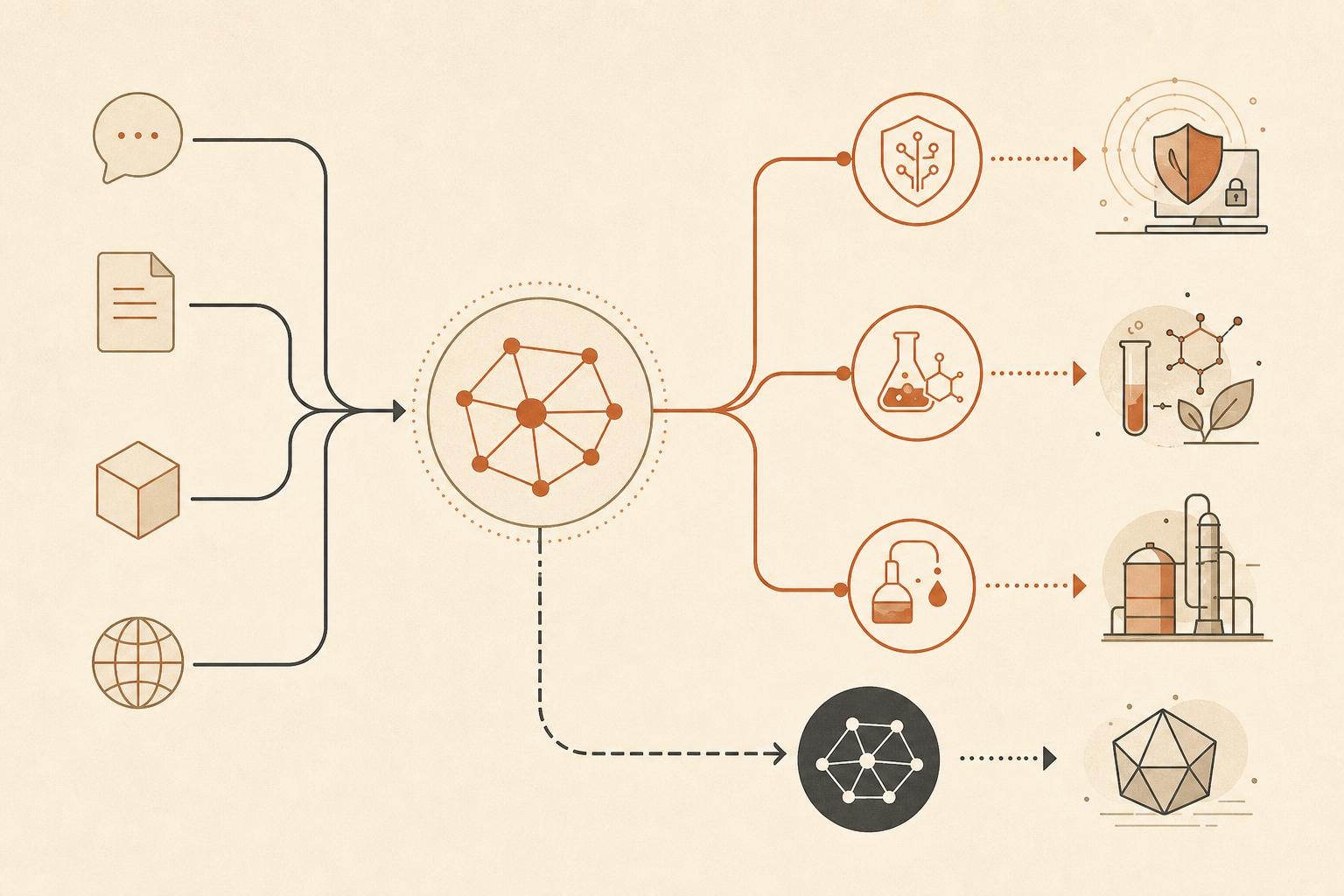
Claude Fable 5 is generally available as of June 9, 2026, but it does not answer every request you send it. Anthropic says some requests flagged by new safeguards in cybersecurity, biology and chemistry, or distillation are automatically handled by Claude Opus 4.8 instead, and early data shows more than 95% of Fable sessions involve no fallback at all (Anthropic).
That one implementation detail matters more than the launch headline. If you are debugging an agent, running evals, or comparing model quality, “I called Fable 5” is no longer always the same as “Fable 5 answered.” Sometimes the product surface, or your API integration if you configure it, will route the request to Opus 4.8.
What Anthropic Actually Shipped
Anthropic launched two related models on June 9: Claude Fable 5 and Claude Mythos 5. Fable 5 is the generally available version. Mythos 5 is restricted, initially for Project Glasswing partners and later for selected trusted-access programs (Anthropic).
The company describes Fable 5 as a “Mythos-class” model made safe for general use. Its product page positions it for long-running coding, agentic work, enterprise workflows, and vision-heavy document tasks (Anthropic). The API docs list claude-fable-5 as Anthropic’s most capable widely released model, with a 1M token context window, 128k max output, adaptive thinking always on, and pricing of $10 per million input tokens and $50 per million output tokens (Claude API docs).
Here is the compact model picture developers need:
| Model | API ID | Availability | Context | Max output | Price per 1M tokens |
|---|---|---|---|---|---|
| Claude Fable 5 | claude-fable-5 | Generally available | 1M | 128k | $10 input / $50 output |
| Claude Mythos 5 | claude-mythos-5 | Limited, Project Glasswing and trusted access | 1M | 128k | $10 input / $50 output |
| Claude Opus 4.8 | claude-opus-4-8 | Generally available | 1M on Claude API, Bedrock, Vertex AI | 128k | $5 input / $25 output |
The important split is not just capability. It is policy surface. Fable 5 is the public model with additional safeguards. Mythos 5 is the same underlying model with some safeguards lifted for approved users, according to Anthropic’s launch post (Anthropic).
The Fallback Path
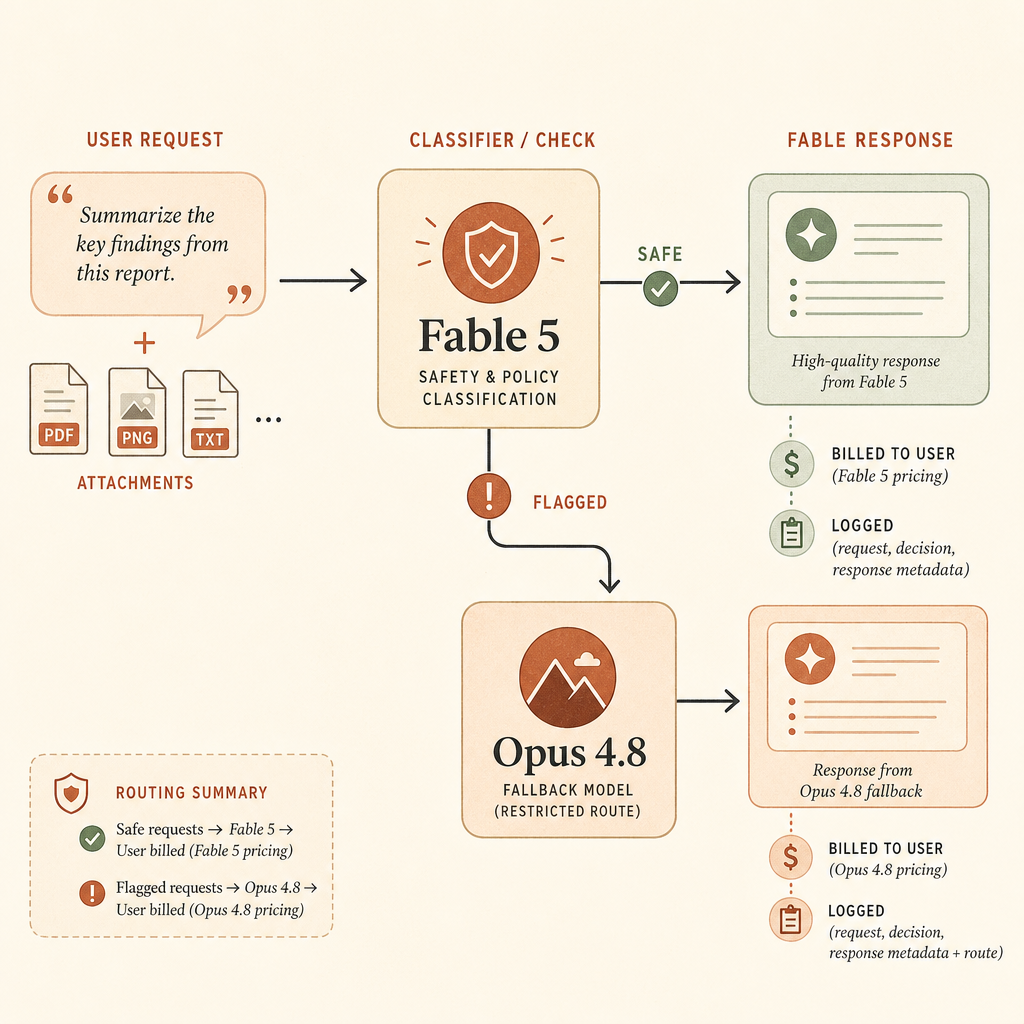
Anthropic says Fable 5 uses a new set of classifiers, separate AI systems that detect potential misuse and jailbreak attempts. When those classifiers detect a request related to cybersecurity, biology and chemistry, or distillation, the response is automatically handled by Claude Opus 4.8 instead (Anthropic).
The Help Center gives a more product-level version of the same behavior. Fable 5 runs automated safety checks on every request. These checks are intended to block areas including offensive cybersecurity techniques, biology and life sciences queries, extraction of summarized thinking, and a narrow set of frontier LLM development tasks such as distributed training infrastructure and some accelerator or kernel work (Claude Help Center).
That page also says the checks review more than the latest message. Memory, connector content, web results, and files can all trigger a block. This is a debugging trap. A user may ask a harmless follow-up, but a previous pasted exploit writeup, lab protocol, or model-training note in the conversation can trip the classifier.
On Claude’s consumer and workspace surfaces, automatic switching is enabled by default when Fable 5 is selected. If a turn is switched, the user sees a notice and the answer is labeled with the model that responded. After the switch, the model picker stays on Opus 4.8 for the rest of that conversation unless the user switches back (Claude Help Center).
Why Developers Will Notice
The fallback creates a new class of “model behavior” bugs.
First, evals can become mixed-model evals. If your test set includes vulnerability analysis, security hardening, synthetic biology, chemistry, medical research, or model distillation prompts, some rows may be answered by Opus 4.8. If your harness records only the requested model, you will misattribute the result.
Second, agent traces can look inconsistent. Fable 5 may handle planning, code edits, and refactors, then Opus 4.8 may answer a flagged security review turn. If the agent uses subagents, every subagent call needs its own fallback configuration in the API. Anthropic’s cookbook warns there is no account-level or session-level switch for API fallback. Each request must include the fallback setting (Claude Cookbook).
Third, billing needs closer instrumentation. Anthropic’s Help Center says a request blocked before Fable produces output is charged only at Opus rates. If a request is blocked midstream, input and already-streamed tokens are charged at Fable rates, while the rest is charged at Opus rates (Claude Help Center).
For API users, the server-side fallback path looks like this:
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: server-side-fallback-2026-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-fable-5",
"max_tokens": 1024,
"fallbacks": [{ "model": "claude-opus-4-8" }],
"messages": [{ "role": "user", "content": "Hello, world" }]
}'The real production advice: log both requested_model and response_model. Also log stop reasons, fallback categories when exposed, whether the response was streamed, and whether a subagent or retry path built the request.
Safety-Sensitive Workflows Need Separate Evals
Fable 5 may be the right default for long-horizon coding and knowledge work. It is not automatically the right default for every workflow that mentions security, biology, chemistry, healthcare, or model training.
Anthropic is explicit that the safeguards are conservative and may catch harmless requests. The launch post says the company tuned them this way to release the model “both safely and quickly,” and that false positives are expected while Anthropic works to narrow them (Anthropic). The Help Center gives examples of legitimate work that may be blocked, including authorized security testing, benign biology research, biotech business documentation, medical imaging and diagnostics, clinical questions, and basic biology education (Claude Help Center).
That means your eval suite should split into at least three buckets:
- Normal product traffic where Fable should answer directly.
- Dual-use or sensitive traffic where fallback is expected and acceptable.
- False-positive probes where the request is benign but likely to touch classifier boundaries.
Do not average those together and call it “Fable 5 quality.” For each bucket, track answer quality, fallback rate, latency, refusal rate, cost, and user-visible messaging. If you run a support bot for biotech customers, a 3% fallback rate may be normal. If you run a coding assistant for front-end migrations, 3% might mean your prompt templates are accidentally dragging security or model-extraction language into context.

The Retention Change Is Part of the Story
Fable 5 also ships with a data-retention change for some business customers. Anthropic says prompts and outputs for Mythos-class models are retained for 30 days for trust and safety purposes on every platform where those models are offered, effective June 9, 2026 (Claude Help Center).
This matters most for organizations that previously used zero data retention. Anthropic says the change applies to ZDR workspaces in Claude Console, Claude Code with ZDR in Claude Enterprise, and access through AWS Bedrock, Google Cloud Agent Platform, or Microsoft Foundry with ZDR. Other models are unaffected by this specific policy (Claude Help Center).
For developers, this becomes an architecture question, not a legal footnote. You may need a separate workspace, a sandbox org, or a provider-specific retention configuration before Fable 5 can enter a production path. If your data classification rules forbid 30-day retention, use another model until your security and legal teams approve the setup.
When Fable 5 Is the Right Model
Use Fable 5 when the task benefits from persistence, long context, and high autonomy: large migrations, multi-step refactors, complex document reasoning, vision-heavy analysis, or agents that need to plan and test their own work. Anthropic’s own positioning points at “days-long” and asynchronous tasks rather than cheap high-volume completions (Anthropic).
Be more careful when the task lives near a classifier boundary. Security copilots, biology research assistants, chemistry search tools, model-training platforms, and eval harnesses should treat fallback as an expected state. Build the UI and logs so users can see which model answered. Build tests so regressions show up as “fallback rate changed,” not as mysterious quality drift.
The launch is still a big deal. Anthropic has made a Mythos-class model generally available, with public pricing, API access, and a documented fallback path. But for developers, the operational takeaway is simple: Fable 5 is a routed system. If you ship it like a single static model, your traces, evals, and bills will eventually disagree with reality.
If you want to try Claude Fable 5 yourself, you can use Claude Fable 5 on OneHop through a drop-in endpoint, around 30% under list price. New accounts can start with $10 free, no card required.
Further reading: Getting started with Claude Fable 5.

