
Anthropic shipped Code Review for Claude Code on March 9, 2026, with one number that should make every engineering manager wince: inside Anthropic, code output per engineer had grown 200% in a year, and review became the bottleneck (Anthropic). That is the real story. AI coding did not remove review work. It moved the pressure point.
The useful response is not “let Claude approve its own homework.” That is how you get a polite bug factory. The useful response is to turn Claude Code Review into a repeatable PR gate with rules your team actually believes in.
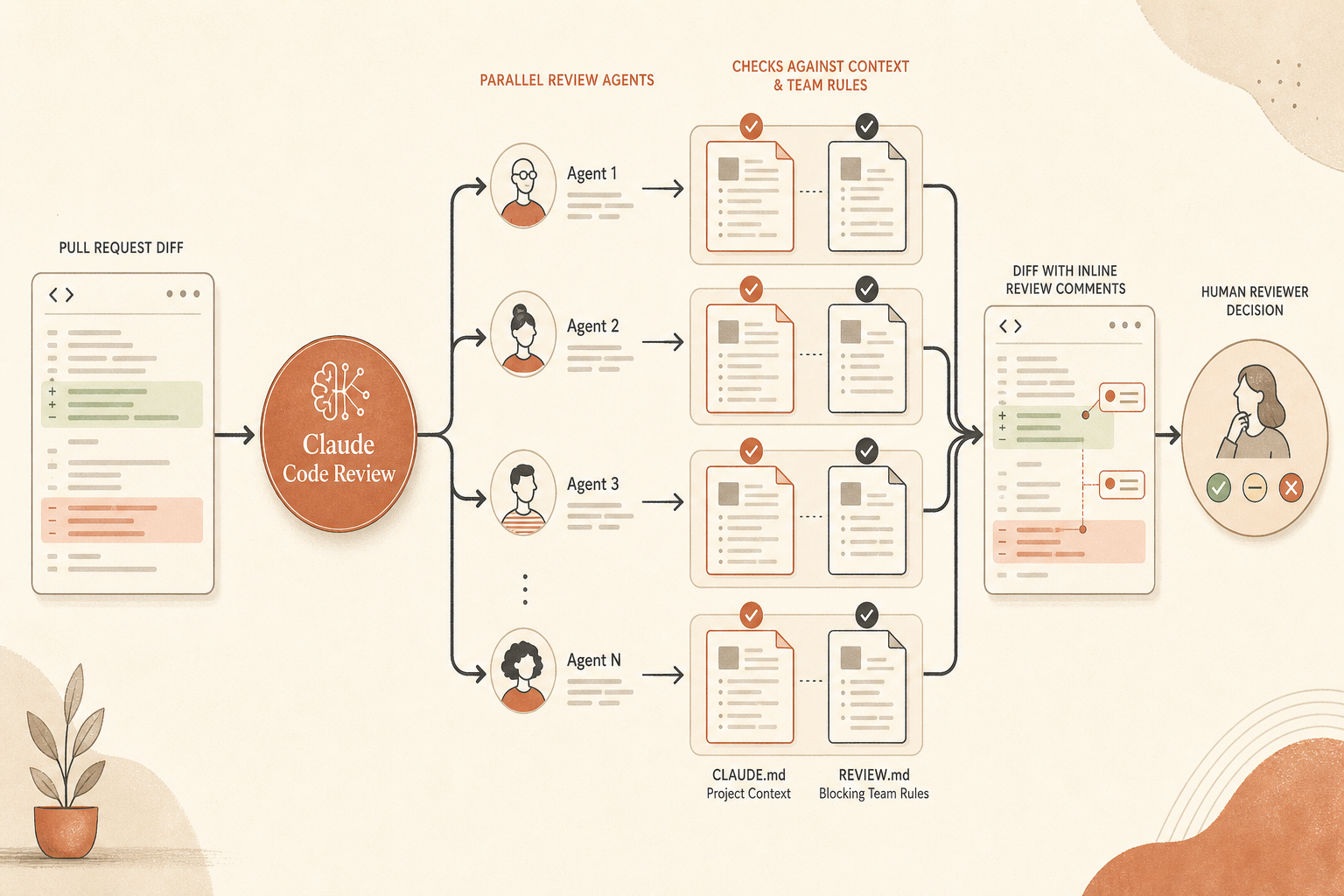
Anthropic’s setup docs now make this practical. A reviewer can trigger a review by commenting @claude review, and Code Review reads repository CLAUDE.md files plus a root-level REVIEW.md. CLAUDE.md violations are treated as nit-level findings, and Claude can even flag a PR that makes CLAUDE.md outdated (Claude Help Center). REVIEW.md is where you put review-only rules, including the example Anthropic gives: “any new API route must have an integration test.”
That one sentence is the hinge. Stop asking AI reviewers to “be careful.” Start giving them repo law.
The Problem: AI Made PR Review Noisier
The community argument is messy because both sides are right.
In the Hacker News thread for Claude Code Review, developers pushed on the price, the value, and the uneasy fact that an AI vendor is selling a reviewer for AI-generated code. One commenter pointed at Anthropic’s own large-PR numbers and read them as a warning sign about agentic development quality, while others argued that a deep second set of eyes is exactly where the tool earns its keep (Hacker News).
Reddit has the more practical version of the same debate. In one thread, a developer asked whether people actually trust Claude-generated code enough to skip review, because Claude sometimes writes code they do not understand. The answers were blunt: review it, validate it, keep changes small, and do not pretend delegation means accountability disappears (Reddit). In another thread, people discussed using separate AI agents to review Claude’s output, while still checking the review itself against the codebase (Reddit).
My take: using Claude to review Claude-written code is fine if you do not treat it as independent judgment. Treat it like a very fast, very literal junior reviewer with huge context and no ownership. It should catch boring omissions, cross-file inconsistencies, missing tests, security footguns, stale docs, and places where a human reviewer is likely to skim.
It should not be the final approver.
Anthropic says this directly. Code Review does not approve PRs or block them by itself. Existing review workflows stay intact (Claude Help Center). So the “gate” is a team gate: no human approval until Claude has run, Important findings are resolved or explicitly waived, and the PR author has addressed repo-specific rules.
That is boring. Good. Boring gates prevent incidents.
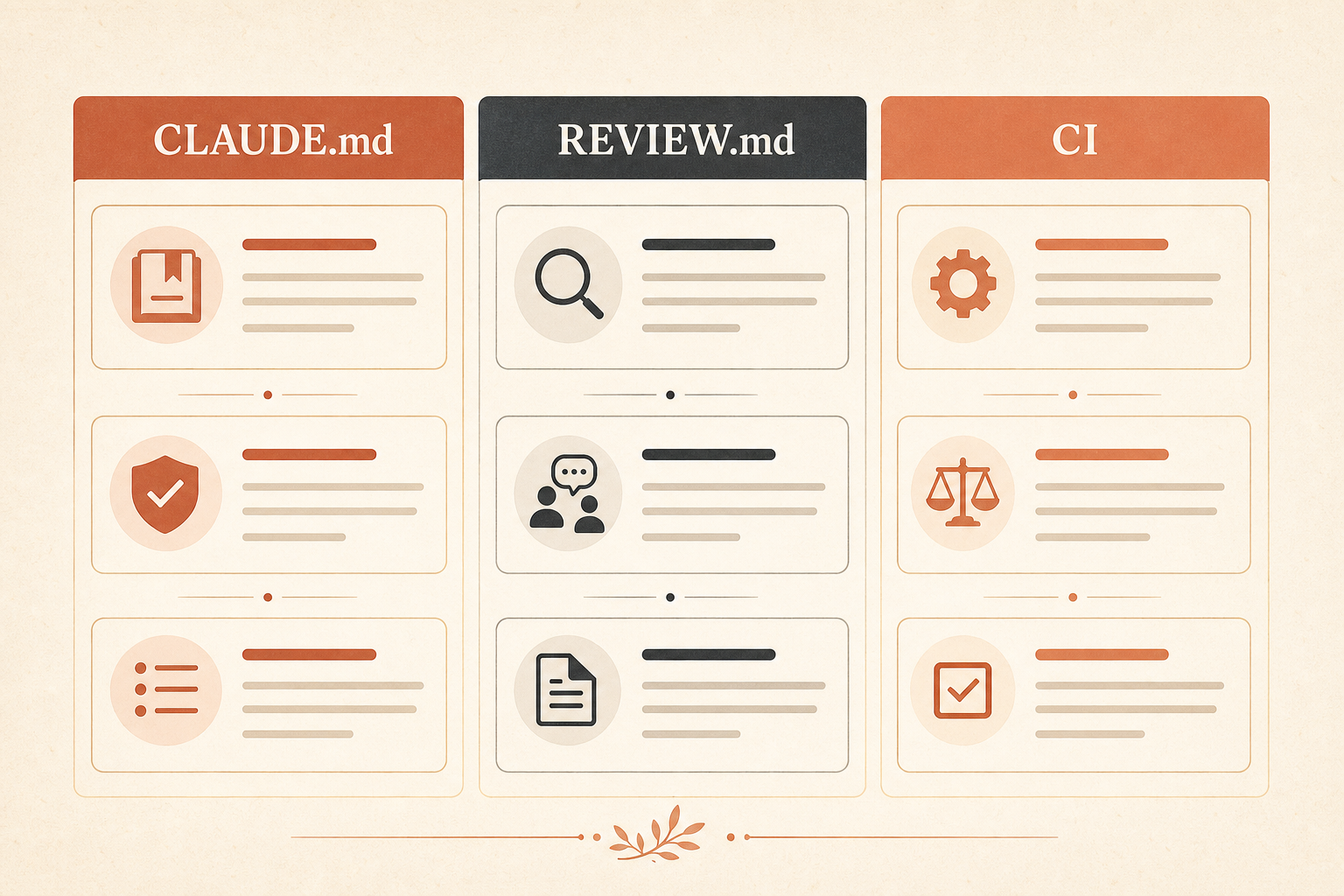
The Setup: Two Markdown Files, Two Jobs
Claude Code Review has two memory surfaces that matter.
CLAUDE.md is shared project context. It applies to Claude Code sessions generally, not just review. Anthropic recommends using it for commands, conventions, short architecture notes, hard constraints, and known gotchas. They also recommend keeping it signal-dense, roughly under 200 lines, because it is loaded into context, even though prompt caching reduces repeated token cost in Enterprise sessions (Claude Help Center).
REVIEW.md is different. It lives at the repository root and is review-only. Anthropic’s Code Review docs say its contents are injected into every review agent as high-priority instructions, and that it is the place to control severity, nit volume, skip rules, repo-specific checks, verification standards, and re-review behavior (Claude Code Docs).
Here is the split I use:
| File | Purpose | Good rules | Bad rules |
|---|---|---|---|
CLAUDE.md | Project memory for all Claude work | Build commands, architecture, “use Zod for request validation” | Long histories, vague preferences, duplicate API docs |
REVIEW.md | PR review policy | “New API routes require integration tests” | Generic “write clean code” advice |
| CI config | Deterministic enforcement | Typecheck, unit tests, lint, migration checks | LLM-only checks for things a compiler can prove |
Put stable context in CLAUDE.md. Put review pressure in REVIEW.md. Put anything deterministic in CI.
A Real Gate for API Routes
Assume a backend team keeps shipping routes with happy-path unit tests but no integration coverage. Human reviewers catch it sometimes. Claude-generated PRs make it worse because the agent is good at producing plausible handler code and bad at remembering team-specific review scars.
Start with CLAUDE.md:
# Project conventions
- API routes live in `src/routes`.
- Integration tests live in `tests/integration`.
- Use `requireAuth()` on non-public routes.
- Validate request bodies with Zod schemas from `src/schemas`.
- Run `pnpm test:integration` before marking API work complete.Then add root-level REVIEW.md:
# Code Review Rules
Treat these as Important unless stated otherwise.
## API routes
If a PR adds or changes a file under `src/routes/**`:
- Flag missing integration test coverage in `tests/integration/**`.
- Flag routes without explicit auth, unless the route is listed as public.
- Flag request bodies that are not validated with a Zod schema.
Do not accept unit tests as a substitute for route-level integration tests.
## Evidence bar
For every Important finding, cite the changed file and the missing or conflicting evidence.
If the claim depends on a convention, cite this REVIEW.md rule.That last section matters. LLM reviewers can produce confident nonsense. Requiring evidence forces the review to tie a finding to a file, a line, or an explicit policy. It will not eliminate false positives, but it changes the shape of the review from “vibes” to “show me.”
Now a PR adds:
// src/routes/billing.ts
router.post("/billing/plan", async (req, res) => {
const result = await updatePlan(req.body.planId);
res.json(result);
});A good Claude Code Review comment should say something like:
- Important:
src/routes/billing.tsadds a new POST route without visible auth. - Important: request body reads
req.body.planIdwithout schema validation. - Important: no matching integration test was added under
tests/integration/**.
The human reviewer still decides. Maybe the router has auth middleware applied higher up. Maybe the integration test lives in a generated contract suite. Fine. The gate did its job if it forced that discussion before merge.
Triggering It Without Burning Money
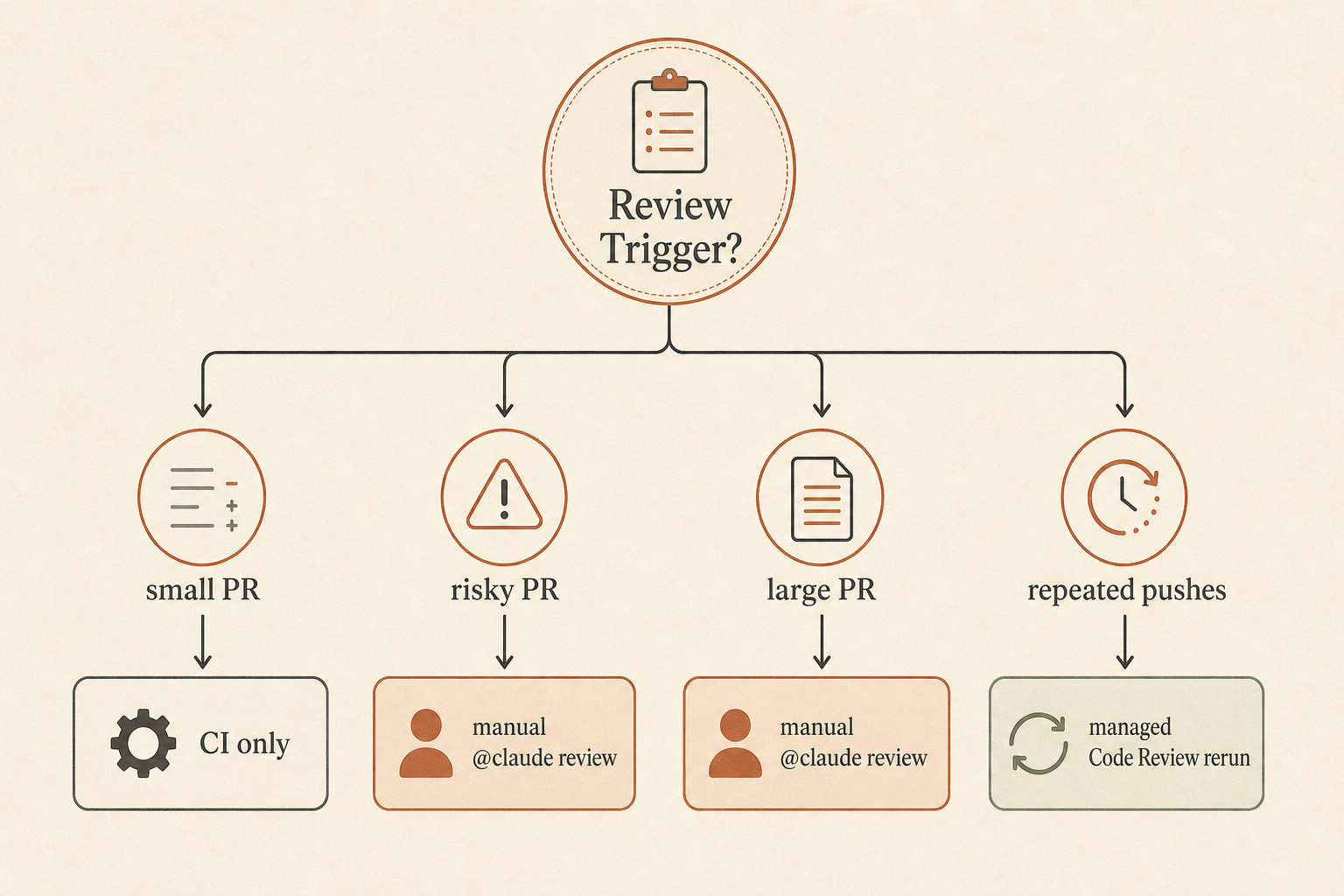
Anthropic gives three repository trigger modes: once after PR creation, after every push, or manual. Manual means no cost until someone comments @claude review; after that, additional pushes trigger reviews automatically for that PR (Claude Help Center).
For most teams, I would not start with “after every push.” Anthropic says Code Review averages about 20 minutes and generally costs $15 to $25 per review, scaling with PR size and complexity (Anthropic). That is cheap compared with a production incident. It is expensive compared with running ESLint.
Use a tiered gate:
- Every PR runs normal CI.
- Risky PRs get
@claude review. - Large PRs, auth changes, payments changes, migrations, and public API changes require Claude review before human approval.
- Repeat Claude review after major changes, not after every typo fix.
- Humans own the final approval.
A lightweight GitHub PR checklist makes the gate explicit:
## AI Review Gate
- [ ] CI is green.
- [ ] `@claude review` has run, or this PR is exempt.
- [ ] Important findings are fixed or explained.
- [ ] If this PR changes conventions, `CLAUDE.md` is updated.
- [ ] If this PR changes review policy, `REVIEW.md` is updated.If you prefer running Claude inside your own workflow, Anthropic’s GitHub Actions docs show anthropics/claude-code-action@v1 and a code-review plugin configuration, with the usual warning to use GitHub Secrets for API keys (Claude Code Docs). That route gives you more CI control. The managed Code Review route gives you the deeper multi-agent reviewer Anthropic describes.
Do not confuse them. One is programmable automation. The other is a paid, depth-first reviewer.
The Trick: Make Claude Review the Contract, Not the Style
Bad REVIEW.md files read like fortune cookies:
Please ensure the code is clean, maintainable, secure, and well tested.That will produce mush.
Good REVIEW.md files encode scars:
## Database migrations
Flag as Important if:
- A migration adds a non-null column without a default on an existing table.
- A migration backfills data without batching.
- Application code starts reading a new column before the migration is deployed.
Skip:
- Formatting comments in generated Prisma client files.This is where AI review becomes useful. It is not replacing your senior engineer’s taste. It is replaying the team’s institutional memory on every PR.
A few rules that work well:
## Re-review behavior
On the first review, report Important and Nit findings.
On later reviews of the same PR, suppress new Nits unless they are directly caused by the latest push.
## Test policy
Flag missing tests only when the changed behavior is observable through a stable public interface.
Do not request snapshot tests for purely visual copy changes.
## Security policy
Flag any new endpoint that:
- Accepts user input without validation.
- Performs authorization by trusting a user-provided account ID.
- Logs tokens, session IDs, API keys, or full request bodies.Notice what is absent: “make the code elegant.” Humans can argue elegance in review. Claude should check contracts.
What the Threads Are Missing
The HN and Reddit debates keep circling one question: should AI review AI code?
Wrong question.
The right question is: which parts of review are you willing to make explicit?
If your review culture lives in senior engineers’ heads, Claude Code Review will feel noisy and arbitrary. If your review culture is written down as repo rules, it becomes a multiplier. CLAUDE.md tells Claude how the project works. REVIEW.md tells Claude what your team refuses to merge.
This also answers the “documenting for Claude” complaint. Yes, developers are now writing docs for an agent. That sounds silly until you realize those docs are also onboarding material, review policy, and incident prevention. A good CLAUDE.md is a better “how this repo works” file for humans too.
The sharp edge is accountability. If Claude misses the bug, you still merged it. If Claude invents a bug, you still need to reject it. If Claude reviews its own output, you still need independent signals: tests, type systems, static analysis, observability, and a human who understands the change.
Use Claude Code Review as a gate, not a judge. Make it ask the annoying questions every time:
- Where is the integration test?
- Where is auth enforced?
- Did this PR make
CLAUDE.mdfalse? - Is this generated file worth commenting on?
- Is this finding backed by code, or just a hunch?
That is enough to pay for itself on the right PRs.
Try the same setup with Claude Fable 5 on OneHop, drop-in, and start with $10 free.
Further reading: Getting started with Claude Fable 5.

