
Anthropic a lancé Code Review pour Claude Code le 9 mars 2026, avec un chiffre qui devrait faire grimacer n’importe quel manager engineering : chez Anthropic, la production de code par ingénieur avait augmenté de 200 % en un an, et la review était devenue le goulot d’étranglement (Anthropic). C’est ça, la vraie histoire. Le code généré par IA n’a pas supprimé le travail de review. Il a déplacé le point de pression.
La bonne réponse n’est pas : « laissons Claude corriger ses propres copies ». C’est comme ça qu’on fabrique une usine à bugs polie. La bonne réponse, c’est de transformer Claude Code Review en garde-fou PR répétable, avec des règles auxquelles votre équipe croit vraiment.
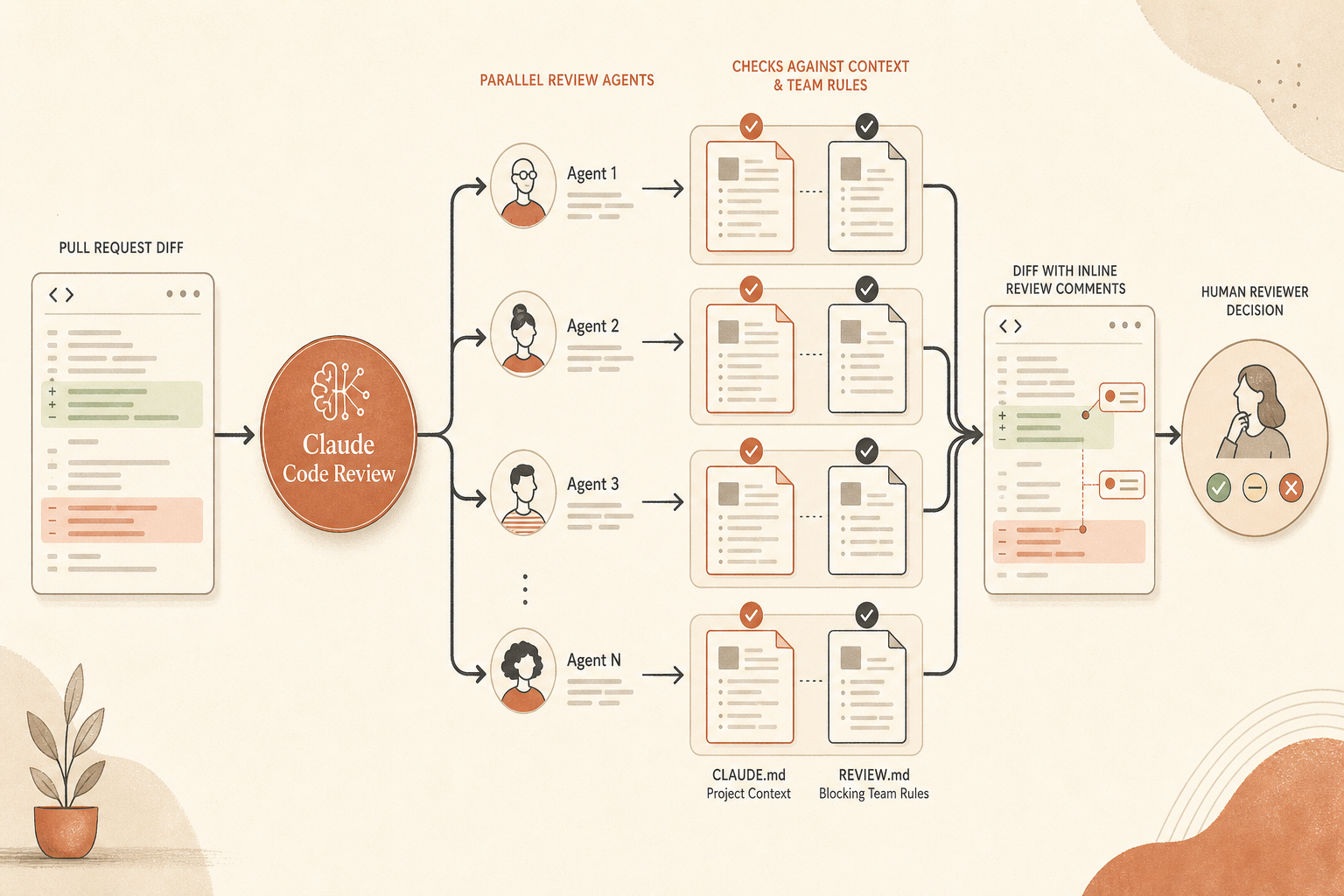
La documentation de configuration d’Anthropic rend désormais ça praticable. Un reviewer peut déclencher une review en commentant @claude review, et Code Review lit les fichiers CLAUDE.md du dépôt ainsi qu’un REVIEW.md à la racine. Les violations de CLAUDE.md sont traitées comme des remarques de niveau nit, et Claude peut même signaler une PR qui rend CLAUDE.md obsolète (Claude Help Center). REVIEW.md, c’est là que vous mettez les règles réservées à la review, y compris l’exemple donné par Anthropic : « toute nouvelle route API doit avoir un test d’intégration ».
Cette phrase est le pivot. Arrêtez de demander aux reviewers IA « d’être prudents ». Donnez-leur la loi du repo.
Le problème : l’IA a rendu la review de PR plus bruyante
Le débat dans la communauté est confus parce que les deux camps ont raison.
Dans le fil Hacker News sur Claude Code Review, des développeurs ont critiqué le prix, la valeur, et le malaise de voir un fournisseur d’IA vendre un reviewer pour du code généré par IA. Un commentateur a pointé les chiffres d’Anthropic sur les grosses PR et les a lus comme un signal d’alerte sur la qualité du développement agentique, tandis que d’autres soutenaient qu’un deuxième regard approfondi est précisément l’endroit où l’outil mérite sa place (Hacker News).
Reddit a la version plus concrète du même débat. Dans un fil, un développeur demandait si les gens faisaient vraiment assez confiance au code généré par Claude pour sauter la review, parce que Claude écrit parfois du code qu’ils ne comprennent pas. Les réponses étaient directes : relisez-le, validez-le, gardez les changements petits, et ne faites pas semblant que déléguer fait disparaître la responsabilité (Reddit). Dans un autre fil, les gens discutaient de l’usage d’agents IA séparés pour relire la sortie de Claude, tout en vérifiant quand même la review elle-même contre le codebase (Reddit).
Mon avis : utiliser Claude pour relire du code écrit par Claude, c’est acceptable si vous ne le traitez pas comme un jugement indépendant. Voyez-le comme un reviewer junior très rapide, très littéral, avec un énorme contexte et aucune responsabilité d’ownership. Il doit attraper les oublis ennuyeux, les incohérences entre fichiers, les tests manquants, les pièges de sécurité, la doc périmée, et les endroits qu’un reviewer humain risque de survoler.
Il ne doit pas être l’approbateur final.
Anthropic le dit directement. Code Review n’approuve pas les PR et ne les bloque pas de lui-même. Les workflows de review existants restent en place (Claude Help Center). Donc le « garde-fou » est un garde-fou d’équipe : pas d’approbation humaine tant que Claude n’a pas tourné, que les findings Important ne sont pas résolus ou explicitement écartés, et que l’auteur de la PR n’a pas traité les règles propres au repo.
C’est ennuyeux. Très bien. Les garde-fous ennuyeux évitent les incidents.
La configuration : deux fichiers Markdown, deux rôles
Claude Code Review a deux surfaces de mémoire qui comptent.
CLAUDE.md est le contexte projet partagé. Il s’applique aux sessions Claude Code en général, pas seulement à la review. Anthropic recommande de l’utiliser pour les commandes, conventions, notes d’architecture courtes, contraintes strictes et pièges connus. Ils recommandent aussi de le garder très dense en signal, grosso modo sous les 200 lignes, parce qu’il est chargé dans le contexte, même si le prompt caching réduit le coût répété en tokens dans les sessions Enterprise (Claude Help Center).
REVIEW.md est différent. Il vit à la racine du dépôt et ne sert qu’à la review. La documentation Code Review d’Anthropic dit que son contenu est injecté dans chaque agent de review comme instructions haute priorité, et que c’est l’endroit où contrôler la sévérité, le volume de nits, les règles de skip, les vérifications propres au repo, les standards de vérification et le comportement en re-review (Claude Code Docs).
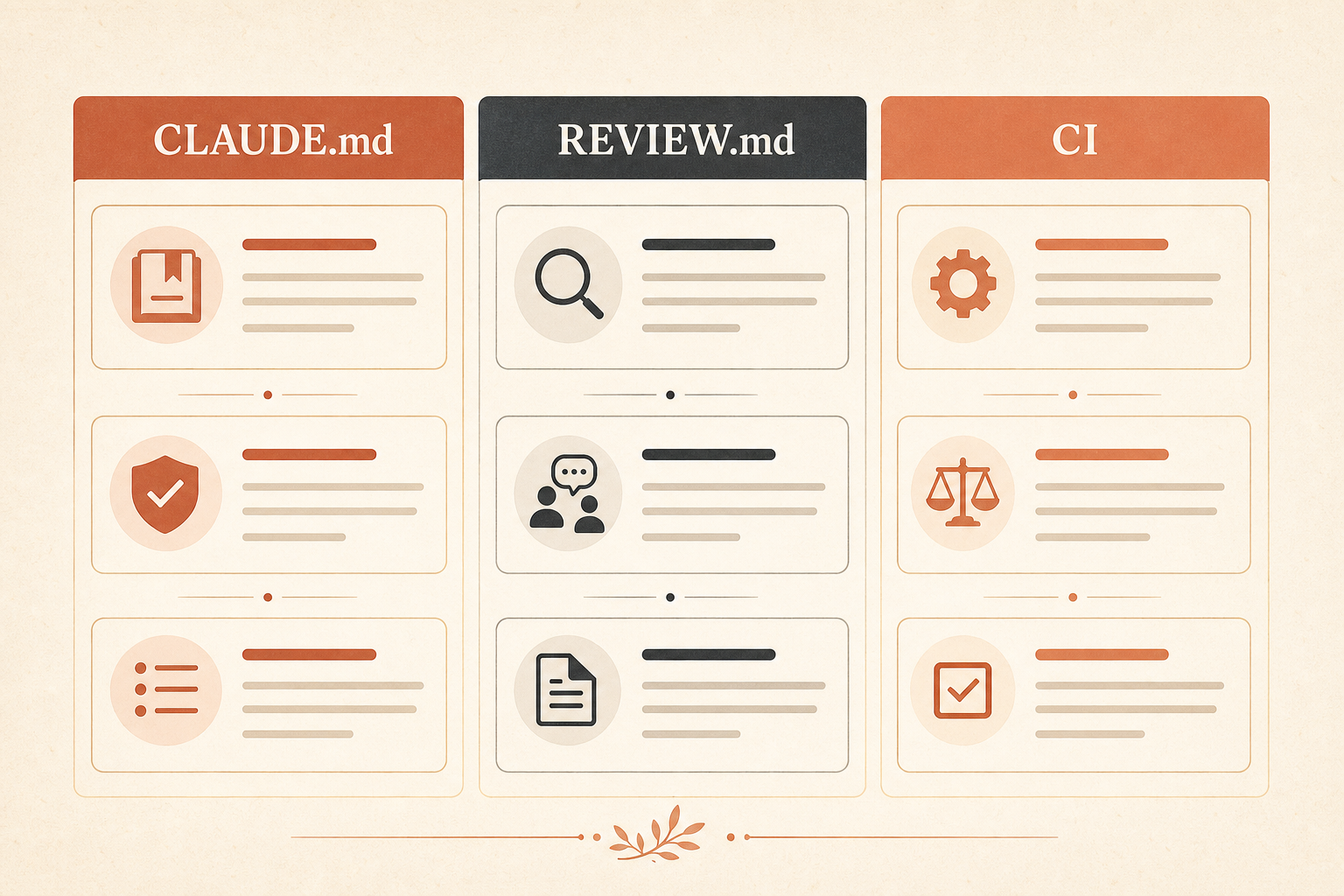
Voici la séparation que j’utilise :
| File | Purpose | Good rules | Bad rules |
|---|---|---|---|
CLAUDE.md | Mémoire projet pour tout le travail Claude | Commandes de build, architecture, « utiliser Zod pour la validation des requêtes » | Longs historiques, préférences vagues, documentation API dupliquée |
REVIEW.md | Politique de review de PR | « Les nouvelles routes API exigent des tests d’intégration » | Conseils génériques du type « écrire du code propre » |
| Config CI | Application déterministe | Typecheck, tests unitaires, lint, vérifications de migration | Vérifications uniquement LLM pour des choses qu’un compilateur peut prouver |
Mettez le contexte stable dans CLAUDE.md. Mettez la pression de review dans REVIEW.md. Mettez tout ce qui est déterministe dans la CI.
Un vrai garde-fou pour les routes API
Imaginez une équipe backend qui continue à livrer des routes avec des tests unitaires sur le happy path, mais sans couverture d’intégration. Les reviewers humains le voient parfois. Les PR générées par Claude aggravent le problème, parce que l’agent sait produire du code de handler plausible et oublie mal les cicatrices de review propres à l’équipe.
Commencez par CLAUDE.md :
# Project conventions
- API routes live in `src/routes`.
- Integration tests live in `tests/integration`.
- Use `requireAuth()` on non-public routes.
- Validate request bodies with Zod schemas from `src/schemas`.
- Run `pnpm test:integration` before marking API work complete.Puis ajoutez un REVIEW.md à la racine :
# Code Review Rules
Treat these as Important unless stated otherwise.
## API routes
If a PR adds or changes a file under `src/routes/**`:
- Flag missing integration test coverage in `tests/integration/**`.
- Flag routes without explicit auth, unless the route is listed as public.
- Flag request bodies that are not validated with a Zod schema.
Do not accept unit tests as a substitute for route-level integration tests.
## Evidence bar
For every Important finding, cite the changed file and the missing or conflicting evidence.
If the claim depends on a convention, cite this REVIEW.md rule.Cette dernière section compte. Les reviewers LLM peuvent produire du n’importe quoi avec assurance. Exiger des preuves force la review à rattacher un finding à un fichier, une ligne, ou une politique explicite. Ça n’éliminera pas les faux positifs, mais ça transforme la review : on passe de « vibes » à « montre-moi ».
Maintenant, une PR ajoute :
// src/routes/billing.ts
router.post("/billing/plan", async (req, res) => {
const result = await updatePlan(req.body.planId);
res.json(result);
});Un bon commentaire de Claude Code Review devrait dire quelque chose comme :
- Important :
src/routes/billing.tsajoute une nouvelle route POST sans auth visible. - Important : le body de requête lit
req.body.planIdsans validation par schéma. - Important : aucun test d’intégration correspondant n’a été ajouté sous
tests/integration/**.
Le reviewer humain décide toujours. Peut-être que le router a un middleware d’auth appliqué plus haut. Peut-être que le test d’intégration vit dans une suite de contrats générée. Très bien. Le garde-fou a fait son travail s’il a forcé cette discussion avant le merge.
Le déclencher sans brûler le budget
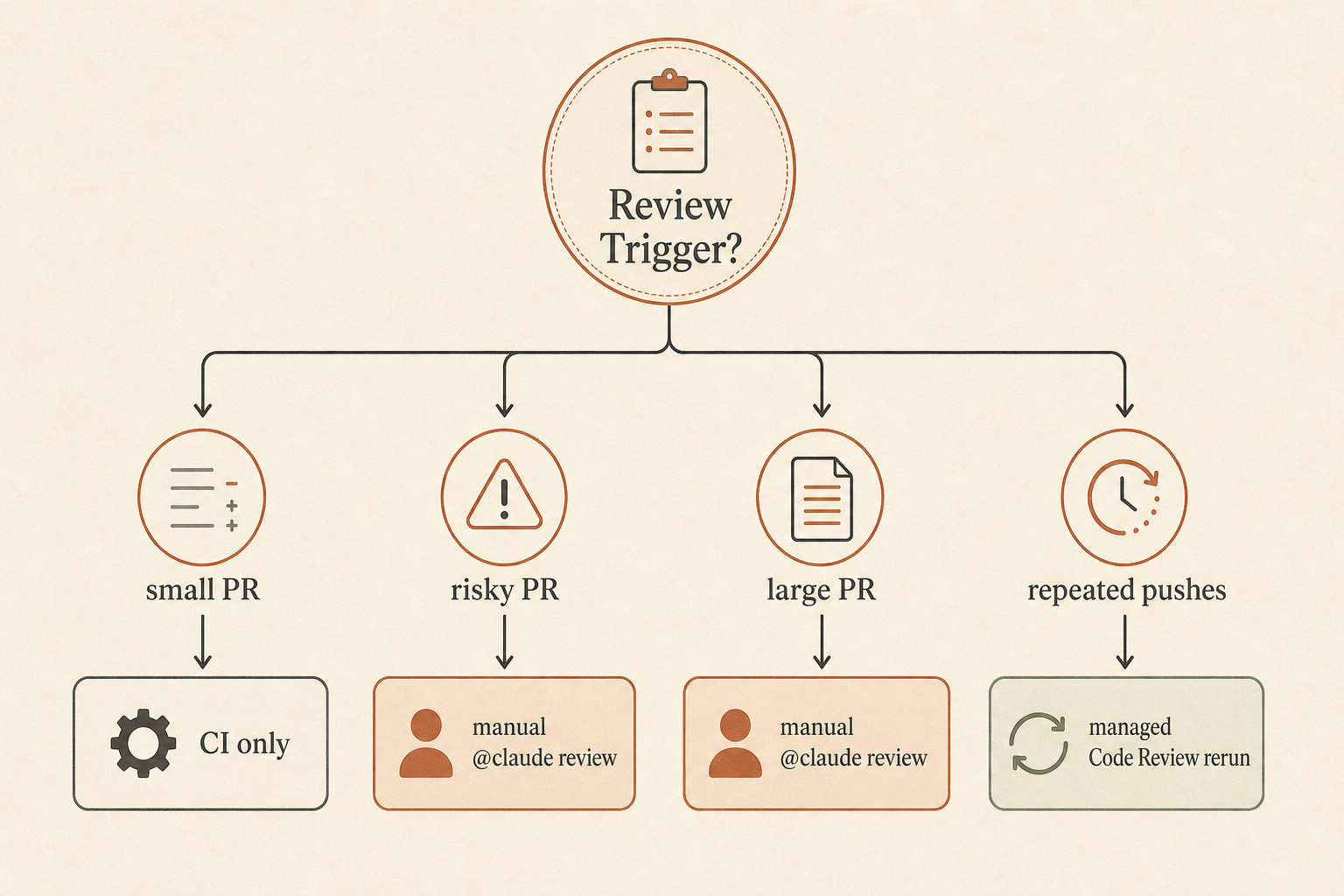
Anthropic propose trois modes de déclenchement par dépôt : une fois après la création de la PR, après chaque push, ou manuel. Manuel signifie aucun coût tant que quelqu’un ne commente pas @claude review ; ensuite, les pushes supplémentaires déclenchent automatiquement des reviews pour cette PR (Claude Help Center).
Pour la plupart des équipes, je ne commencerais pas par « après chaque push ». Anthropic dit que Code Review prend en moyenne environ 20 minutes et coûte généralement entre 15 et 25 dollars par review, avec une échelle qui dépend de la taille et de la complexité de la PR (Anthropic). C’est peu cher comparé à un incident de production. C’est cher comparé à ESLint.
Utilisez un garde-fou par niveaux :
- Chaque PR exécute la CI normale.
- Les PR risquées reçoivent
@claude review. - Les grosses PR, changements d’auth, changements de paiement, migrations et changements d’API publique exigent une review Claude avant approbation humaine.
- Relancez Claude review après les changements majeurs, pas après chaque correction de typo.
- Les humains gardent la responsabilité de l’approbation finale.
Une checklist GitHub PR légère rend le garde-fou explicite :
## AI Review Gate
- [ ] CI is green.
- [ ] `@claude review` has run, or this PR is exempt.
- [ ] Important findings are fixed or explained.
- [ ] If this PR changes conventions, `CLAUDE.md` is updated.
- [ ] If this PR changes review policy, `REVIEW.md` is updated.Si vous préférez exécuter Claude dans votre propre workflow, la documentation GitHub Actions d’Anthropic montre anthropics/claude-code-action@v1 et une configuration de plugin de code-review, avec l’avertissement habituel d’utiliser GitHub Secrets pour les clés API (Claude Code Docs). Cette voie vous donne plus de contrôle CI. La voie Code Review managée vous donne le reviewer multi-agent plus profond décrit par Anthropic.
Ne les confondez pas. L’un est une automatisation programmable. L’autre est un reviewer payant, en profondeur.
L’astuce : faire relire le contrat à Claude, pas le style
Les mauvais fichiers REVIEW.md ressemblent à des biscuits chinois :
Please ensure the code is clean, maintainable, secure, and well tested.Ça produira de la bouillie.
Les bons fichiers REVIEW.md encodent les cicatrices :
## Database migrations
Flag as Important if:
- A migration adds a non-null column without a default on an existing table.
- A migration backfills data without batching.
- Application code starts reading a new column before the migration is deployed.
Skip:
- Formatting comments in generated Prisma client files.C’est là que la review IA devient utile. Elle ne remplace pas le goût de votre senior engineer. Elle rejoue la mémoire institutionnelle de l’équipe sur chaque PR.
Quelques règles qui fonctionnent bien :
## Re-review behavior
On the first review, report Important and Nit findings.
On later reviews of the same PR, suppress new Nits unless they are directly caused by the latest push.
## Test policy
Flag missing tests only when the changed behavior is observable through a stable public interface.
Do not request snapshot tests for purely visual copy changes.
## Security policy
Flag any new endpoint that:
- Accepts user input without validation.
- Performs authorization by trusting a user-provided account ID.
- Logs tokens, session IDs, API keys, or full request bodies.Remarquez ce qui manque : « rendre le code élégant ». Les humains peuvent débattre de l’élégance en review. Claude doit vérifier des contrats.
Ce que les débats oublient
Les débats HN et Reddit tournent toujours autour d’une question : l’IA devrait-elle relire du code IA ?
Mauvaise question.
La bonne question est : quelles parties de la review êtes-vous prêts à rendre explicites ?
Si votre culture de review vit dans la tête des senior engineers, Claude Code Review semblera bruyant et arbitraire. Si votre culture de review est écrite sous forme de règles de repo, elle devient un multiplicateur. CLAUDE.md dit à Claude comment le projet fonctionne. REVIEW.md dit à Claude ce que votre équipe refuse de merger.
Ça répond aussi à la plainte du « on documente pour Claude ». Oui, les développeurs écrivent maintenant de la doc pour un agent. Ça paraît ridicule jusqu’à ce qu’on réalise que cette doc sert aussi d’onboarding, de politique de review et de prévention d’incidents. Un bon CLAUDE.md est aussi un meilleur fichier « comment ce repo fonctionne » pour les humains.
Le vrai tranchant, c’est la responsabilité. Si Claude rate le bug, c’est quand même vous qui l’avez mergé. Si Claude invente un bug, vous devez quand même le rejeter. Si Claude relit sa propre sortie, il vous faut quand même des signaux indépendants : tests, systèmes de types, analyse statique, observabilité, et un humain qui comprend le changement.
Utilisez Claude Code Review comme garde-fou, pas comme juge. Faites-lui poser les questions pénibles à chaque fois :
- Où est le test d’intégration ?
- Où l’auth est-elle appliquée ?
- Cette PR a-t-elle rendu
CLAUDE.mdfaux ? - Est-ce que ce fichier généré mérite vraiment un commentaire ?
- Ce finding est-il étayé par le code, ou seulement par une intuition ?
C’est suffisant pour qu’il se rentabilise sur les bonnes PR.
Essayez la même configuration avec Claude Fable 5 sur OneHop, en drop-in, et commencez avec 10 $ offerts.
À lire aussi : Bien démarrer avec Claude Fable 5.

