
Le prompt caching de Claude a un chiffre magnifique et un piège très facile : les lectures depuis le cache coûtent 0,1× l’entrée normale, mais les écritures en cache coûtent plus cher que l’entrée normale. La doc actuelle d’Anthropic indique des écritures en cache 5 minutes à 1,25× le prix de l’entrée, des écritures 1 heure à 2×, et des hits de cache à 0,1× sur les modèles Claude actifs (Anthropic prompt caching docs).
Ça fait du cache une fonctionnalité de pricing, pas juste une fonctionnalité de latence. Si votre app répète un long prompt système, un schéma d’outil, un pack d’exemples, un bundle de politiques, des docs récupérées, ou un état multi-tour, vous devez mesurer les écritures et lectures de cache comme vous mesurez les tokens de sortie.
Un détail à garder en tête aujourd’hui, le 14 juin 2026 : Anthropic a lancé Claude Fable 5 le 9 juin, puis publié une mise à jour le 12 juin indiquant que l’accès à Fable 5 et Mythos 5 était suspendu pendant qu’ils travaillent à le rétablir (Anthropic). OneHop liste aussi anthropic/claude-fable-5, avec support du prompt cache, mais le marque actuellement comme temporairement indisponible sur sa page modèle (OneHop). Construisez l’intégration maintenant, gardez l’id du modèle configurable, et activez-la quand l’accès sera de retour.
Le calcul de cache dont les développeurs ont vraiment besoin
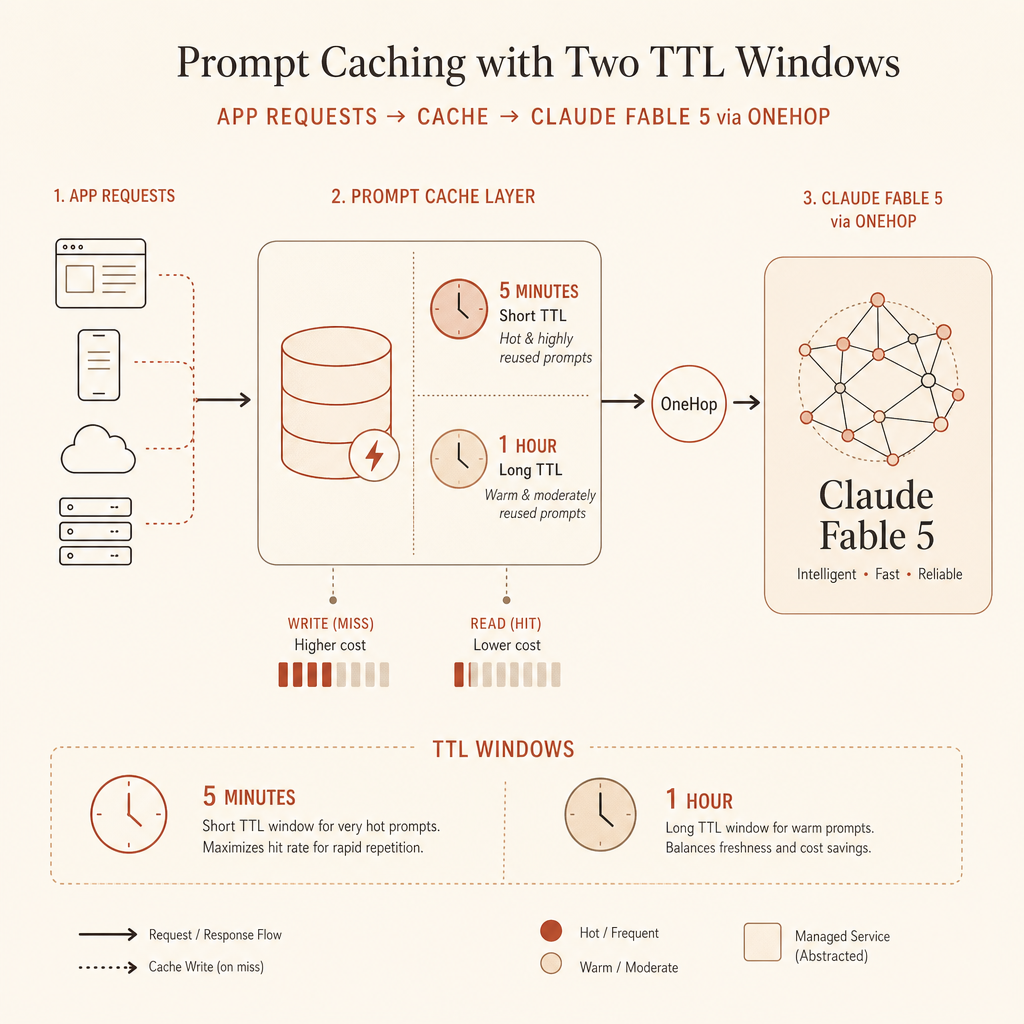
Le prompt cache d’Anthropic stocke des préfixes de prompt. La partie réutilisable doit être identique : les outils, le contenu système et les messages sont pris en compte dans cet ordre, et le cache s’applique jusqu’au bloc marqué avec cache_control (Anthropic prompt caching docs).
Le modèle de prix utile est simple. Supposons que votre préfixe réutilisable fasse 100 000 tokens d’entrée.
| Mode de cache | Multiplicateur du coût d’écriture | Multiplicateur du coût de lecture | Intuition du seuil de rentabilité |
|---|---|---|---|
| Sans cache | 1,0× à chaque requête | aucun | Vous payez toute l’entrée à chaque fois |
| Cache 5 minutes | 1,25× une fois | 0,1× par hit | Rentable dès la première réutilisation |
| Cache 1 heure | 2,0× une fois | 0,1× par hit | Demande plus de réutilisation ou des pauses plus longues |
Pour Claude Fable 5, Anthropic affiche 10 $ par million de tokens d’entrée et 50 $ par million de tokens de sortie dans l’annonce de lancement, et la doc de prompt caching liste les prix du cache Fable 5 à 12,50 $/M pour les écritures 5 minutes, 20 $/M pour les écritures 1 heure, et 1 $/M pour les hits de cache (Anthropic, prompt caching docs).
Avec les prix catalogue d’Anthropic, ce préfixe de 100k tokens coûte :
- Entrée normale :
$1.00 - Écriture 5 minutes :
$1.25 - Écriture 1 heure :
$2.00 - Lecture depuis le cache :
$0.10
Donc si le même préfixe de 100k tokens est utilisé deux fois pendant le TTL, le cache 5 minutes coûte $1.25 + $0.10 = $1.35, contre $2.00 sans cache. Le cache 1 heure coûte $2.10 pour deux utilisations, donc il perd à deux appels, mais gagne dès qu’il y a un troisième appel ou qu’il évite une réécriture à froid après une pause plus longue.
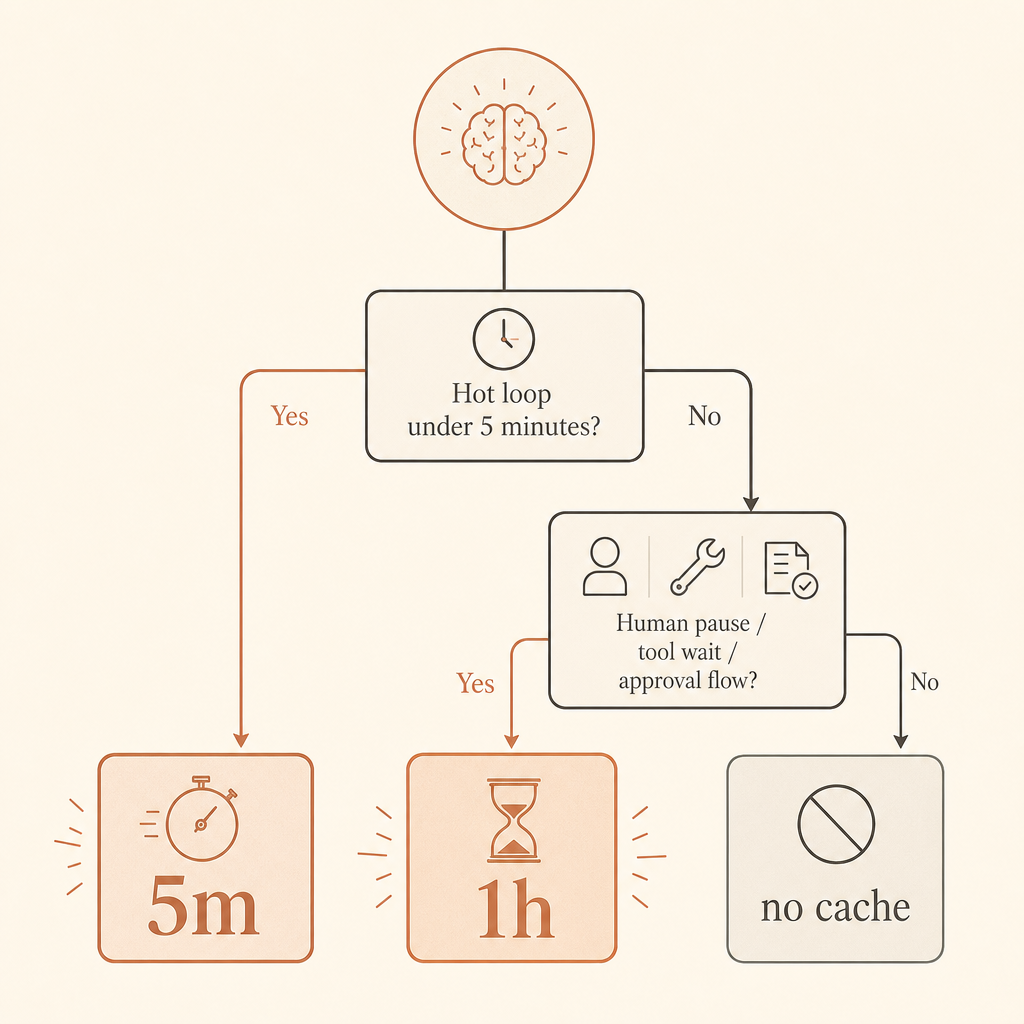
C’est la règle que j’utilise en production : 5 minutes par défaut pour les boucles chaudes ; 1 heure quand les humains font une pause, quand les agents attendent des outils, ou quand les workflows reprennent après plusieurs minutes.
Deux façons d’activer le cache
Anthropic documente maintenant deux approches. Le chemin le plus rapide est le cache automatique : ajoutez un champ cache_control au niveau supérieur et Claude déplace le point de rupture vers l’avant à mesure que la conversation grandit. Le chemin plus contrôlé est celui des points de rupture explicites : mettez cache_control sur le dernier bloc de contenu du préfixe stable (Anthropic prompt caching docs).
Le cache automatique est excellent pour l’historique de chat et l’état d’agent :
import os
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://api.onehop.ai/v1"),
)
message = client.messages.create(
model=os.getenv("CLAUDE_MODEL", "anthropic/claude-fable-5"),
max_tokens=700,
cache_control={"type": "ephemeral"},
system="You are a senior backend engineer. Be concise and specific.",
messages=[
{"role": "user", "content": "My app uses FastAPI, Postgres, and Redis."},
{"role": "assistant", "content": "Got it. What do you want to change?"},
{"role": "user", "content": "Design a cache key strategy for user dashboards."},
],
)
print(message.content[0].text)
print(message.usage.model_dump())C’est le chemin de conversion OneHop : gardez votre requête au style Anthropic, rendez la base URL configurable, et pointez-la vers https://api.onehop.ai/v1. La page modèle de OneHop montre aussi anthropic/claude-fable-5 comme id de modèle et indique que les nouveaux utilisateurs obtiennent 10 $ de crédit gratuit sans carte requise (OneHop). Si vous voulez le raccourci, ouvrez Claude Fable 5 sur OneHop et commencez avec 10 $ gratuits.
Le cache explicite est meilleur quand le préfixe est stable mais que le message utilisateur change à chaque requête. Placez le point de rupture avant la partie qui change :
from anthropic import Anthropic
import os
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/v1",
)
response = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=500,
system=[
{
"type": "text",
"text": open("system_prompt.md").read(),
"cache_control": {"type": "ephemeral"},
}
],
messages=[
{"role": "user", "content": "Review this migration plan for race conditions."}
],
)
print(response.usage.model_dump())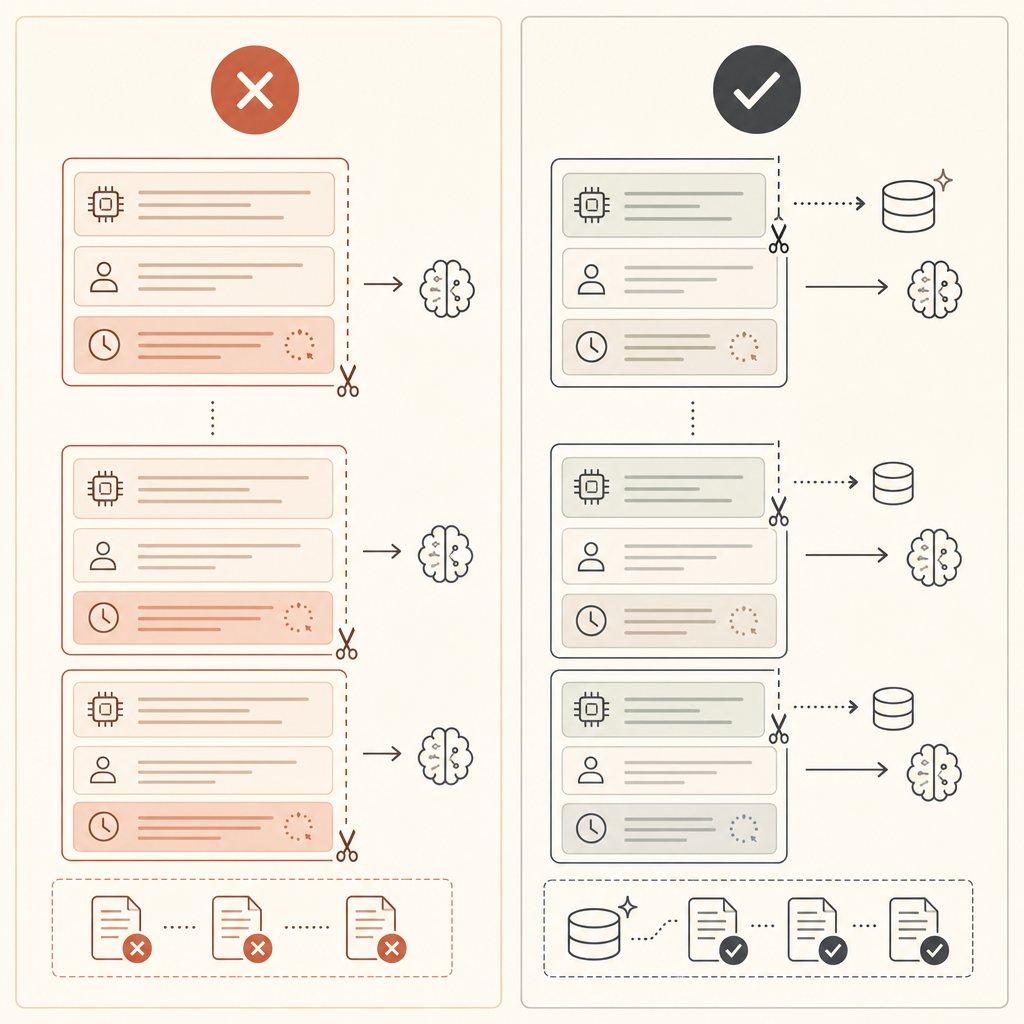
Version TypeScript avec un TTL de 1 heure
Utilisez le cache 1 heure quand l’app a un contexte statique coûteux et de vraies pauses réalistes. Pensez : agents de revue de code qui attendent la CI, copilotes de support client où les humains font des pauses, sessions de recherche juridique, ou analyse de données multi-étapes où les outils prennent plusieurs minutes.
La doc d’Anthropic montre le TTL 1 heure sous la forme {"type":"ephemeral","ttl":"1h"} et précise que le cache automatique utilise 5 minutes par défaut (Anthropic prompt caching docs).
import Anthropic from "@anthropic-ai/sdk";
import fs from "node:fs";
const client = new Anthropic({
apiKey: process.env.ONEHOP_API_KEY!,
baseURL: process.env.ANTHROPIC_BASE_URL ?? "https://api.onehop.ai/v1",
});
const policyPack = fs.readFileSync("policy-pack.md", "utf8");
const msg = await client.messages.create({
model: process.env.CLAUDE_MODEL ?? "anthropic/claude-fable-5",
max_tokens: 800,
system: [
{
type: "text",
text: policyPack,
cache_control: { type: "ephemeral", ttl: "1h" },
},
],
messages: [
{
role: "user",
content: "Apply the policy pack to this refund request: customer used 3 of 10 seats.",
},
],
});
console.log(msg.content);
console.log(msg.usage);Le point important est banal : ne cachez pas le modèle et la base URL au fond du code. Gardez les deux dans des variables d’environnement. Aujourd’hui, la disponibilité de Fable 5 bouge ; votre intégration doit pouvoir basculer vers un autre modèle Claude actif sans modifier la logique métier.
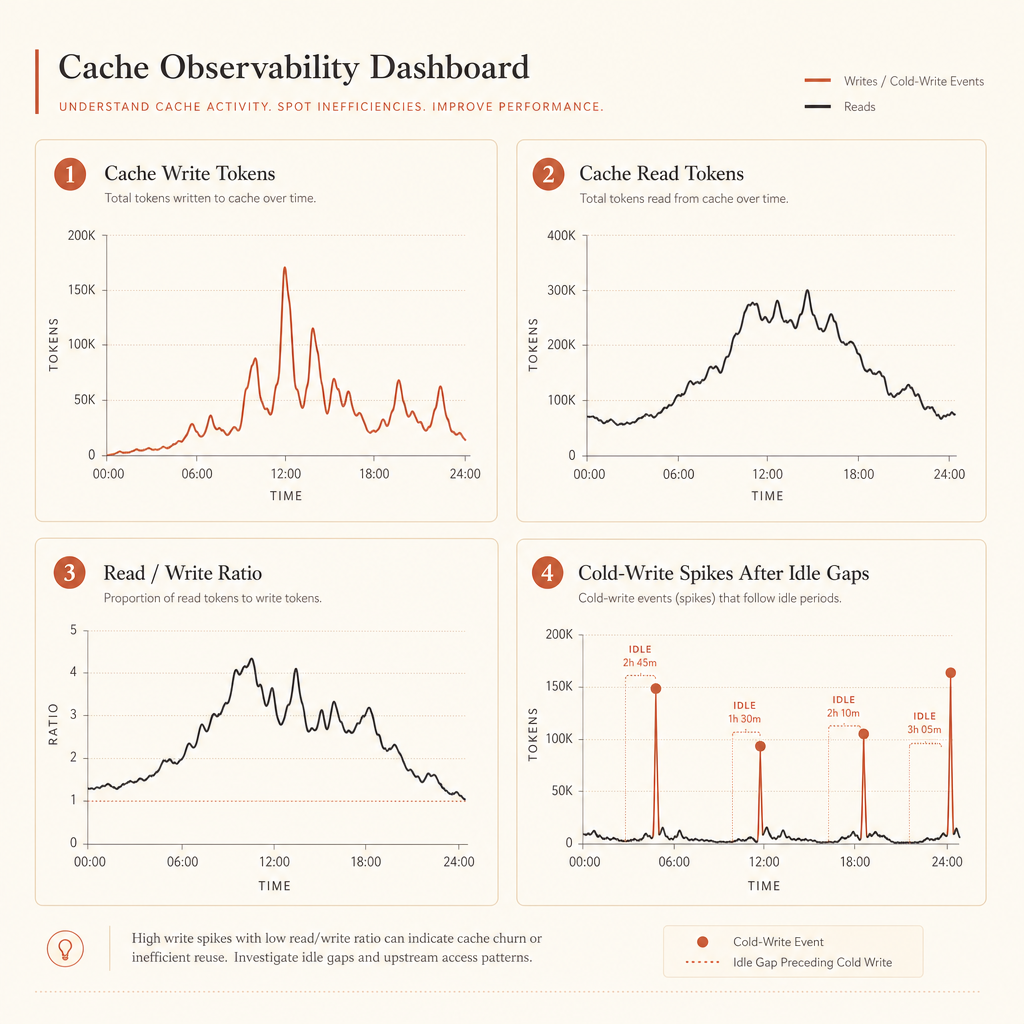
Ce qu’il faut surveiller dans l’usage
Le prompt caching est invisible tant que vous n’inspectez pas les champs d’usage. Anthropic indique de vérifier le cache en regardant des champs comme cache_creation_input_tokens et cache_read_input_tokens ; si les deux valent zéro, le prompt n’a pas été mis en cache, souvent parce qu’il n’atteignait pas la longueur minimale cacheable du modèle (Anthropic prompt caching docs).
Loggez ceci à chaque requête :
const usage = msg.usage;
console.log({
input: usage.input_tokens,
output: usage.output_tokens,
cacheCreate: usage.cache_creation_input_tokens,
cacheRead: usage.cache_read_input_tokens,
});Pour les objets d’usage plus récents, la doc d’Anthropic montre aussi la création de cache découpée en buckets spécifiques au TTL, comme ephemeral_5m_input_tokens et ephemeral_1h_input_tokens. Capturez d’abord l’objet d’usage complet. Normalisez-le plus tard, une fois que vous savez exactement quelle passerelle et quelle version du SDK vous utilisez.
De bons dashboards répondent à quatre questions :
- Combien de tokens sont écrits dans le cache ?
- Combien sont lus depuis le cache ?
- Quel est le ratio lecture/écriture du cache par route ?
- Quels prompts créent de grosses écritures à froid après des pauses ?
Si cache_creation_input_tokens est élevé et que cache_read_input_tokens reste proche de zéro, votre point de rupture est probablement placé après du contenu variable. Déplacez-le plus tôt.
5 minutes ou 1 heure : choisissez selon le comportement utilisateur
Utilisez le cache 5 minutes pour les boucles de requêtes serrées. Un agent de code qui appelle des outils toutes les 20 secondes, une app de chat où les utilisateurs envoient rapidement des suivis, ou un lot de jobs de classification similaires devraient commencer là. Le premium d’écriture n’est que de 1,25× et chaque lecture rafraîchit gratuitement la durée de vie du cache, selon la doc d’Anthropic (Anthropic prompt caching docs).
Utilisez le cache 1 heure quand le préfixe coûteux a de bonnes chances d’être réutilisé après plus de cinq minutes. Les workflows avec humain dans la boucle sont le cas classique. Tout comme les agents longue durée où le modèle envoie du travail à des systèmes externes, attend un navigateur, interroge la CI, ou marque une pause pour approbation.
Ne mettez pas en cache les prompts minuscules. Anthropic documente des longueurs minimales de prompt cacheable par modèle et par plateforme ; pour Fable 5, le minimum de la Claude API est listé à 512 tokens, tandis que Bedrock a des minimums différents pour certains modèles (Anthropic prompt caching docs). Les prompts plus courts peuvent simplement être traités sans cache.
Une checklist pratique :
- Placez le contenu stable en premier : outils, prompts système, exemples, docs de référence.
- Gardez les données variables après le préfixe mis en cache : timestamps, ids de requête, texte utilisateur.
- Commencez avec le cache automatique pour les conversations.
- Passez aux points de rupture explicites quand votre suffixe change à chaque appel.
- N’utilisez le TTL 1 heure que lorsque les pauses justifient l’écriture à 2×.
- Loggez les champs d’usage avant de crier victoire.
Branchez-le via OneHop, puis mesurez
L’intégration la plus propre est un changement d’endpoint sur une ligne plus une sélection de modèle configurée par l’environnement :
export ONEHOP_API_KEY="..."
export ANTHROPIC_BASE_URL="https://api.onehop.ai/v1"
export CLAUDE_MODEL="anthropic/claude-fable-5"Ensuite, gardez votre code Anthropic Messages et ajoutez cache_control.
La page Fable 5 de OneHop annonce actuellement des prix sous le tarif officiel, un crédit de démarrage de 10 $ sans carte, et une route Anthropic Messages pour le modèle (OneHop). Comme l’accès à Fable 5 est temporairement suspendu depuis la mise à jour Anthropic du 12 juin, intégrez le fallback de modèle à votre déploiement, pas comme une pensée après coup.
Le gain est simple. Si votre app répète de gros préfixes, les lectures en cache à 0,1× transforment le prompt engineering en ingénierie des coûts. Commencez avec le cache 5 minutes. Déplacez certains workflows vers le cache 1 heure quand les logs montrent des réécritures à froid après des pauses. Si vous voulez le chemin court pour Claude Fable 5 quand la disponibilité revient, essayez Claude Fable 5 sur OneHop et commencez avec 10 $ gratuits.

