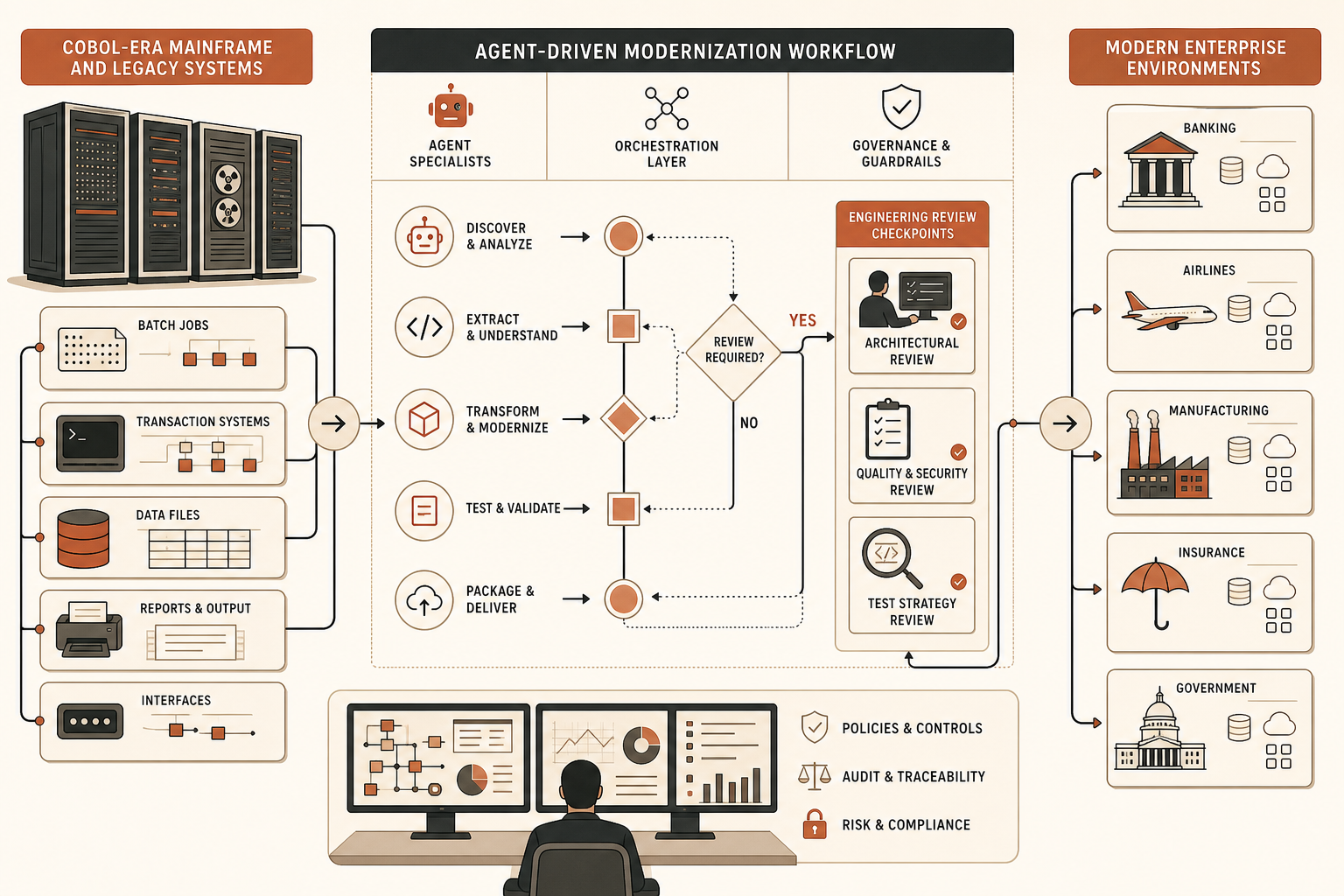
On June 11, 2026, Anthropic announced a multi-year alliance with DXC Technology that puts Claude into the kind of systems where “move fast” usually means “write a rollback plan first.” DXC says Claude is already the default foundation model for DXC OASIS agentic workflows, that Claude helped accelerate OASIS software delivery by an estimated 10x, and that more than 95% of OASIS code was generated by Claude before engineer review (Anthropic, PRNewswire).
That is the interesting part. Not “AI writes code.” Everyone has seen that demo. The real story is that DXC is taking agentic code generation into banks, airlines, insurers, manufacturers, and government agencies, where the hard problems are dependency archaeology, release governance, auditability, security, and not breaking a 30-year-old batch process that clears real money at 2 a.m.
The Signal: AI Enters the Managed-Services Layer
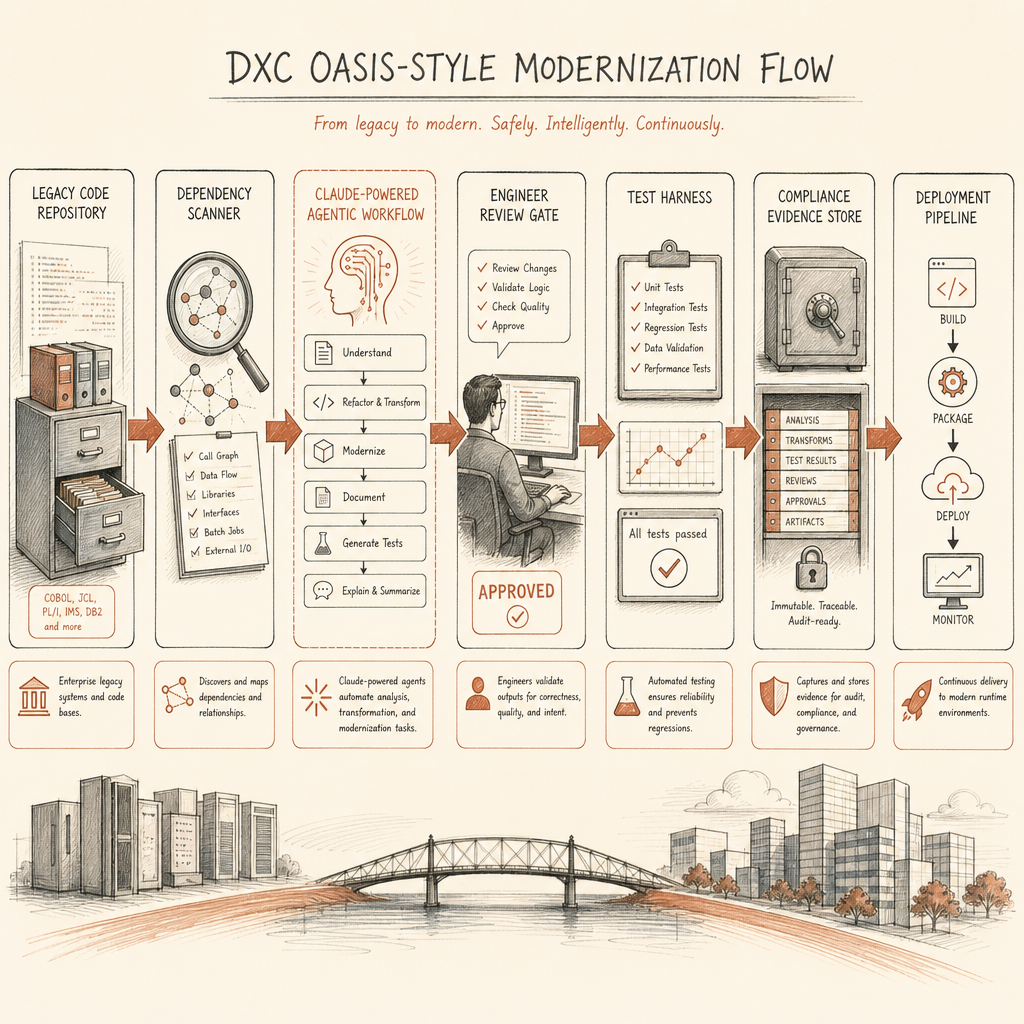
DXC launched OASIS on April 28, 2026 as an intelligent orchestration platform for managed services. Its stated job is to sit as a governed, secure layer across an organization’s existing IT estate, shifting operations from reactive support to real-time execution (DXC).
That matters because modernization in regulated industries rarely starts with a clean repo and a greenfield target. It starts with:
- batch jobs nobody fully owns
- application servers past normal support windows
- COBOL, Java EE, PL/SQL, shell, and vendor workflow glue
- compliance controls that are partly in code and partly in runbooks
- brittle integrations to payments, claims, booking, inventory, identity, or case-management systems
Putting Claude into OASIS means DXC is not treating the model as a chatbot beside the work. It is placing the model inside orchestration workflows that already know about incidents, change windows, ticket context, runbooks, environments, and customer constraints. That is the difference between “generate a refactor” and “generate a refactor that can survive CAB review.”
Anthropic says DXC will train tens of thousands of Claude-certified forward-deployed engineers through Anthropic Academy, with DXC adding its own curriculum for mission-critical systems (Anthropic). That is the right shape. Regulated modernization needs people who can read the system, not prompt tourists.
What Developers Should Copy
The DXC pattern is useful even if you do not work at DXC scale. The lesson is not “let the model own the repo.” The lesson is: wrap model work in a workflow where context, constraints, review, and evidence are first-class objects.
A practical legacy modernization agent should not start with “rewrite this service in Go.” It should start with a constrained plan:
1. Inventory modules, entry points, data stores, and external contracts.
2. Identify dead code and risk hotspots.
3. Propose the smallest behavior-preserving refactor.
4. Generate tests around current behavior before changing code.
5. Open a reviewable patch with traceable rationale.
6. Attach evidence: tests, static analysis, dependency impact, rollback notes.That sounds boring. Good. Boring is how regulated systems get changed.
DXC’s public numbers are aggressive: estimated 10x faster software delivery and more than 95% Claude-generated code for OASIS, reviewed by engineers (Anthropic). Treat those as deployment-specific claims, not a universal productivity constant. The point for developers is the operating model: high model contribution, mandatory human review, and a platform that records the work.
For a bank core migration, that could mean agents map transaction flows and generate characterization tests. For an airline, agents might untangle reservation or maintenance workflows while preserving external message formats. For an insurer, they can compare policy-admin rules against claims behavior. For manufacturers, they can trace ERP, MES, and supply-chain dependencies before touching code.
The Model Choice Is Becoming an Architecture Decision
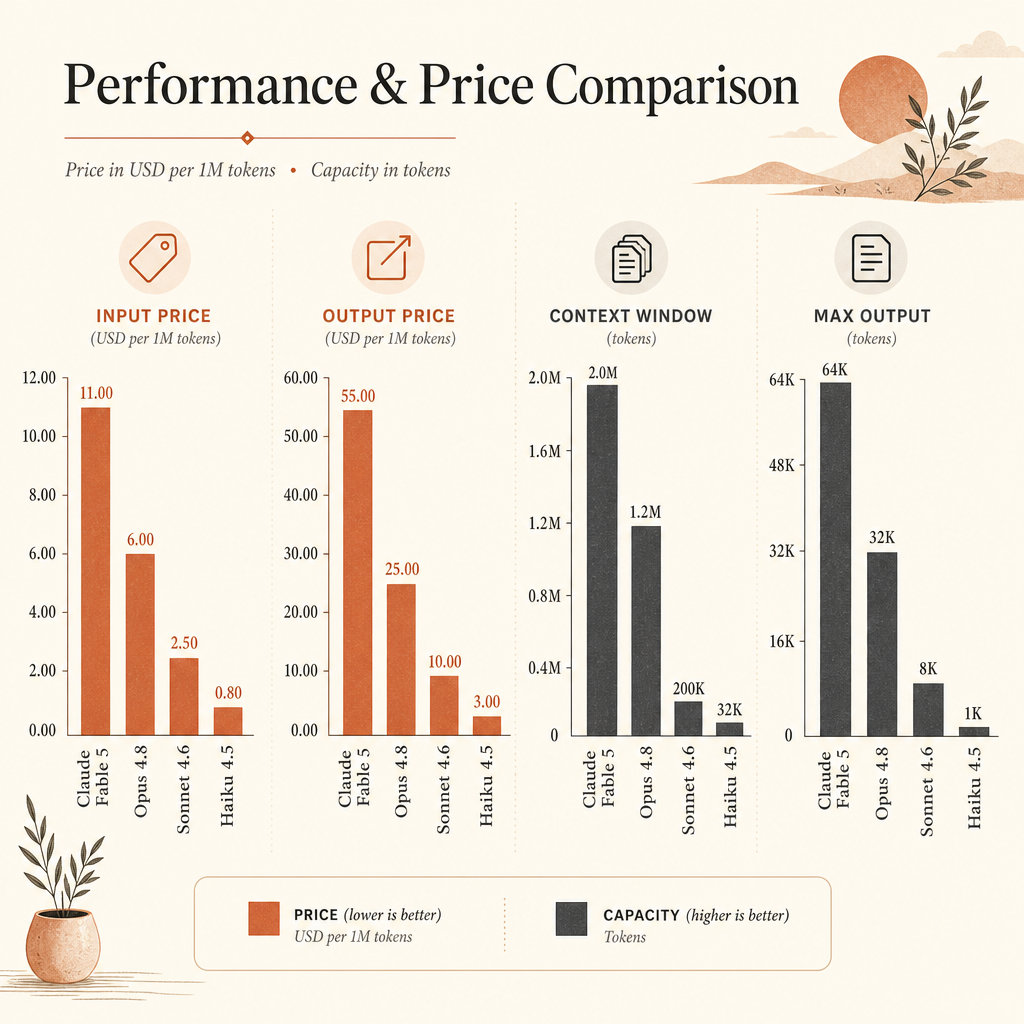
Two days before the DXC announcement, Anthropic launched Claude Fable 5 and Claude Mythos 5 on June 9, 2026. Fable 5 is Anthropic’s generally available Mythos-class model, while Mythos 5 is restricted through Project Glasswing and trusted access programs. Anthropic lists Fable 5 at $10 per million input tokens and $50 per million output tokens, with a 1M-token context window and 128k max output in the current API docs (Anthropic, Claude Docs).
A compact pricing snapshot from Anthropic’s model overview:
| Model | Input | Output | Context | Max output |
|---|---|---|---|---|
| Claude Fable 5 | $10 / MTok | $50 / MTok | 1M tokens | 128k |
| Claude Opus 4.8 | $5 / MTok | $25 / MTok | 1M tokens | 128k |
| Claude Sonnet 4.6 | $3 / MTok | $15 / MTok | 1M tokens | 64k |
| Claude Haiku 4.5 | $1 / MTok | $5 / MTok | 200k tokens | 64k |
The wrong takeaway is “always use the strongest model.” The better architecture is model routing.
Use the strongest model for system-level reasoning: dependency discovery, migration planning, unfamiliar frameworks, cross-repo refactors, and failure analysis. Use cheaper models for summarization, simple test generation, documentation cleanup, and mechanical edits. Put deterministic tools around both: compilers, test runners, schema diff tools, SAST, SBOM generation, and policy checks.
Anthropic also says Fable 5 has safeguards that fall back to Claude Opus 4.8 for certain cybersecurity, biology, chemistry, or distillation-related requests, and that early data shows more than 95% of Fable sessions have no fallback (Anthropic). For regulated developers, that is not a footnote. If a workflow touches security remediation, vulnerability analysis, or sensitive research, your agent runtime needs to detect model fallback, log it, and decide whether the resulting output still meets your assurance bar.
Human Review Is the Product, Not the Tax
The phrase “more than 95% Claude-generated code” will get the headlines. The phrase “then reviewed by software engineers” is the part that makes it deployable.
In regulated modernization, review is not a ceremonial pull request approval. It has to answer concrete questions:
- Did behavior change, and where is the test evidence?
- Which data contracts, schemas, APIs, and batch files are touched?
- Does the patch alter authorization, retention, logging, or audit trails?
- Is there a rollback path?
- Can a non-author understand why the change exists six months later?
This is where agent workflows beat loose chat. A good workflow can force every generated patch to carry its own explanation, test plan, risk classification, and affected-system map. It can also block merges when the model did not inspect a dependent service or when generated tests only prove the happy path.
The developer skill shifts from typing every line to designing reviewable work packets. That is still engineering. In many legacy estates, it is the engineering that was missing.
A Small Pattern for Agentic Modernization
If I were building this inside a regulated software team, I would make every modernization task produce four artifacts before code review:
inventory.md: entry points, dependencies, configs, data stores, external contracts.risk.md: business process affected, compliance controls touched, rollback notes.tests/: characterization tests that lock current behavior.patch.diff: the smallest behavior-preserving change.
The model can generate all four. Engineers should review all four. CI should enforce the boring pieces.
For local experiments, Claude Fable 5 is also available as a drop-in Anthropic Messages endpoint through OneHop. OneHop’s Fable 5 page currently lists the endpoint as https://api.onehop.ai/anthropic, the model name as anthropic/claude-fable-5, and a new-account $10 credit with no card required; the displayed promo pricing is $5 input and $25 output per million tokens, which is 30%+ below Anthropic’s $10/$50 list price (OneHop).
from anthropic import Anthropic
client = Anthropic(
base_url="https://api.onehop.ai/anthropic",
api_key="<ONEHOP_KEY>",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Map risks in this legacy migration plan."}],
)Use that kind of endpoint for prototypes and evaluation harnesses. For production regulated workloads, the hard part is still your controls: data handling, retention, access, evidence, model routing, and human sign-off.

The Real Bet: Modernization Becomes Continuous
Most enterprises treat legacy modernization as a once-a-decade program. Big budget. Big SI. Big risk. Then the new platform starts aging on day one.
DXC’s OASIS story points to a better model: modernization as a continuous managed-service workflow. Agents inspect, propose, test, refactor, document, and route work to engineers. Engineers review, constrain, and approve. The platform keeps evidence. The system improves in smaller, safer increments.
That is why this alliance is worth watching. The useful question is not whether Claude can write code. It can. The useful question is whether an organization can turn generated code into governed, reviewable, production-safe change across systems that cannot go down.
DXC is claiming early evidence that this can work at serious scale: 115,000 employees across 70 countries, OASIS in production with more than 50 customers, tens of thousands of Claude-certified forward-deployed engineers planned, and Claude as the default model in OASIS agentic workflows (Anthropic, PRNewswire).
For developers, the move is clear: stop thinking of AI as autocomplete. Start designing agent workflows that leave behind tests, diffs, explanations, and audit trails. That is what legacy modernization has always needed. The model finally makes the paperwork and code motion cheap enough to do continuously.
If you want to test the model-routing side without setting up a full enterprise stack, start with a narrow repo, a characterization-test task, and a Fable 5 endpoint such as Claude Fable 5 on OneHop. Keep the human review gate. Measure accepted diffs, failed tests, review time, rollback quality, and cost per merged change. Then decide if the workflow earned a bigger system.

