
Anthropic 在 2026 年 3 月 9 日为 Claude Code 发布了 Code Review,同时给出了一个足以让每个工程经理皱眉的数字:在 Anthropic 内部,每位工程师的代码产出一年增长了 200%,而评审成了瓶颈(Anthropic)。这才是真正的重点。AI 编码并没有消灭评审工作。它只是把压力点挪了地方。
有用的回应不是“让 Claude 批改自己的作业”。那只会造出一台礼貌的 bug 工厂。有用的回应,是把 Claude Code Review 变成一个可重复执行的 PR 关卡,并且里面写的是你团队真正在乎的规则。
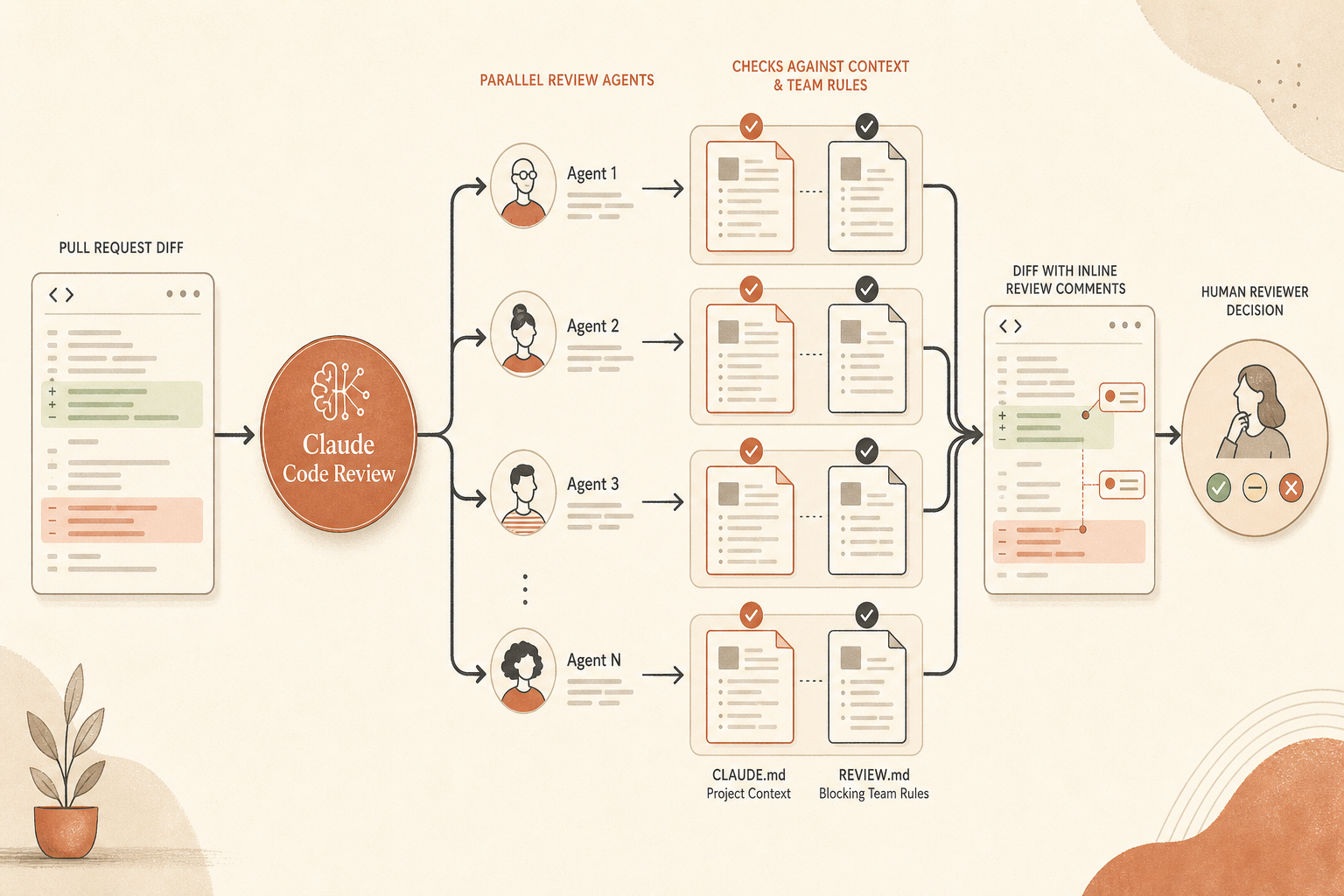
Anthropic 现在的配置文档已经让这件事变得可操作。评审者可以通过评论 @claude review 触发评审,Code Review 会读取仓库里的 CLAUDE.md 文件,以及根目录下的 REVIEW.md。违反 CLAUDE.md 的问题会被当作 nit 级别发现,Claude 甚至还能指出某个 PR 让 CLAUDE.md 过时了(Claude Help Center)。REVIEW.md 则用来放只针对评审的规则,包括 Anthropic 给出的例子:“任何新的 API 路由都必须有集成测试。”
这句话就是关键。别再要求 AI 评审“仔细一点”。开始给它仓库法律。
问题:AI 让 PR 评审更吵了
社区里的争论很混乱,因为双方其实都对。
在 Claude Code Review 的 Hacker News 讨论串里,开发者质疑价格、价值,以及一个让人不太舒服的事实:一家 AI 厂商正在销售一个用来评审 AI 生成代码的评审者。一位评论者拿 Anthropic 自己关于大型 PR 的数据说事,把它解读成 agentic development 质量的警讯;也有人认为,这种深度第二双眼睛恰恰是工具发挥价值的地方(Hacker News)。
Reddit 上是同一场争论的更现实版本。在一个帖子里,一位开发者问大家是否真的信任 Claude 生成的代码到可以跳过评审,因为 Claude 有时会写出他们自己都看不懂的代码。回答很直接:评审它,验证它,保持改动小,不要假装委派就等于责任消失(Reddit)。另一个帖子里,人们讨论用单独的 AI agents 来评审 Claude 的输出,但仍然会把评审本身拿到代码库里核对(Reddit)。
我的看法:用 Claude 评审 Claude 写的代码可以,但前提是你不要把它当成独立判断。把它当成一个非常快、非常字面化、上下文巨大但没有所有权的初级评审者。它应该抓住无聊的遗漏、跨文件不一致、缺失测试、安全坑、过期文档,以及人类评审很可能扫一眼就跳过去的地方。
它不应该是最终批准者。
Anthropic 也直说了这一点。Code Review 本身不会批准 PR,也不会自己阻塞 PR。现有评审流程保持不变(Claude Help Center)。所以这里的“关卡”是团队关卡:Claude 跑完之前不能人工批准,Important 发现要么解决要么明确豁免,PR 作者必须处理仓库特定规则。
这很无聊。很好。无聊的关卡能避免事故。
设置:两个 Markdown 文件,两份工作
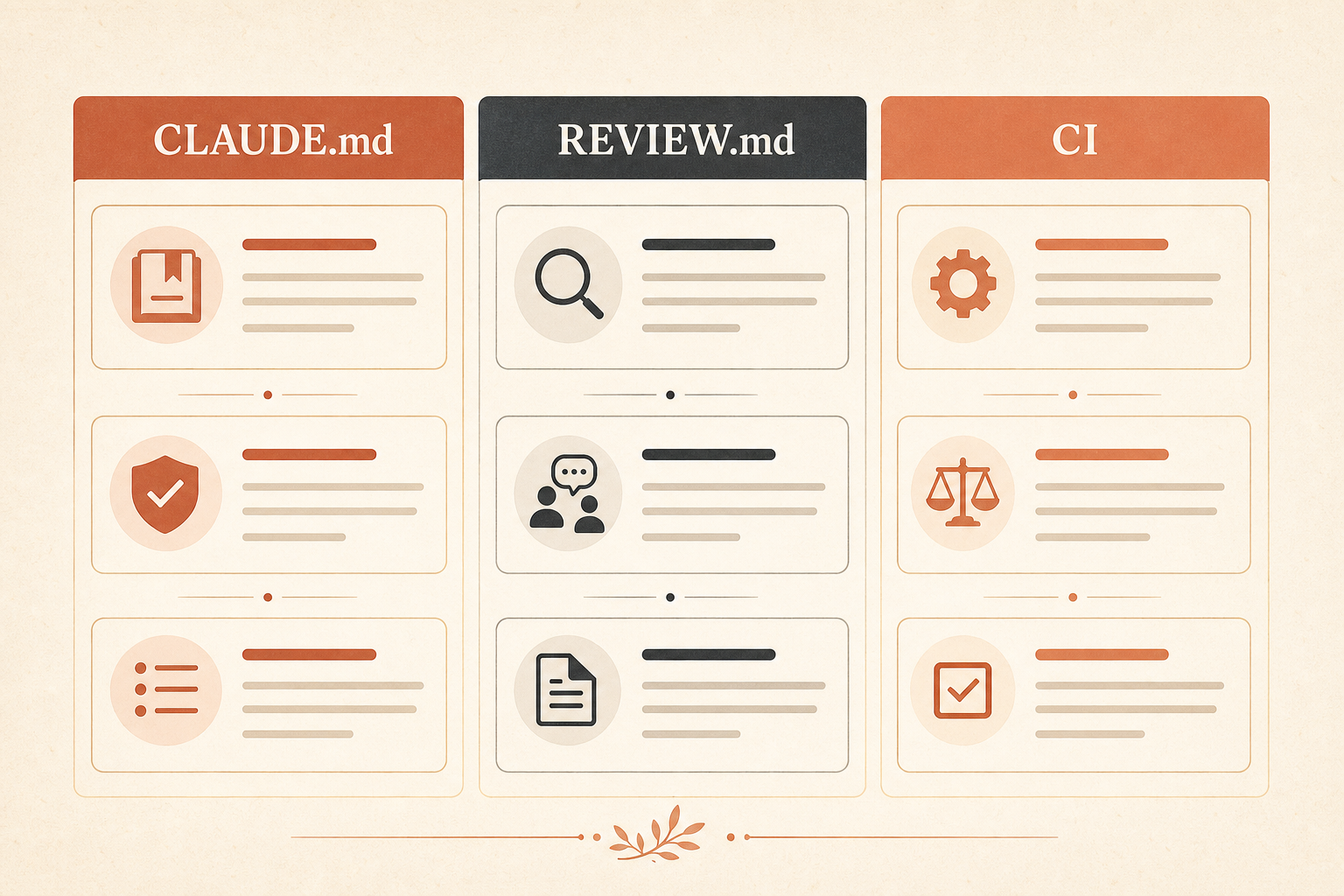
Claude Code Review 有两个重要的记忆表面。
CLAUDE.md 是共享项目上下文。它通常适用于 Claude Code 会话,而不只是评审。Anthropic 建议用它放命令、约定、简短架构说明、硬性约束和已知坑。他们还建议保持高信噪比,大致控制在 200 行以内,因为它会被加载进上下文;不过在 Enterprise 会话里,prompt caching 会降低重复 token 成本(Claude Help Center)。
REVIEW.md 不一样。它放在仓库根目录,只用于评审。Anthropic 的 Code Review 文档说,它的内容会作为高优先级指令注入到每个评审代理里,适合用来控制严重级别、nit 数量、跳过规则、仓库特定检查、验证标准和重新评审行为(Claude Code Docs)。
我会这样拆:
| File | Purpose | Good rules | Bad rules |
|---|---|---|---|
CLAUDE.md | 所有 Claude 工作的项目记忆 | 构建命令、架构、“用 Zod 做请求校验” | 冗长历史、模糊偏好、重复 API 文档 |
REVIEW.md | PR 评审政策 | “新 API 路由必须有集成测试” | 泛泛而谈的“写干净代码”建议 |
| CI config | 确定性执行 | Typecheck、单元测试、lint、migration 检查 | 用 LLM 检查编译器能证明的东西 |
把稳定上下文放进 CLAUDE.md。把评审压力放进 REVIEW.md。把任何确定性的东西放进 CI。
给 API 路由设置真正的关卡
假设一个后端团队老是提交只有 happy-path 单元测试、没有集成覆盖的路由。人类评审有时能抓到。Claude 生成的 PR 会让问题更糟,因为 agent 很擅长生成看起来合理的 handler 代码,却不擅长记住团队踩过的评审旧坑。
先从 CLAUDE.md 开始:
# Project conventions
- API routes live in `src/routes`.
- Integration tests live in `tests/integration`.
- Use `requireAuth()` on non-public routes.
- Validate request bodies with Zod schemas from `src/schemas`.
- Run `pnpm test:integration` before marking API work complete.然后在根目录添加 REVIEW.md:
# Code Review Rules
Treat these as Important unless stated otherwise.
## API routes
If a PR adds or changes a file under `src/routes/**`:
- Flag missing integration test coverage in `tests/integration/**`.
- Flag routes without explicit auth, unless the route is listed as public.
- Flag request bodies that are not validated with a Zod schema.
Do not accept unit tests as a substitute for route-level integration tests.
## Evidence bar
For every Important finding, cite the changed file and the missing or conflicting evidence.
If the claim depends on a convention, cite this REVIEW.md rule.最后那一节很重要。LLM 评审可能一本正经地胡说。要求证据,会迫使评审把发现绑定到某个文件、某一行或一条明确政策上。它不会消灭误报,但会把评审从“凭感觉”改成“拿证据来”。
现在某个 PR 添加了:
// src/routes/billing.ts
router.post("/billing/plan", async (req, res) => {
const result = await updatePlan(req.body.planId);
res.json(result);
});一条好的 Claude Code Review 评论应该类似这样:
- Important:
src/routes/billing.ts添加了一个新的 POST 路由,但看不到显式 auth。 - Important:请求体读取了
req.body.planId,但没有 schema validation。 - Important:没有在
tests/integration/**下添加匹配的集成测试。
最终仍然由人类评审决定。也许 router 在更高层应用了 auth middleware。也许集成测试存在于生成的 contract suite 里。没问题。只要这个关卡在合并前迫使大家讨论,它就完成了工作。
触发它,但别烧钱
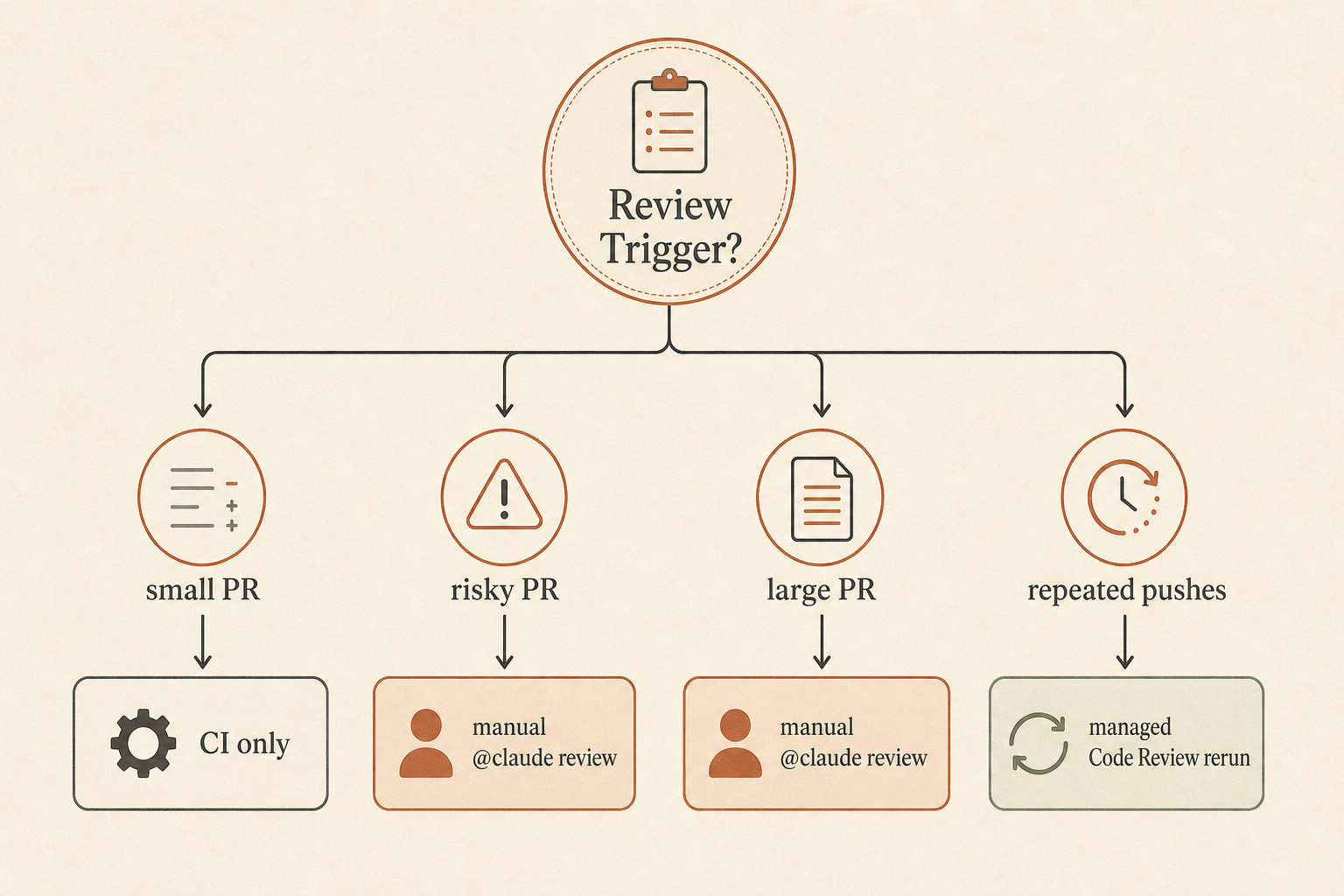
Anthropic 给了三种仓库触发模式:PR 创建后运行一次、每次 push 后运行,或者手动。手动意味着在有人评论 @claude review 之前没有成本;之后该 PR 的后续 push 会自动触发评审(Claude Help Center)。
对大多数团队来说,我不会一上来就用“每次 push 后运行”。Anthropic 说 Code Review 平均大约 20 分钟,每次评审通常花费 15 到 25 美元,并随 PR 大小和复杂度增长(Anthropic)。跟生产事故比这很便宜。跟跑 ESLint 比这很贵。
用分层关卡:
- 每个 PR 都跑正常 CI。
- 有风险的 PR 使用
@claude review。 - 大型 PR、auth 变更、支付变更、migrations 和 public API 变更,必须先经过 Claude review 才能人工批准。
- 重大改动后重复 Claude review,而不是每个错别字修复后都跑。
- 人类负责最终批准。
一个轻量级 GitHub PR checklist 可以把关卡写清楚:
## AI Review Gate
- [ ] CI is green.
- [ ] `@claude review` has run, or this PR is exempt.
- [ ] Important findings are fixed or explained.
- [ ] If this PR changes conventions, `CLAUDE.md` is updated.
- [ ] If this PR changes review policy, `REVIEW.md` is updated.如果你更喜欢在自己的 workflow 里运行 Claude,Anthropic 的 GitHub Actions 文档展示了 anthropics/claude-code-action@v1 和 code-review plugin 配置,并照例提醒用 GitHub Secrets 保存 API keys(Claude Code Docs)。这条路线给你更多 CI 控制。托管的 Code Review 路线则给你 Anthropic 描述的更深层多代理评审者。
别把它们混为一谈。一个是可编程自动化。另一个是付费的、深度优先的评审者。
诀窍:让 Claude 评审契约,而不是风格
糟糕的 REVIEW.md 文件读起来像幸运饼干:
Please ensure the code is clean, maintainable, secure, and well tested.这只会产出一团糊。
好的 REVIEW.md 文件写的是伤疤:
## Database migrations
Flag as Important if:
- A migration adds a non-null column without a default on an existing table.
- A migration backfills data without batching.
- Application code starts reading a new column before the migration is deployed.
Skip:
- Formatting comments in generated Prisma client files.这才是 AI 评审变得有用的地方。它不是在替代高级工程师的品味。它是在每个 PR 上重放团队的机构记忆。
一些好用的规则:
## Re-review behavior
On the first review, report Important and Nit findings.
On later reviews of the same PR, suppress new Nits unless they are directly caused by the latest push.
## Test policy
Flag missing tests only when the changed behavior is observable through a stable public interface.
Do not request snapshot tests for purely visual copy changes.
## Security policy
Flag any new endpoint that:
- Accepts user input without validation.
- Performs authorization by trusting a user-provided account ID.
- Logs tokens, session IDs, API keys, or full request bodies.注意少了什么:“让代码优雅一点。”人类可以在评审里争论优雅。Claude 应该检查契约。
这些讨论漏掉了什么
HN 和 Reddit 的争论一直围着一个问题转:AI 是否应该评审 AI 代码?
问题问错了。
正确的问题是:你愿意把评审里的哪些部分明确写出来?
如果你的评审文化只存在于高级工程师脑子里,Claude Code Review 会显得吵闹又任性。如果你的评审文化被写成仓库规则,它就会变成放大器。CLAUDE.md 告诉 Claude 项目如何运作。REVIEW.md 告诉 Claude 你的团队拒绝合并什么。
这也回答了“为了 Claude 写文档”的抱怨。是的,开发者现在在给一个 agent 写文档。这听起来很荒唐,直到你意识到这些文档也是入职材料、评审政策和事故预防。一份好的 CLAUDE.md 对人类来说,也是更好的“这个仓库怎么工作”文件。
锋利的一面是责任。如果 Claude 漏掉了 bug,仍然是你合并的。如果 Claude 编造了 bug,仍然需要你驳回。如果 Claude 评审自己的输出,你仍然需要独立信号:测试、类型系统、静态分析、可观测性,以及一个真正理解这次改动的人。
把 Claude Code Review 当作关卡,而不是法官。让它每次都问那些烦人的问题:
- 集成测试在哪里?
- auth 在哪里执行?
- 这个 PR 是否让
CLAUDE.md变成了假的? - 这个生成文件值得评论吗?
- 这个发现有代码支撑,还是只是猜测?
对合适的 PR 来说,这就足够回本了。
在 Claude Fable 5 on OneHop 上试试同样的设置,drop-in,并且从 $10 免费额度开始。
延伸阅读:Claude Fable 5 入门。

