Anthropic put a hard price tag on frontier autonomy: Claude Fable 5 is listed at $10 per million input tokens and $50 per million output tokens on the Claude API, while Sonnet 4.6 is $3/$15 and Opus 4.8 is $5/$25 (Fable, Sonnet, Opus). That spread is the whole product decision.
If you send every coding prompt to Fable, you are not being “frontier.” You are skipping architecture.
As of June 16, 2026, there is also an availability wrinkle: Anthropic’s Fable page says Fable 5 is currently unavailable, and Anthropic says it suspended access on June 12 after a U.S. government directive covering Fable 5 and Mythos 5 (Anthropic statement). That does not make the routing layer less useful. It makes it more urgent. Your app should already know how to degrade from Fable to Opus or Sonnet without waking up an engineer.
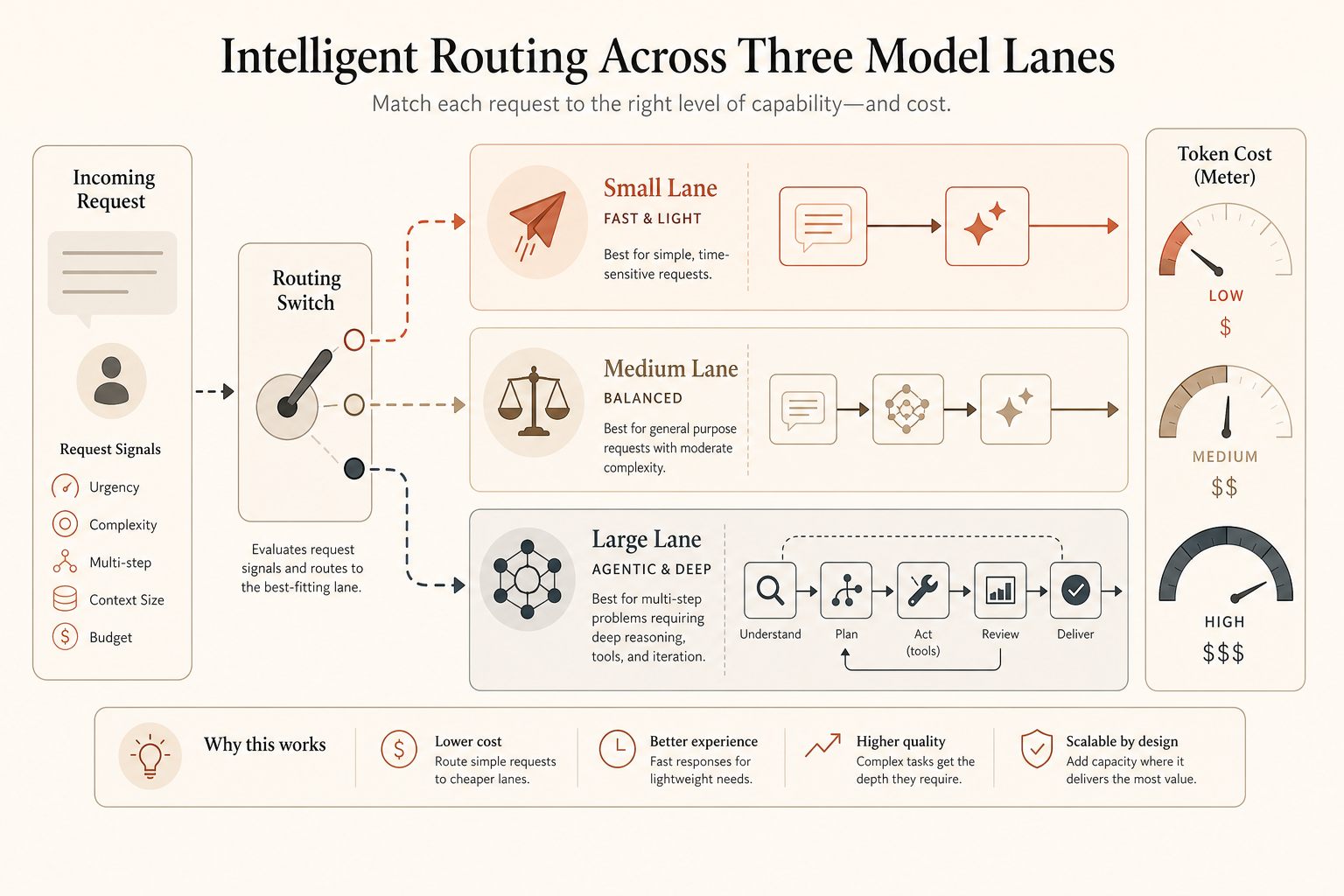
This guide builds that layer: Sonnet by default, Opus for high-stakes production work, Fable only for long-running agent jobs where the value of a correct result beats the token bill.

The Routing Rule: Fable Is a Specialist, Not a Default
Start with a blunt table.
| Model | API model ID | Input / output price | Use it for |
|---|---|---|---|
| Claude Sonnet 4.6 | claude-sonnet-4-6 | $3 / $15 per 1M tokens | routine coding, review, support, extraction, most agents |
| Claude Opus 4.8 | claude-opus-4-8 | $5 / $25 per 1M tokens | production-grade code, complex reviews, agent steps that need judgment |
| Claude Fable 5 | claude-fable-5 | $10 / $50 per 1M tokens | long-running, high-value agent work with real upside |
Anthropic’s own positioning lines up with this split. Sonnet 4.6 is pitched as the versatile daily model for coding, agents, and professional workflows, with a 1M-token context window currently in API beta (Anthropic Sonnet). Opus 4.8 is positioned for serious coding, agentic workflows, and high-stakes enterprise tasks (Anthropic Opus). Fable 5 is described as a Mythos-level model for ambitious, long-running projects and agents that can plan across stages, delegate, and check their own work (Anthropic Fable).
That gives you a clean policy:
- Default to Sonnet. Most prompts do not deserve a $50/M output model.
- Escalate to Opus when failure is expensive. Think schema migrations, security-sensitive PR review, financial analysis, and multi-file refactors.
- Use Fable only when the task is large, ambiguous, and worth a bigger bill. Multi-day agent runs, codebase modernization, deep research packs, and “take this project to done” workflows.
The community debate is mostly about that third bucket. The HN thread on Anthropic’s June 12 suspension drew more than a thousand comments according to indexed HN recaps, and the discussion quickly split between safety, geopolitics, and whether anyone can afford agentic usage at these prices (HN thread, recap reference). Reddit threads were more direct: developers complained about token-hungry Claude Code sessions, subscription allowances, and whether $50/M output pushes Fable into enterprise-only territory (ClaudeCode discussion, ChatGPT subreddit discussion).
The practical answer missing from most threads: do not argue about one global “best model.” Route by expected value.
Step 1: Use OneHop as the Drop-In Access Layer
If you want the shortest path, use OneHop as the provider layer and keep your app code provider-neutral. OneHop’s Fable page lists anthropic/claude-fable-5, shows official pricing beside OneHop pricing, and says new accounts get $10 free with no card required (OneHop Fable 5). The current page lists Anthropic Messages support at https://api.onehop.ai/anthropic; use that for the Anthropic SDK.
Install the SDK:
pip install anthropic
export ONEHOP_API_KEY="your_key_here"Minimal call:
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Plan a safe Rails 6 to Rails 8 migration."}],
)
print(message.content[0].text)That is the integration point. Your routing layer should sit above it and decide which model string to send.
OneHop’s value here is boring in the best way: one account, a clear model page, and a base URL change instead of rewriting your application. If Fable is paused or unavailable, the same router can point high-end tasks at Opus and keep the product alive.
Start here if you just want access and credits: Claude Fable 5 on OneHop, then start with $10 free.
Step 2: Build a Budget-Aware Router
Here is a compact Python router you can run. It estimates request cost, applies a per-call cap, falls back when Fable is unavailable, and keeps Sonnet as the default.
import os
from dataclasses import dataclass
from anthropic import Anthropic, APIError, RateLimitError
PRICES = {
"sonnet": {"model": "claude-sonnet-4-6", "in": 3.00, "out": 15.00},
"opus": {"model": "claude-opus-4-8", "in": 5.00, "out": 25.00},
"fable": {"model": "anthropic/claude-fable-5", "in": 10.00, "out": 50.00},
}
@dataclass
class Task:
kind: str
prompt: str
max_output_tokens: int = 2000
budget_usd: float = 0.25
high_value: bool = False
long_running: bool = False
production_risk: bool = False
def rough_tokens(text: str) -> int:
return max(1, len(text) // 4)
def estimate_cost_usd(model_key: str, input_tokens: int, output_tokens: int) -> float:
price = PRICES[model_key]
return (input_tokens / 1_000_000 * price["in"]) + (output_tokens / 1_000_000 * price["out"])
def choose_model(task: Task) -> str:
if task.high_value and task.long_running:
return "fable"
if task.production_risk or task.kind in {"migration", "security_review", "architecture"}:
return "opus"
return "sonnet"
def route_with_budget(task: Task) -> list[str]:
first = choose_model(task)
fallbacks = {
"fable": ["fable", "opus", "sonnet"],
"opus": ["opus", "sonnet"],
"sonnet": ["sonnet"],
}[first]
input_tokens = rough_tokens(task.prompt)
return [
key for key in fallbacks
if estimate_cost_usd(key, input_tokens, task.max_output_tokens) <= task.budget_usd
] or ["sonnet"]
def run(task: Task) -> str:
client = Anthropic(
api_key=os.environ["ONEHOP_API_KEY"],
base_url="https://api.onehop.ai/anthropic",
)
last_error = None
for key in route_with_budget(task):
try:
response = client.messages.create(
model=PRICES[key]["model"],
max_tokens=task.max_output_tokens,
messages=[{"role": "user", "content": task.prompt}],
)
return response.content[0].text
except (APIError, RateLimitError) as exc:
last_error = exc
continue
raise RuntimeError(f"All model routes failed: {last_error}")
if __name__ == "__main__":
task = Task(
kind="migration",
prompt="Create a step-by-step plan to migrate a 200k-line Django app from 3.2 to 5.x.",
max_output_tokens=3000,
budget_usd=0.20,
production_risk=True,
)
print(run(task))The important bit is not the token estimator. It is the policy boundary. You need a place in your codebase where the product says: “This task is allowed to spend more because the result matters.”
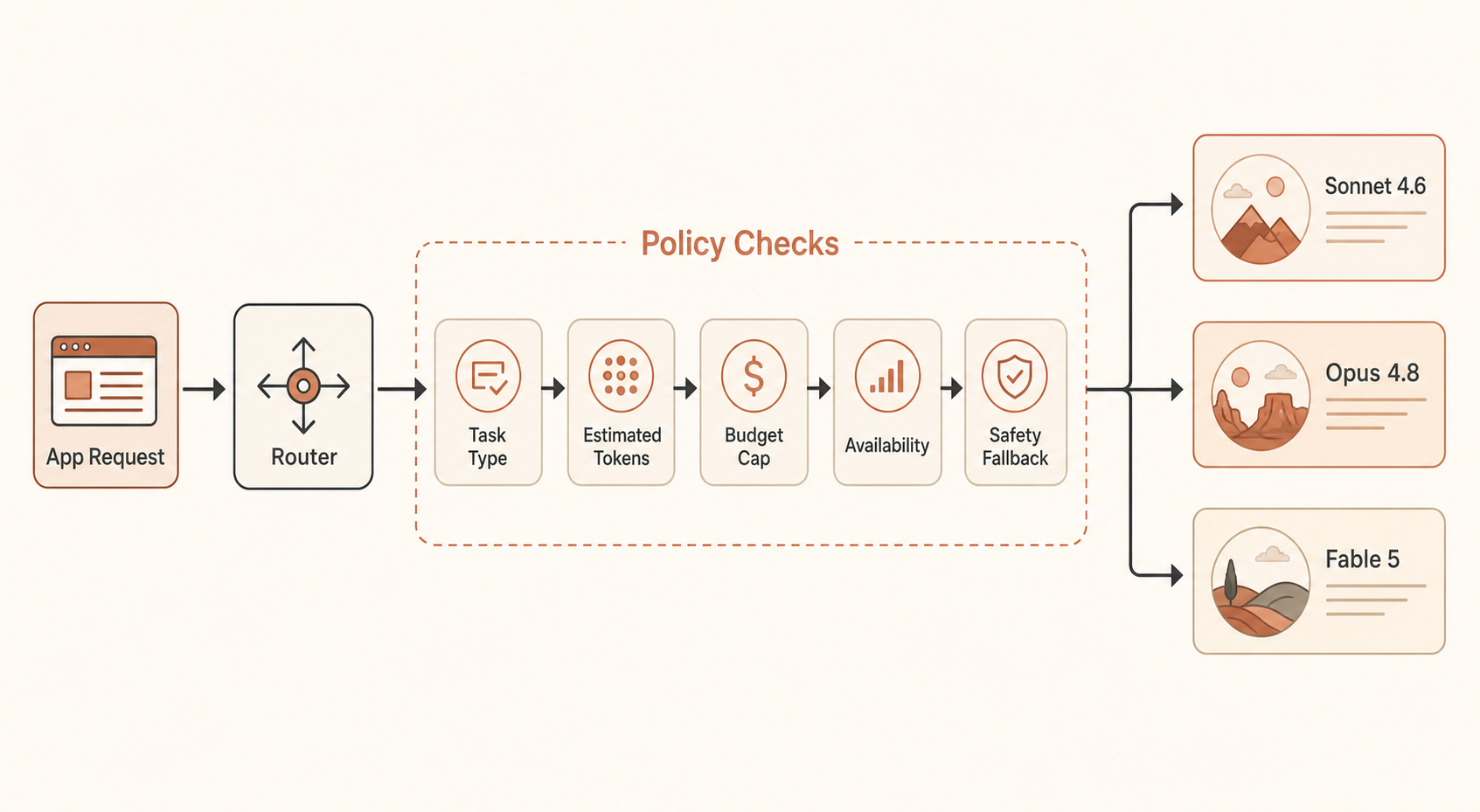
Step 3: Add Caps That Match Real Agent Behavior
Agent costs are spiky. A chat completion is easy to price. A coding agent can inspect files, call tools, rewrite, test, retry, and summarize. One Reddit thread claimed a Fable run burned millions of tokens in an hour; treat that as anecdotal, but the pattern is real enough: long-horizon agents multiply token usage through loops (Reddit).
Add three caps:
- Per-call cap: refuse or downshift if estimated cost exceeds the request budget.
- Per-task cap: stop the agent after a dollar limit, even if individual calls are valid.
- Per-user or per-workspace cap: prevent one team from burning the shared account.
For production, store spend in a database table keyed by workspace_id, task_id, and model. Do not rely only on vendor dashboards. They are for billing reconciliation, not live product control.
Also use prompt caching aggressively. Anthropic says Fable keeps the existing 90% input-token discount for prompt caching, and Sonnet and Opus pages list up to 90% savings with prompt caching as well (Fable, Sonnet, Opus). Cache the stable parts: repo map, coding standards, API docs, schema summaries, and long product specs. Do not cache volatile user instructions.
A good routing layer should log these fields for every call:
{
"task_kind": "migration",
"chosen_model": "opus",
"fallback_from": "fable",
"estimated_cost_usd": 0.18,
"budget_usd": 0.20,
"input_tokens": 12000,
"max_output_tokens": 3000
}That log is how you answer the CFO, the staff engineer, and the user who asks why the agent stopped.
Step 4: Treat Fallback as Product Behavior
Fable has two kinds of fallback to plan for.
The first is normal infrastructure fallback: unavailable model, rate limit, timeout, provider issue. Today’s Fable status proves this matters. Anthropic says access to other models was not affected by the June 12 directive (Anthropic), so a good app should keep working through Opus or Sonnet.
The second is safety fallback. Anthropic says Fable routes some flagged cybersecurity and biology requests to Opus 4.8, and that users are not charged Fable prices for rerouted requests (Anthropic Fable). The launch post says those safeguards trigger in less than 5% of sessions on average, with some false positives expected (Anthropic launch).
Do not hide this from users. If your security-review product asks for Fable and gets Opus behavior, the UI should say something like:
“This request used the safer fallback route for the flagged portion. Results may be less exhaustive. Budget impact was adjusted.”
That beats pretending every answer came from the same model. It also protects your evals. If you benchmark Fable but half your test set triggers fallback, you are measuring your classifier path as much as the model.

What to Ship This Week
Ship the router before you ship the Fable feature flag.
For most developer products, my recommended defaults are simple:
- Code explanation, small fixes, tests, docs: Sonnet 4.6.
- PR review, production bugs, architecture choices: Opus 4.8.
- Multi-hour or multi-day agent work with a clear business payoff: Fable 5 when available, with Opus fallback.
- Anything unbounded: no Fable until the user sets a budget.
- Anything repeated across many users: cache the long context or batch it.
The point is not to worship the top model. The point is to spend frontier tokens where they change the outcome.
Fable 5 may be the model people argue about on HN this week. Sonnet is still where most production traffic should start. Opus is the reliable middle. The winning implementation is a boring router with hard caps, honest fallback, and logs good enough to debug both quality and cost.
If you want the fastest path to test the setup, open Claude Fable 5 on OneHop, create an account, and start with $10 free. Then wire the router above into one workflow, not your whole product. Measure the cost per accepted result. That number matters more than any launch-week benchmark.

