Anthropic hat Frontier-Autonomie mit einem klaren Preisschild versehen: Claude Fable 5 steht auf der Claude API bei $10 pro Million Input-Tokens und $50 pro Million Output-Tokens, während Sonnet 4.6 bei $3/$15 und Opus 4.8 bei $5/$25 liegt (Fable, Sonnet, Opus). Genau diese Spanne ist die ganze Produktentscheidung.
Wenn du jeden Coding-Prompt an Fable schickst, bist du nicht „frontier“. Du überspringst Architektur.
Stand 16. Juni 2026 gibt es außerdem einen Verfügbarkeitsknick: Auf Anthropic’s Fable-Seite steht, dass Fable 5 derzeit nicht verfügbar ist, und Anthropic sagt, der Zugriff sei am 12. Juni nach einer Anordnung der US-Regierung ausgesetzt worden, die Fable 5 und Mythos 5 betrifft (Anthropic statement). Das macht die Routing-Schicht nicht weniger nützlich. Es macht sie dringender. Deine App sollte längst wissen, wie sie von Fable auf Opus oder Sonnet degradiert, ohne einen Engineer aus dem Bett zu klingeln.
Dieser Guide baut genau diese Schicht: Sonnet als Standard, Opus für produktionskritische Arbeit mit hoher Fallhöhe, Fable nur für lange Agenten-Jobs, bei denen der Wert eines richtigen Ergebnisses die Token-Rechnung schlägt.

Die Routing-Regel: Fable ist ein Spezialist, kein Standard
Fang mit einer stumpfen Tabelle an.
| Modell | API-Modell-ID | Input-/Output-Preis | Wofür nutzen |
|---|---|---|---|
| Claude Sonnet 4.6 | claude-sonnet-4-6 | $3 / $15 pro 1M Tokens | Routine-Coding, Review, Support, Extraktion, die meisten Agenten |
| Claude Opus 4.8 | claude-opus-4-8 | $5 / $25 pro 1M Tokens | produktionsreifer Code, komplexe Reviews, Agenten-Schritte, die Urteilskraft brauchen |
| Claude Fable 5 | claude-fable-5 | $10 / $50 pro 1M Tokens | lange, hochwertige Agenten-Arbeit mit echtem Upside |
Anthropic’s eigene Positionierung passt zu dieser Aufteilung. Sonnet 4.6 wird als vielseitiges Alltagsmodell für Coding, Agenten und professionelle Workflows verkauft, mit einem 1M-Token-Kontextfenster, das derzeit in der API-Beta ist (Anthropic Sonnet). Opus 4.8 ist für ernsthaftes Coding, agentische Workflows und Enterprise-Aufgaben mit hoher Fallhöhe positioniert (Anthropic Opus). Fable 5 wird als Mythos-Level-Modell für ambitionierte, langfristige Projekte und Agenten beschrieben, die über mehrere Phasen planen, delegieren und ihre eigene Arbeit prüfen können (Anthropic Fable).
Daraus ergibt sich eine saubere Policy:
- Standardmäßig Sonnet. Die meisten Prompts verdienen kein $50/M-Output-Modell.
- Auf Opus eskalieren, wenn Fehler teuer sind. Denk an Schema-Migrationen, sicherheitssensitive PR-Reviews, Finanzanalysen und Multi-File-Refactorings.
- Fable nur nutzen, wenn die Aufgabe groß, vage und eine höhere Rechnung wert ist. Mehrtägige Agenten-Läufe, Codebase-Modernisierung, tiefe Research-Pakete und „bring dieses Projekt fertig“-Workflows.
Die Community-Debatte dreht sich vor allem um diesen dritten Eimer. Der HN-Thread zu Anthropic’s Aussetzung am 12. Juni zog laut indexierten HN-Zusammenfassungen mehr als tausend Kommentare an, und die Diskussion teilte sich schnell zwischen Safety, Geopolitik und der Frage, ob sich bei diesen Preisen überhaupt jemand agentische Nutzung leisten kann (HN thread, recap reference). Reddit-Threads waren direkter: Entwickler beschwerten sich über tokenhungrige Claude Code-Sessions, Abo-Kontingente und darüber, ob $50/M Output Fable in Enterprise-only-Gebiet drückt (ClaudeCode discussion, ChatGPT subreddit discussion).
Die praktische Antwort, die in den meisten Threads fehlt: Streite nicht über ein globales „bestes Modell“. Route nach erwartetem Wert.
Schritt 1: Nutze OneHop als Drop-in-Zugriffsschicht
Wenn du den kürzesten Weg willst, nutze OneHop als Provider-Schicht und halte deinen App-Code providerneutral. OneHop’s Fable-Seite listet anthropic/claude-fable-5, zeigt offizielle Preise neben OneHop-Preisen und sagt, dass neue Accounts $10 gratis bekommen, ohne Karte (OneHop Fable 5). Die aktuelle Seite listet Anthropic Messages-Support unter https://api.onehop.ai/anthropic; nutze das für das Anthropic SDK.
Installiere das SDK:
pip install anthropic
export ONEHOP_API_KEY="your_key_here"Minimaler Call:
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Plan a safe Rails 6 to Rails 8 migration."}],
)
print(message.content[0].text)Das ist der Integrationspunkt. Deine Routing-Schicht sollte darüber sitzen und entscheiden, welchen Modell-String sie sendet.
OneHop’s Wert ist hier im besten Sinne langweilig: ein Account, eine klare Modellseite und eine base URL-Änderung statt eines Umbaus deiner Anwendung. Wenn Fable pausiert oder nicht verfügbar ist, kann derselbe Router High-End-Aufgaben auf Opus schicken und das Produkt am Leben halten.
Starte hier, wenn du einfach Zugriff und Credits willst: Claude Fable 5 on OneHop, dann start with $10 free.
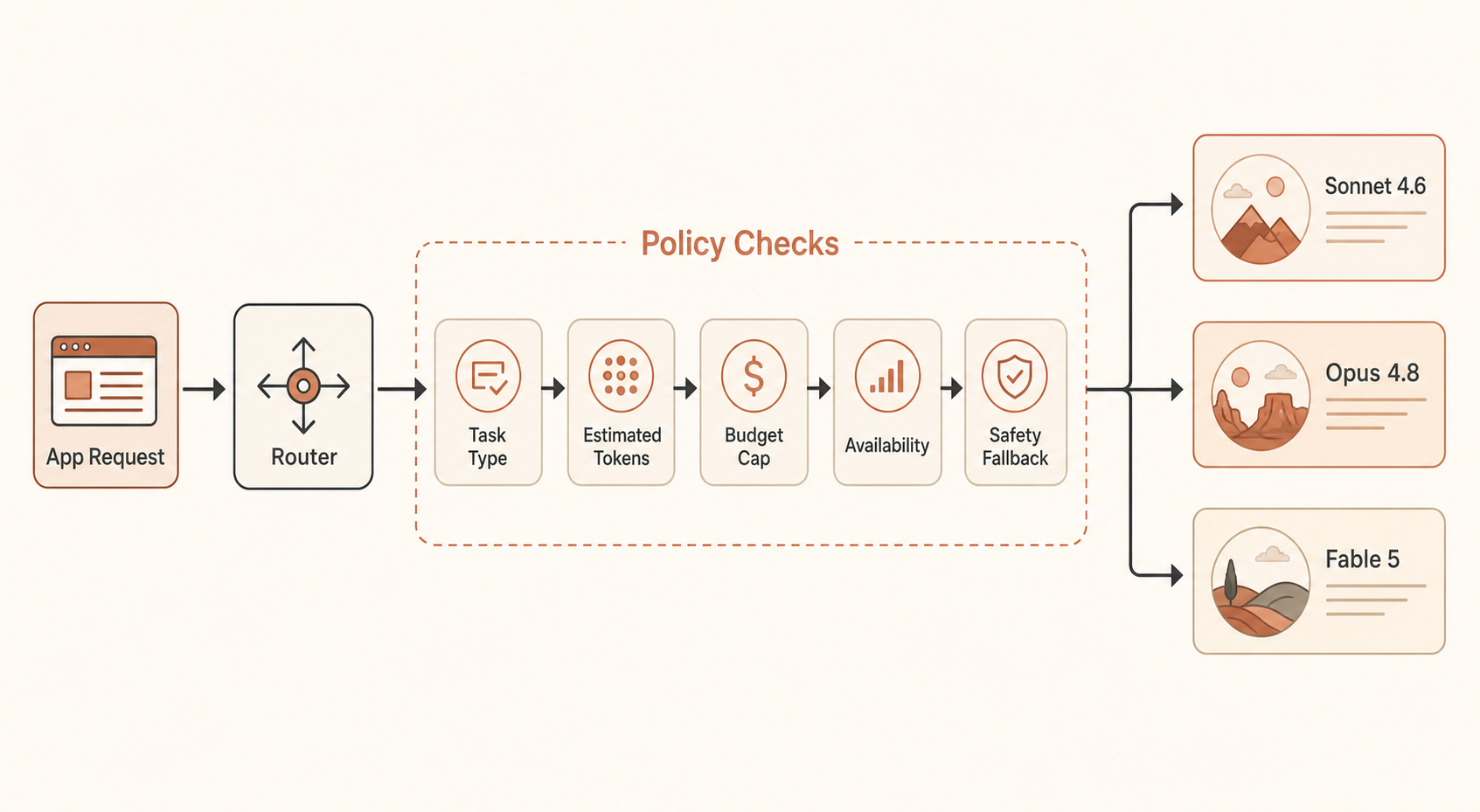
Schritt 2: Baue einen budgetbewussten Router
Hier ist ein kompakter Python-Router, den du ausführen kannst. Er schätzt Request-Kosten, setzt ein Limit pro Call durch, fällt zurück, wenn Fable nicht verfügbar ist, und hält Sonnet als Standard.
import os
from dataclasses import dataclass
from anthropic import Anthropic, APIError, RateLimitError
PRICES = {
"sonnet": {"model": "claude-sonnet-4-6", "in": 3.00, "out": 15.00},
"opus": {"model": "claude-opus-4-8", "in": 5.00, "out": 25.00},
"fable": {"model": "anthropic/claude-fable-5", "in": 10.00, "out": 50.00},
}
@dataclass
class Task:
kind: str
prompt: str
max_output_tokens: int = 2000
budget_usd: float = 0.25
high_value: bool = False
long_running: bool = False
production_risk: bool = False
def rough_tokens(text: str) -> int:
return max(1, len(text) // 4)
def estimate_cost_usd(model_key: str, input_tokens: int, output_tokens: int) -> float:
price = PRICES[model_key]
return (input_tokens / 1_000_000 * price["in"]) + (output_tokens / 1_000_000 * price["out"])
def choose_model(task: Task) -> str:
if task.high_value and task.long_running:
return "fable"
if task.production_risk or task.kind in {"migration", "security_review", "architecture"}:
return "opus"
return "sonnet"
def route_with_budget(task: Task) -> list[str]:
first = choose_model(task)
fallbacks = {
"fable": ["fable", "opus", "sonnet"],
"opus": ["opus", "sonnet"],
"sonnet": ["sonnet"],
}[first]
input_tokens = rough_tokens(task.prompt)
return [
key for key in fallbacks
if estimate_cost_usd(key, input_tokens, task.max_output_tokens) <= task.budget_usd
] or ["sonnet"]
def run(task: Task) -> str:
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/anthropic",
)
last_error = None
for key in route_with_budget(task):
try:
response = client.messages.create(
model=PRICES[key]["model"],
max_tokens=task.max_output_tokens,
messages=[{"role": "user", "content": task.prompt}],
)
return response.content[0].text
except (APIError, RateLimitError) as exc:
last_error = exc
continue
raise RuntimeError(f"All model routes failed: {last_error}")
if __name__ == "__main__":
task = Task(
kind="migration",
prompt="Create a step-by-step plan to migrate a 200k-line Django app from 3.2 to 5.x.",
max_output_tokens=3000,
budget_usd=0.20,
production_risk=True,
)
print(run(task))Der wichtige Teil ist nicht der Token-Schätzer. Es ist die Policy-Grenze. Du brauchst eine Stelle in deiner Codebase, an der das Produkt sagt: „Diese Aufgabe darf mehr kosten, weil das Ergebnis zählt.“
Schritt 3: Setze Caps, die zu echtem Agenten-Verhalten passen
Agenten-Kosten sind sprunghaft. Eine Chat Completion lässt sich leicht bepreisen. Ein Coding-Agent kann Dateien inspizieren, Tools aufrufen, umschreiben, testen, erneut versuchen und zusammenfassen. Ein Reddit-Thread behauptete, ein Fable-Lauf habe in einer Stunde Millionen Tokens verbrannt; behandle das als Anekdote, aber das Muster ist real genug: Long-Horizon-Agenten vervielfachen Token-Nutzung durch Schleifen (Reddit).
Füge drei Caps hinzu:
- Pro-Call-Cap: ablehnen oder herunterschalten, wenn die geschätzten Kosten das Request-Budget überschreiten.
- Pro-Task-Cap: den Agenten nach einem Dollar-Limit stoppen, selbst wenn einzelne Calls gültig sind.
- Pro-User- oder Pro-Workspace-Cap: verhindern, dass ein Team den gemeinsamen Account verbrennt.
Für Produktion speicherst du Spend in einer Datenbanktabelle, keyed by workspace_id, task_id und model. Verlass dich nicht nur auf Vendor-Dashboards. Die sind für Billing-Abgleich da, nicht für Live-Produktkontrolle.
Nutze außerdem Prompt Caching aggressiv. Anthropic sagt, Fable behält den bestehenden 90%-Input-Token-Rabatt für Prompt Caching, und die Sonnet- und Opus-Seiten listen ebenfalls bis zu 90% Ersparnis mit Prompt Caching (Fable, Sonnet, Opus). Cache die stabilen Teile: Repo-Map, Coding-Standards, API-Dokumentation, Schema-Zusammenfassungen und lange Produktspezifikationen. Cache keine volatilen Nutzeranweisungen.
Eine gute Routing-Schicht sollte diese Felder für jeden Call loggen:
{
"task_kind": "migration",
"chosen_model": "opus",
"fallback_from": "fable",
"estimated_cost_usd": 0.18,
"budget_usd": 0.20,
"input_tokens": 12000,
"max_output_tokens": 3000
}Dieses Log ist die Antwort für den CFO, die Staff Engineer und den Nutzer, der fragt, warum der Agent gestoppt hat.
Schritt 4: Behandle Fallback als Produktverhalten
Für Fable musst du zwei Arten von Fallback planen.
Der erste ist normaler Infrastruktur-Fallback: nicht verfügbares Modell, Rate Limit, Timeout, Provider-Problem. Fable’s heutiger Status beweist, dass das zählt. Anthropic sagt, der Zugriff auf andere Modelle sei von der Anordnung vom 12. Juni nicht betroffen gewesen (Anthropic), also sollte eine gute App über Opus oder Sonnet weiterlaufen.
Der zweite ist Safety-Fallback. Anthropic sagt, Fable routet einige markierte Cybersecurity- und Biologie-Requests zu Opus 4.8, und Nutzer zahlen für umgeroutete Requests keine Fable-Preise (Anthropic Fable). Der Launch-Post sagt, diese Safeguards greifen im Schnitt in weniger als 5% der Sessions, mit einigen erwartbaren False Positives (Anthropic launch).
Versteck das nicht vor Nutzern. Wenn dein Security-Review-Produkt Fable anfragt und Opus-Verhalten bekommt, sollte die UI etwa sagen:
„Diese Anfrage nutzte für den markierten Teil die sicherere Fallback-Route. Ergebnisse können weniger umfassend sein. Die Budget-Auswirkung wurde angepasst.“
Das ist besser, als so zu tun, als käme jede Antwort vom selben Modell. Es schützt auch deine Evals. Wenn du Fable benchmarkst, aber die Hälfte deines Testsets Fallback triggert, misst du deinen Classifier-Pfad genauso sehr wie das Modell.

Was du diese Woche shippen solltest
Shippe den Router, bevor du das Fable-Feature-Flag shippst.
Für die meisten Developer-Produkte sind meine empfohlenen Defaults simpel:
- Code-Erklärung, kleine Fixes, Tests, Docs: Sonnet 4.6.
- PR-Review, Produktionsbugs, Architekturentscheidungen: Opus 4.8.
- Mehrstündige oder mehrtägige Agenten-Arbeit mit klarem Business-Payoff: Fable 5, wenn verfügbar, mit Opus-Fallback.
- Alles Unbegrenzte: kein Fable, bis der Nutzer ein Budget setzt.
- Alles, was über viele Nutzer hinweg wiederholt wird: langen Kontext cachen oder batchen.
Der Punkt ist nicht, das Top-Modell anzubeten. Der Punkt ist, Frontier-Tokens dort auszugeben, wo sie das Ergebnis verändern.
Fable 5 mag das Modell sein, über das diese Woche auf HN gestritten wird. Sonnet bleibt der Ort, an dem der meiste Produktions-Traffic starten sollte. Opus ist die verlässliche Mitte. Die Gewinner-Implementierung ist ein langweiliger Router mit harten Caps, ehrlichem Fallback und Logs, die gut genug sind, um sowohl Qualität als auch Kosten zu debuggen.
Wenn du den schnellsten Weg willst, das Setup zu testen, öffne Claude Fable 5 on OneHop, erstelle einen Account und start with $10 free. Dann verdrahte den Router oben in einen Workflow, nicht in dein ganzes Produkt. Miss die Kosten pro akzeptiertem Ergebnis. Diese Zahl ist wichtiger als jeder Launch-Week-Benchmark.

