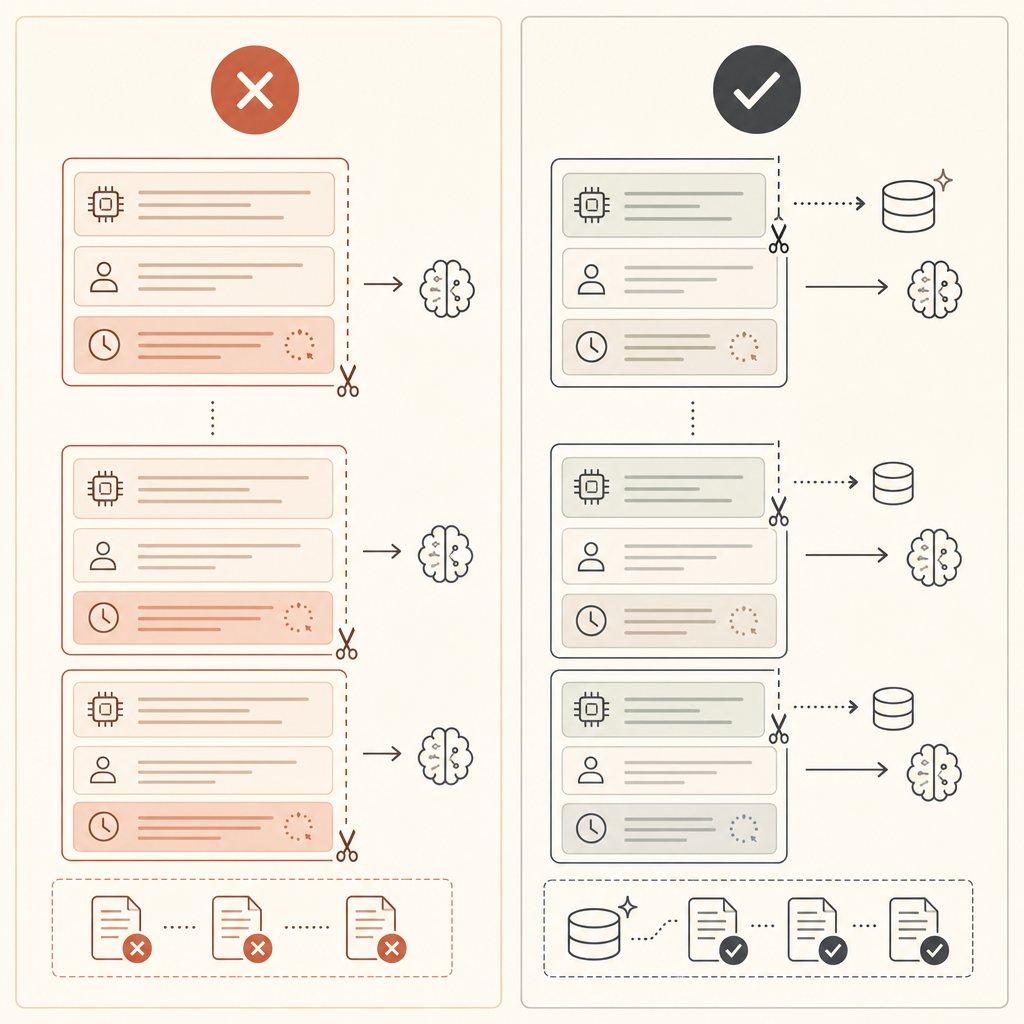
Versão TypeScript com TTL de 1 hora
Use cache de 1 hora quando o app tem contexto estático caro e pausas realistas. Pense em agentes de revisão de código esperando CI, copilotos de suporte ao cliente em que humanos fazem pausas, sessões de pesquisa jurídica, ou análise de dados em várias etapas em que ferramentas levam vários minutos.
A documentação da Anthropic mostra o TTL de 1 hora como {"type":"ephemeral","ttl":"1h"} e afirma que o cache automático usa 5 minutos por padrão (documentação de cache de prompts da Anthropic).
import Anthropic from "@anthropic-ai/sdk";
import fs from "node:fs";
const client = new Anthropic({
apiKey: process.env.ONEHOP_API_KEY!,
baseURL: process.env.ANTHROPIC_BASE_URL ?? "https://api.onehop.ai/v1",
});
const policyPack = fs.readFileSync("policy-pack.md", "utf8");
const msg = await client.messages.create({
model: process.env.CLAUDE_MODEL ?? "anthropic/claude-fable-5",
max_tokens: 800,
system: [
{
type: "text",
text: policyPack,
cache_control: { type: "ephemeral", ttl: "1h" },
},
],
messages: [
{
role: "user",
content: "Apply the policy pack to this refund request: customer used 3 of 10 seats.",
},
],
});
console.log(msg.content);
console.log(msg.usage);A parte importante é sem graça: não esconda o modelo e o base URL lá no fundo do código. Mantenha os dois em variáveis de ambiente. A disponibilidade do Fable 5 está mudando hoje; sua integração precisa conseguir cair para outro modelo Claude ativo sem editar regra de negócio.
O que monitorar no uso
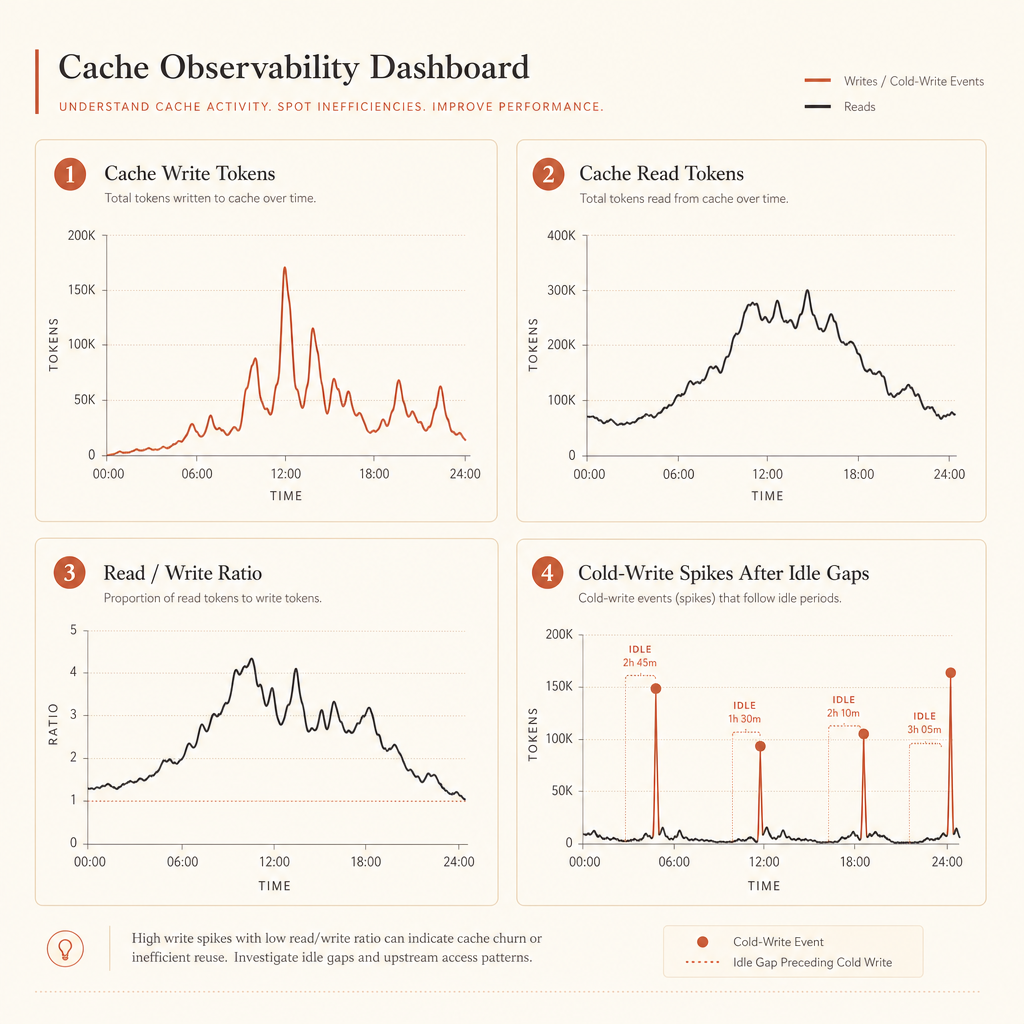
Cache de prompts é invisível até você inspecionar os campos de uso. A Anthropic diz para verificar o cache checando campos como cache_creation_input_tokens e cache_read_input_tokens; se ambos estiverem zerados, o prompt não foi cacheado, muitas vezes porque não atingiu o tamanho mínimo cacheável do modelo (documentação de cache de prompts da Anthropic).
Registre isso por requisição:
const usage = msg.usage;
console.log({
input: usage.input_tokens,
output: usage.output_tokens,
cacheCreate: usage.cache_creation_input_tokens,
cacheRead: usage.cache_read_input_tokens,
});Para objetos de uso mais novos, a documentação da Anthropic também mostra a criação de cache quebrada em buckets específicos de TTL, como ephemeral_5m_input_tokens e ephemeral_1h_input_tokens. Capture o objeto de uso inteiro no começo. Normalize depois, quando você souber exatamente qual gateway e versão do SDK está rodando.
Bons dashboards respondem a quatro perguntas:
- Quantos tokens estão sendo gravados no cache?
- Quantos estão sendo lidos do cache?
- Qual é a razão leitura/gravação de cache por rota?
- Quais prompts criam grandes gravações frias depois de pausas?
Se cache_creation_input_tokens está alto e cache_read_input_tokens fica perto de zero, seu ponto de quebra provavelmente está depois de conteúdo variável. Mova-o para antes.
5 minutos ou 1 hora: escolha pelo comportamento do usuário
Use cache de 5 minutos para loops de requisição apertados. Um agente de código que chama ferramentas a cada 20 segundos, um app de chat em que usuários mandam continuações rapidamente, ou um lote de jobs de classificação parecidos deveriam começar por aí. O prêmio de gravação é só 1,25× e cada leitura renova a vida útil do cache de graça, segundo a documentação da Anthropic (documentação de cache de prompts da Anthropic).
Use cache de 1 hora quando o prefixo caro provavelmente será reutilizado depois de mais de cinco minutos. Fluxos human-in-the-loop são o caso clássico. O mesmo vale para agentes de longa duração em que o modelo manda trabalho para sistemas externos, espera um navegador, consulta CI, ou pausa para aprovação.
Não faça cache de prompts minúsculos. A Anthropic documenta tamanhos mínimos de prompt cacheável por modelo e plataforma; para o Fable 5, o mínimo na Claude API aparece como 512 tokens, enquanto o Bedrock tem mínimos diferentes para alguns modelos (documentação de cache de prompts da Anthropic). Prompts mais curtos podem simplesmente ser processados sem cache.
Um checklist prático:
- Coloque conteúdo estável primeiro: ferramentas, prompts de sistema, exemplos, documentos de referência.
- Deixe dados variáveis depois do prefixo cacheado: timestamps, ids de requisição, texto do usuário.
- Comece com cache automático para conversas.
- Troque para pontos de quebra explícitos quando seu sufixo muda a cada chamada.
- Use TTL de 1 hora só quando as pausas justificarem a gravação 2×.
- Registre os campos de uso antes de declarar vitória.
Conecte via OneHop, depois meça
A integração mais limpa é uma mudança de endpoint em uma linha mais seleção de modelo por env:
export ONEHOP_API_KEY="..."
export ANTHROPIC_BASE_URL="https://api.onehop.ai/v1"
export CLAUDE_MODEL="anthropic/claude-fable-5"Depois mantenha seu código Anthropic Messages e adicione cache_control.
A página do Fable 5 na OneHop atualmente anuncia preços abaixo da lista oficial, crédito inicial de US$ 10 sem cartão, e uma rota Anthropic Messages para o modelo (OneHop). Como o acesso ao Fable 5 está temporariamente suspenso desde a atualização de 12 de junho da Anthropic, trate fallback de modelo como parte do rollout, não como detalhe para depois.
O ganho é simples. Se seu app repete prefixos grandes, leituras em cache a 0,1× transformam engenharia de prompt em engenharia de custo. Comece com cache de 5 minutos. Mova fluxos selecionados para cache de 1 hora quando os logs mostrarem regravações frias depois de pausas. Se quiser o caminho curto para o Claude Fable 5 quando a disponibilidade voltar, teste Claude Fable 5 na OneHop e comece com US$ 10 grátis.

