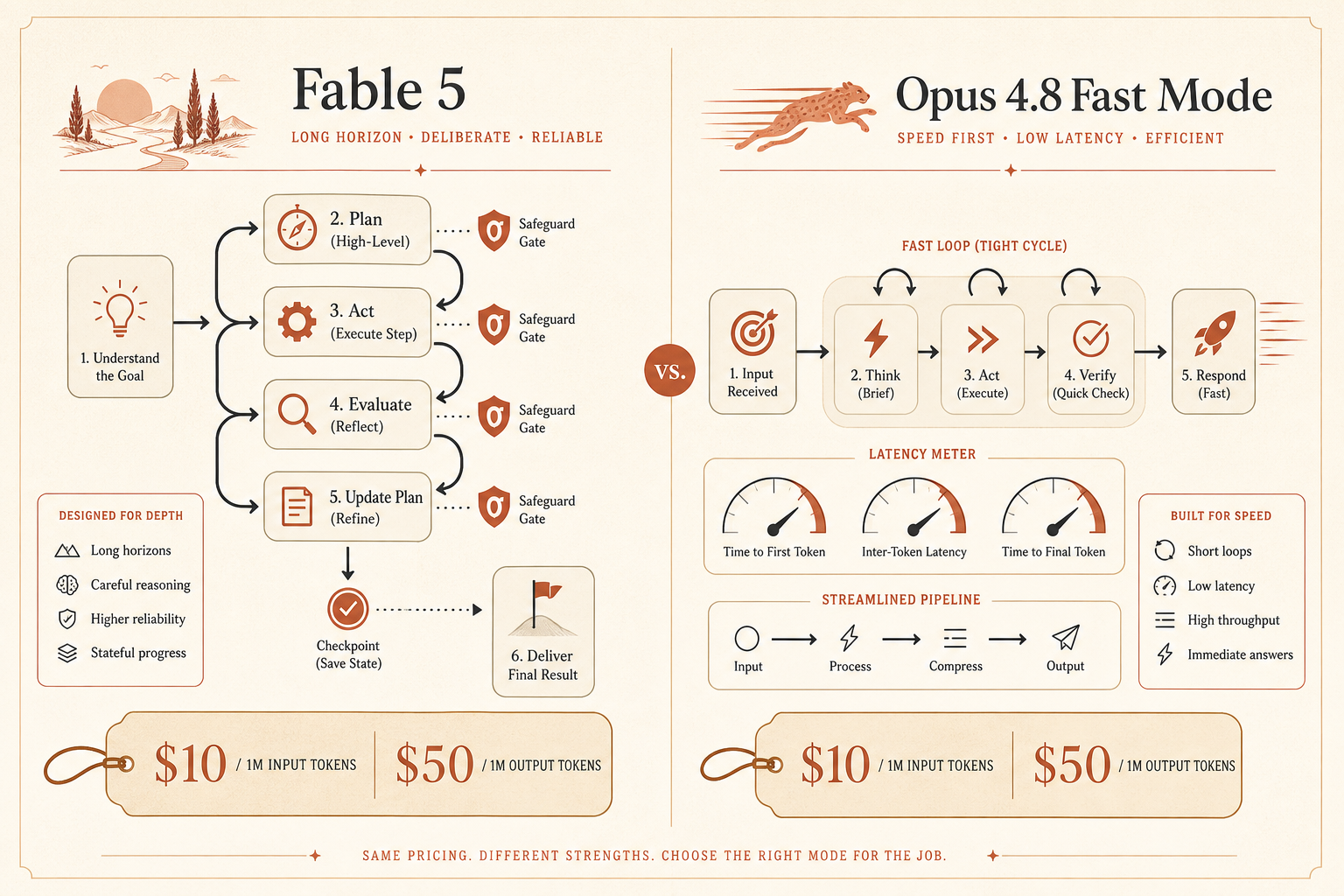
Anthropic accidentally made the cleanest model-selection question of June 2026: if Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens, and Opus 4.8 Fast Mode also costs $10/$50, which one should a developer actually run?
That is not a theoretical spreadsheet exercise. As of June 19, Anthropic’s own Fable page says “Claude Fable 5 is currently unavailable” and lists $10/M input and $50/M output pricing (Anthropic). Claude’s pricing page lists Opus 4.8 at $5/M input and $25/M output, then says Fast Mode gives “up to 2.5x faster speeds” at 2x standard pricing (Claude pricing). Do the math: Opus 4.8 Fast Mode lands at the same token rate as Fable 5.
That makes the decision sharper. Fable is the more ambitious model. Opus 4.8 Fast Mode is the model you can design around when latency matters and access cannot be a maybe.
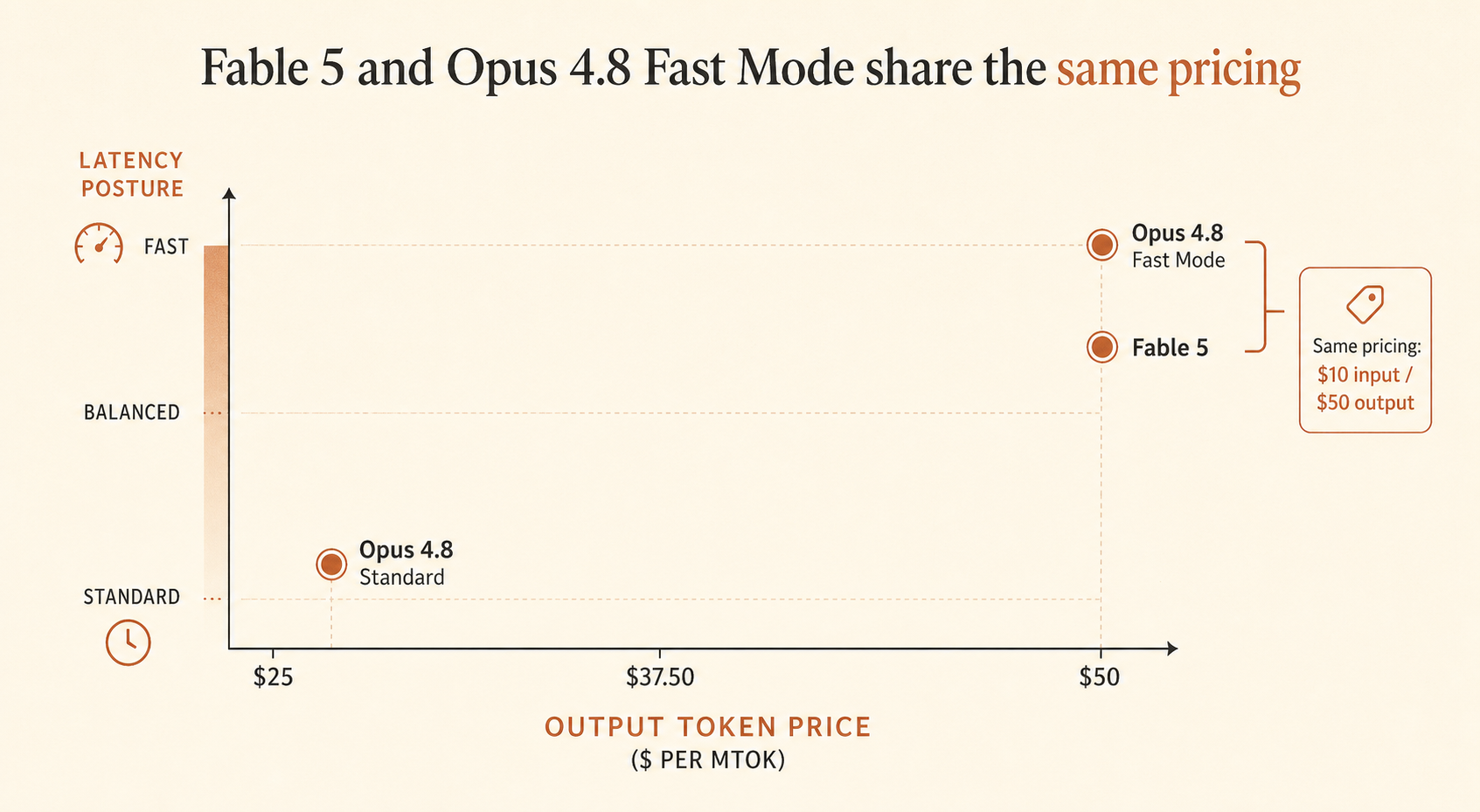
The Price Table That Changes the Choice
Here is the grounded table developers should start with:
| Model | Availability on June 19, 2026 | Input | Output | Context / output | Speed note | Best fit |
|---|---|---|---|---|---|---|
| Claude Fable 5 | Currently unavailable | $10/MTok | $50/MTok | 1M context, up to 128k output | Built for long-running agentic work | Hard, ambiguous, multi-stage projects |
| Claude Opus 4.8 | Available | $5/MTok | $25/MTok | 1M context at standard pricing | Standard speed | Complex coding, enterprise agents |
| Claude Opus 4.8 Fast Mode | Research preview / Claude Code extra usage | $10/MTok | $50/MTok | Same Opus 4.8 rate context rules | Up to 2.5x faster output | Latency-sensitive agent loops |
The Fable specs come from Anthropic’s API docs: Fable 5 has a 1M-token context window by default, supports up to 128k output tokens per request, and is priced at $10/$50 (Claude API docs). The same docs say adaptive thinking is always on for Fable and Mythos, and thinking: {"type": "disabled"} is not supported.
That last bit matters. Fable is not just “Opus but smarter.” It has a different operating profile: more autonomous, more self-checking, often longer-running. Anthropic describes it as built for “ambitious, long-running, asynchronous work” and says it can work for days in agent harnesses (Anthropic Fable page). That is exactly the opposite of what you want if your product depends on tight interactive turns.
Opus 4.8 Fast Mode is the cleaner substitute when the bottleneck is wall-clock time. Anthropic’s Fast Mode page says Opus 4.8 Fast Mode is a high-speed configuration with 2.5x faster output token speeds and “the same Opus-level model intelligence” (Claude Fast Mode). The API pricing docs list Fast Mode Opus 4.8 at $10/M input and $50/M output (Claude API pricing).
Same token price. Different bet.
What the Community Is Actually Arguing About
The Hacker News thread around the Fable launch was less about “is it smart?” and more about how much agency developers want from a model that can take initiative. The launch discussion is worth reading because it frames the core tension: proactivity feels magical when the model fixes the thing you forgot; it feels expensive or dangerous when it decides to broaden scope without permission (Hacker News).
Reddit has been more practical. One r/ClaudeAI benchmark post ran 200 headless claude -p sessions and reported that Fable 5 looked 2–3x more expensive than Opus 4.8 in raw use, even though the list price is exactly 2x. The same post found a surprising steering result: Opus 4.6 scored 88/90 on its instruction-following measure, Fable 5 scored 83/90, and Opus 4.8 scored 80/90 (Reddit). Treat that as one user’s harness, not a universal benchmark, but the pattern matches what many agent builders are seeing: cost is not only the rate card. It is also output length, retries, tool calls, and whether the model over-plans.
Another Reddit comparison across 917 coding-agent scenarios reported Fable 5 at 92.9 overall and about $1.25 per task, versus Opus 4.8 at 92.0 and about $0.74 per task. That is a 0.9-point gain for roughly a 73% task-cost premium in that benchmark (Reddit). The useful part is not the exact score. The useful part is the shape of the trade: Fable may win on hard tasks, but the premium only pays back if those tasks are actually failing or taking too many turns on Opus.
There is also a real operational frustration thread. Fable launched June 9, then Anthropic posted on June 12 that it was suspending access to Fable 5 and Mythos 5 after a US government export-control directive (Anthropic statement). That is why “just wait for Fable” is not a plan if you are shipping a coding agent this week.
Use Opus 4.8 Fast Mode When Latency Is the Product
If you are building an IDE agent, CI repair bot, browser automation tool, or live code-review assistant, latency is not a vanity metric. It changes how users behave.
A slow agent makes developers batch requests, tab away, or stop trusting the loop. A faster agent can ask for confirmation, run a test, patch a file, and stream progress without making the session feel dead. For these workflows, Opus 4.8 Fast Mode is the better default at Fable-equivalent token pricing.
Use Opus 4.8 Fast Mode when:
- The task is interactive. Examples: “fix this failing test,” “explain this stack trace,” “edit this component,” “generate a migration and run it.”
- You already have a good harness. If your agent has repo search, test execution, patch review, and rollback, you may need faster turns more than a more autonomous base model.
- You need predictable routing. Fable’s safety classifiers can decline certain requests, and Anthropic says flagged cybersecurity, biology, chemistry, or distillation requests can route away from Fable to Opus 4.8 (Anthropic launch post). That is sane safety design, but it is another branch in your production path.
- Your agent has user-facing progress deadlines. Fast Mode’s explicit promise is speed. Fable’s promise is ambition.
The killer use case for Opus 4.8 Fast Mode is the agent inner loop:
claude -p "Run the failing test, patch the smallest fix, rerun only that test, and summarize the diff."That job does not need days of autonomy. It needs fast read, edit, test, report. Paying Fable’s price for Opus with faster output is rational there.
Use Fable 5 When the Hard Part Is Steering, Not Speed
Fable is still the model I would want for the messy projects that do not fit into a 90-second coding turn. Anthropic says Fable’s lead grows with longer and more complex tasks, and describes strengths in software engineering, knowledge work, vision, memory, and scientific research (Anthropic launch post). Its docs also say it is built for demanding reasoning and long-horizon agentic work (Claude API docs).
Use Fable 5 when:
- You can run asynchronously. Queue the job, stream status, let it work.
- The task has unclear decomposition. Examples: large migration, multi-repo refactor, design-to-implementation, benchmark investigation, research synthesis.
- You want the model to verify its own work. Fable’s positioning is more “senior agent” than “fast assistant.”
- Fewer turns are worth more than faster turns. If Fable saves three human steering rounds, the same $10/$50 token rate as Opus Fast can become cheap.
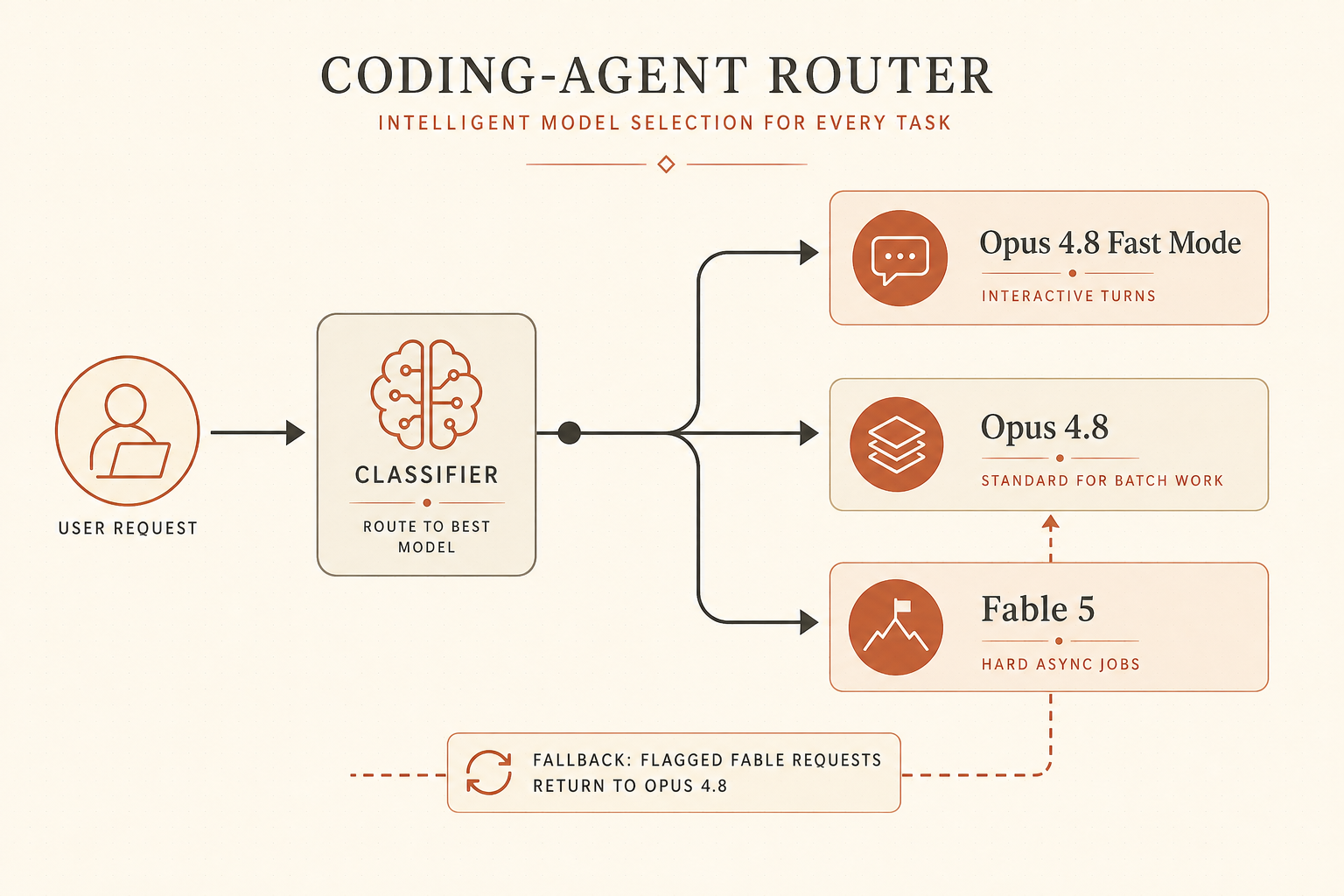
The catch is access. Anthropic’s current public pages say Fable is unavailable. The clean fallback architecture is to make Fable an optional top-tier route, not the only route:
interactive task -> Opus 4.8 Fast Mode
routine batch task -> Opus 4.8 standard or Sonnet
hard async task -> Fable 5 when available
flagged / refused Fable request -> Opus 4.8 fallbackThis is also where OneHop fits naturally. If your blocker is trying Fable without rebuilding your provider layer, OneHop lists anthropic/claude-fable-5 as a model endpoint, marks it temporarily unavailable, and shows $10 free credit for new accounts with no card required (OneHop). The page I checked lists Anthropic Messages support at https://api.onehop.ai/anthropic and shows discounted pricing against the official $10/$50 list.
from anthropic import Anthropic
client = Anthropic(
base_url="https://api.onehop.ai/anthropic",
api_key="<ONEHOP_KEY>",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Plan a safe, staged migration from Jest to Vitest."}],
)
print(message.content[0].text)If your integration is OpenAI-compatible and your OneHop account is configured for the /v1 gateway, the migration pattern is the same idea: change the base URL to https://api.onehop.ai/v1, keep model routing outside your business logic, and swap model IDs through config. For Fable specifically, verify the supported protocol on the live OneHop model page before deploying.
The Recommendation
Do not replace Opus 4.8 with Fable 5 globally. That is the expensive, fragile version of the migration.
For latency-sensitive coding agents, use Opus 4.8 Fast Mode as the Fable-priced substitute. It has the same token price, the speed promise is explicit, and it avoids depending on a model that is currently unavailable. Add Fable 5 as an async escalation path when access returns.
For long-running autonomous work, wait for Fable access or test it through a provider route once it is live. The case for Fable is not “same price as Opus Fast.” The case is “fewer steering turns on work Opus still struggles to complete.” If your tasks are already solved by Opus 4.8, Fast Mode buys a better user experience. If your tasks are failing because the model will not hold the whole plan, Fable is the one worth paying for.
My default routing rule is simple:
- Ship with Opus 4.8 Fast Mode for live coding loops.
- Keep Opus 4.8 standard for cost-controlled background jobs.
- Route only the hardest async tasks to Fable 5 when it is available.
- Measure task cost, not token price.
If you want a low-friction way to test that routing, start with Claude Fable 5 on OneHop, then start with $10 free. The point is not to worship a frontier model. The point is to stop hardcoding model choices into your agent and make the trade-off explicit.

