Anthropic le puso un precio claro a la autonomía de frontera: Claude Fable 5 aparece a $10 por millón de tokens de entrada y $50 por millón de tokens de salida en la Claude API, mientras que Sonnet 4.6 cuesta $3/$15 y Opus 4.8 $5/$25 (Fable, Sonnet, Opus). Esa diferencia es toda la decisión de producto.
Si mandas cada prompt de programación a Fable, no estás siendo “frontier”. Te estás saltando la arquitectura.
A 16 de junio de 2026, también hay un matiz de disponibilidad: la página de Fable de Anthropic dice que Fable 5 no está disponible actualmente, y Anthropic afirma que suspendió el acceso el 12 de junio tras una directiva del gobierno de EE. UU. que cubre Fable 5 y Mythos 5 (comunicado de Anthropic). Eso no hace que la capa de enrutamiento sea menos útil. La hace más urgente. Tu app ya debería saber degradar de Fable a Opus o Sonnet sin despertar a un ingeniero.
Esta guía construye esa capa: Sonnet por defecto, Opus para trabajo de producción de alto riesgo, Fable solo para trabajos largos de agentes donde el valor de un resultado correcto supera la factura de tokens.

La regla de enrutamiento: Fable es un especialista, no el valor por defecto
Empieza con una tabla contundente.
| Modelo | ID de modelo de API | Precio entrada / salida | Úsalo para |
|---|---|---|---|
| Claude Sonnet 4.6 | claude-sonnet-4-6 | $3 / $15 por 1M de tokens | programación rutinaria, revisión, soporte, extracción, la mayoría de agentes |
| Claude Opus 4.8 | claude-opus-4-8 | $5 / $25 por 1M de tokens | código de nivel producción, revisiones complejas, pasos de agentes que requieren criterio |
| Claude Fable 5 | claude-fable-5 | $10 / $50 por 1M de tokens | trabajo largo de agentes, de alto valor y con beneficio real |
El propio posicionamiento de Anthropic encaja con esta división. Sonnet 4.6 se presenta como el modelo versátil de uso diario para programación, agentes y flujos de trabajo profesionales, con una ventana de contexto de 1M de tokens actualmente en beta de API (Anthropic Sonnet). Opus 4.8 está posicionado para programación seria, flujos de trabajo agénticos y tareas empresariales de alto riesgo (Anthropic Opus). Fable 5 se describe como un modelo de nivel Mythos para proyectos ambiciosos y de larga duración, y para agentes que pueden planificar por etapas, delegar y revisar su propio trabajo (Anthropic Fable).
Eso te da una política limpia:
- Usa Sonnet por defecto. La mayoría de prompts no merecen un modelo de salida a $50/M.
- Escala a Opus cuando fallar sea caro. Piensa en migraciones de esquemas, revisión de PR sensible a seguridad, análisis financiero y refactors de varios archivos.
- Usa Fable solo cuando la tarea sea grande, ambigua y valga una factura mayor. Ejecuciones de agentes de varios días, modernización de codebases, paquetes de investigación profunda y flujos de “lleva este proyecto hasta terminado”.
El debate de la comunidad gira sobre todo en torno a ese tercer grupo. El hilo de HN sobre la suspensión de Anthropic del 12 de junio acumuló más de mil comentarios según resúmenes indexados de HN, y la conversación se partió rápido entre seguridad, geopolítica y si alguien puede permitirse uso agéntico a estos precios (hilo de HN, referencia de resumen). Los hilos de Reddit fueron más directos: desarrolladores quejándose de sesiones de Claude Code devoradoras de tokens, límites de suscripción y de si $50/M de salida empuja Fable a territorio exclusivo de empresas (discusión en ClaudeCode, discusión en el subreddit de ChatGPT).
La respuesta práctica que falta en la mayoría de hilos: no discutas sobre un “mejor modelo” global. Enruta por valor esperado.
Paso 1: Usa OneHop como capa de acceso drop-in
Si quieres el camino más corto, usa OneHop como capa de proveedor y mantén el código de tu app neutral respecto al proveedor. La página de Fable de OneHop lista anthropic/claude-fable-5, muestra el precio oficial junto al precio de OneHop y dice que las cuentas nuevas reciben $10 gratis sin tarjeta (OneHop Fable 5). La página actual lista soporte de Anthropic Messages en https://api.onehop.ai/anthropic; úsalo para el Anthropic SDK.
Instala el SDK:
pip install anthropic
export ONEHOP_API_KEY="your_key_here"Llamada mínima:
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Plan a safe Rails 6 to Rails 8 migration."}],
)
print(message.content[0].text)Ese es el punto de integración. Tu capa de enrutamiento debería estar encima y decidir qué cadena de modelo enviar.
El valor de OneHop aquí es aburrido en el mejor sentido: una cuenta, una página de modelo clara y un cambio de base URL en lugar de reescribir tu aplicación. Si Fable está pausado o no disponible, el mismo router puede apuntar las tareas de gama alta a Opus y mantener vivo el producto.
Empieza aquí si solo quieres acceso y créditos: Claude Fable 5 en OneHop, luego empieza con $10 gratis.
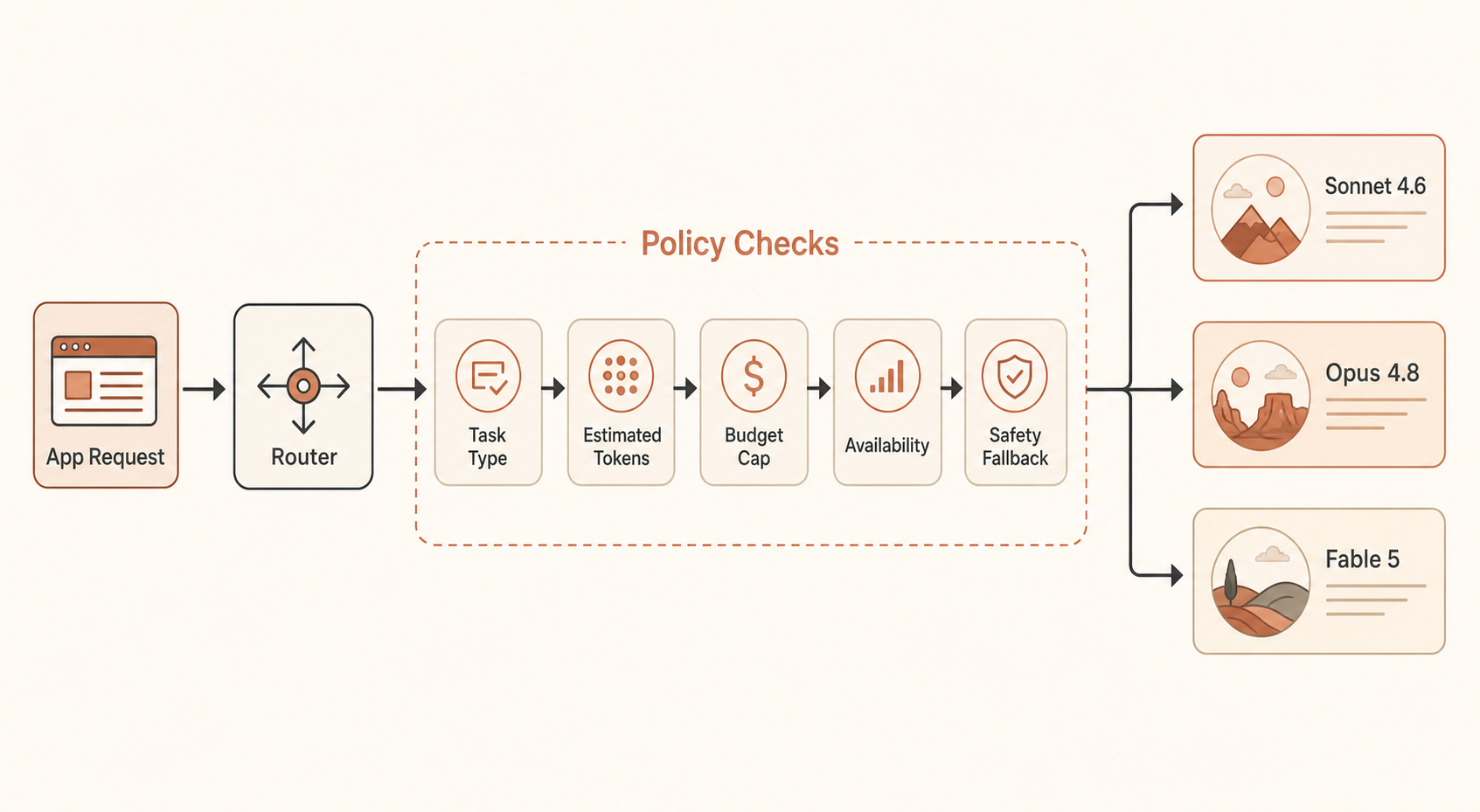
Paso 2: Crea un router consciente del presupuesto
Aquí tienes un router compacto en Python que puedes ejecutar. Estima el coste de la solicitud, aplica un límite por llamada, recurre a alternativas cuando Fable no está disponible y mantiene Sonnet como valor por defecto.
import os
from dataclasses import dataclass
from anthropic import Anthropic, APIError, RateLimitError
PRICES = {
"sonnet": {"model": "claude-sonnet-4-6", "in": 3.00, "out": 15.00},
"opus": {"model": "claude-opus-4-8", "in": 5.00, "out": 25.00},
"fable": {"model": "anthropic/claude-fable-5", "in": 10.00, "out": 50.00},
}
@dataclass
class Task:
kind: str
prompt: str
max_output_tokens: int = 2000
budget_usd: float = 0.25
high_value: bool = False
long_running: bool = False
production_risk: bool = False
def rough_tokens(text: str) -> int:
return max(1, len(text) // 4)
def estimate_cost_usd(model_key: str, input_tokens: int, output_tokens: int) -> float:
price = PRICES[model_key]
return (input_tokens / 1_000_000 * price["in"]) + (output_tokens / 1_000_000 * price["out"])
def choose_model(task: Task) -> str:
if task.high_value and task.long_running:
return "fable"
if task.production_risk or task.kind in {"migration", "security_review", "architecture"}:
return "opus"
return "sonnet"
def route_with_budget(task: Task) -> list[str]:
first = choose_model(task)
fallbacks = {
"fable": ["fable", "opus", "sonnet"],
"opus": ["opus", "sonnet"],
"sonnet": ["sonnet"],
}[first]
input_tokens = rough_tokens(task.prompt)
return [
key for key in fallbacks
if estimate_cost_usd(key, input_tokens, task.max_output_tokens) <= task.budget_usd
] or ["sonnet"]
def run(task: Task) -> str:
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/anthropic",
)
last_error = None
for key in route_with_budget(task):
try:
response = client.messages.create(
model=PRICES[key]["model"],
max_tokens=task.max_output_tokens,
messages=[{"role": "user", "content": task.prompt}],
)
return response.content[0].text
except (APIError, RateLimitError) as exc:
last_error = exc
continue
raise RuntimeError(f"All model routes failed: {last_error}")
if __name__ == "__main__":
task = Task(
kind="migration",
prompt="Create a step-by-step plan to migrate a 200k-line Django app from 3.2 to 5.x.",
max_output_tokens=3000,
budget_usd=0.20,
production_risk=True,
)
print(run(task))Lo importante no es el estimador de tokens. Es el límite de política. Necesitas un lugar en tu codebase donde el producto diga: “Esta tarea puede gastar más porque el resultado importa”.
Paso 3: Añade límites que encajen con el comportamiento real de los agentes
Los costes de los agentes son irregulares. Una finalización de chat es fácil de poner en precio. Un agente de programación puede inspeccionar archivos, llamar herramientas, reescribir, probar, reintentar y resumir. Un hilo de Reddit afirmó que una ejecución de Fable quemó millones de tokens en una hora; trátalo como anecdótico, pero el patrón es lo bastante real: los agentes de horizonte largo multiplican el uso de tokens mediante bucles (Reddit).
Añade tres límites:
- Límite por llamada: rechaza o baja de nivel si el coste estimado supera el presupuesto de la solicitud.
- Límite por tarea: detén el agente al alcanzar un límite en dólares, aunque las llamadas individuales sean válidas.
- Límite por usuario o workspace: evita que un equipo queme la cuenta compartida.
En producción, guarda el gasto en una tabla de base de datos indexada por workspace_id, task_id y model. No dependas solo de los paneles del proveedor. Sirven para conciliación de facturación, no para control de producto en vivo.
Usa también caché de prompts de forma agresiva. Anthropic dice que Fable mantiene el descuento existente del 90% en tokens de entrada para caché de prompts, y las páginas de Sonnet y Opus también listan hasta un 90% de ahorro con caché de prompts (Fable, Sonnet, Opus). Cachea las partes estables: mapa del repo, estándares de programación, docs de API, resúmenes de esquema y especificaciones largas de producto. No cachees instrucciones volátiles del usuario.
Una buena capa de enrutamiento debería registrar estos campos en cada llamada:
{
"task_kind": "migration",
"chosen_model": "opus",
"fallback_from": "fable",
"estimated_cost_usd": 0.18,
"budget_usd": 0.20,
"input_tokens": 12000,
"max_output_tokens": 3000
}Ese log es la forma de responder al CFO, al staff engineer y al usuario que pregunta por qué se detuvo el agente.
Paso 4: Trata el fallback como comportamiento de producto
Fable tiene dos tipos de fallback que debes planificar.
El primero es el fallback normal de infraestructura: modelo no disponible, límite de tasa, timeout, problema del proveedor. El estado actual de Fable demuestra que esto importa. Anthropic dice que el acceso a otros modelos no se vio afectado por la directiva del 12 de junio (Anthropic), así que una buena app debería seguir funcionando mediante Opus o Sonnet.
El segundo es el fallback de seguridad. Anthropic dice que Fable redirige algunas solicitudes marcadas de ciberseguridad y biología a Opus 4.8, y que a los usuarios no se les cobran precios de Fable por solicitudes redirigidas (Anthropic Fable). El post de lanzamiento dice que esas salvaguardas se activan en menos del 5% de las sesiones de media, con algunos falsos positivos esperados (lanzamiento de Anthropic).
No se lo ocultes a los usuarios. Si tu producto de revisión de seguridad pide Fable y recibe comportamiento de Opus, la UI debería decir algo como:
“Esta solicitud usó la ruta de fallback más segura para la parte marcada. Los resultados pueden ser menos exhaustivos. El impacto en el presupuesto se ajustó.”
Eso es mejor que fingir que todas las respuestas vinieron del mismo modelo. También protege tus evaluaciones. Si haces benchmark de Fable pero la mitad de tu conjunto de pruebas activa fallback, estás midiendo tu ruta de clasificador tanto como el modelo.

Qué enviar esta semana
Envía el router antes de enviar el feature flag de Fable.
Para la mayoría de productos para desarrolladores, mis valores por defecto recomendados son simples:
- Explicación de código, arreglos pequeños, tests, docs: Sonnet 4.6.
- Revisión de PR, bugs de producción, decisiones de arquitectura: Opus 4.8.
- Trabajo de agente de varias horas o varios días con retorno de negocio claro: Fable 5 cuando esté disponible, con fallback a Opus.
- Cualquier cosa sin límites: nada de Fable hasta que el usuario defina un presupuesto.
- Cualquier cosa repetida entre muchos usuarios: cachea el contexto largo o procésalo por lotes.
El objetivo no es venerar el modelo superior. El objetivo es gastar tokens de frontera donde cambian el resultado.
Puede que Fable 5 sea el modelo sobre el que la gente discute en HN esta semana. Sonnet sigue siendo donde debería empezar la mayor parte del tráfico de producción. Opus es el punto medio fiable. La implementación ganadora es un router aburrido con límites duros, fallback honesto y logs lo bastante buenos para depurar tanto calidad como coste.
Si quieres la ruta más rápida para probar la configuración, abre Claude Fable 5 en OneHop, crea una cuenta y empieza con $10 gratis. Luego conecta el router anterior a un solo flujo de trabajo, no a todo tu producto. Mide el coste por resultado aceptado. Ese número importa más que cualquier benchmark de semana de lanzamiento.

